

























テクノロジー・リーダーシップ
AIプロセッサーの動向とそのソフトウェアの将来を予測
2019年10月18日
カテゴリー AI | テクノロジー・リーダーシップ
記事をシェアする:

著者:小原 盛幹
IBM東京基礎研究所、コマーシャル・システムズ担当、IBMアカデミー会員、TEC-J バイスプレジデント
現在「AI Hardware Ecosystem」のIBM Research グローバル・リーダーとして、AIハードウェアのためのソフトウェア・エコシステムについて研究中。いま注目のAI用プロセッサーについて、今後の動向からソフトウェアの将来を大胆に予測します。
なぜAIに新しいプロセッサーが必要なのか?
AIは最近、最も注目されている計算処理として、日進月歩でより高度な処理が可能になってきました。映像から物体を特定する物体認証や、オンライン・ショッピングでのお勧め機能などは、頻繁に使われるAIの機能ではないでしょうか?これは近年AIの技術の発達として、深層学習と呼ばれる技術の発展によるもので、生物の脳神経細胞の動作をもとにした計算モデルを採用しています。
 AIの進歩により、ある特定のタスクについては、人間の能力を超える例も出てきました。クイズ番組で人間のチャンピオンよりもAIが高い点数を獲得したり、人間とAIが囲碁の対局でAIが勝った例が挙げられます。これらは、特定タスクでのAIの優位性を示しているのに過ぎないのですが、いずれ、AIが人間の知能を超える時期が来るとも言われています。
AIの進歩により、ある特定のタスクについては、人間の能力を超える例も出てきました。クイズ番組で人間のチャンピオンよりもAIが高い点数を獲得したり、人間とAIが囲碁の対局でAIが勝った例が挙げられます。これらは、特定タスクでのAIの優位性を示しているのに過ぎないのですが、いずれ、AIが人間の知能を超える時期が来るとも言われています。
これには賛否両論がありますが、一つ分かっていることがあります。それは、現在の半導体によるコンピューターは、生体の脳に比べると途方もなくエネルギー効率において劣り、一説によると、1,000倍以上のギャップがあると言われています。つまり、人間の知能に匹敵するAIができたとしても、その実行には莫大な電力が必要になり、実用にならない可能性があるということです。
半導体においては、微細加工技術が進歩することにより、トランジスタの面積が年々小さくなってきました。一般的に、トランジスタの面積が小さくなるとそのエネルギー効率がよくなります。このため、年々トランジスタ当たりのエネルギー効率もよくなる傾向が続いてきました。しかしながら、ムーアの法則の終焉と言われている、長年続いた微細加工技術の進歩のペースが落ちてきた影響で、このエネルギー効率の改善もペースが落ちてきました。このため、半導体技術の発達のみによって、生体の脳と半導体によるAIとのエネルギー効率のギャップを埋めることは困難であると予想されます。
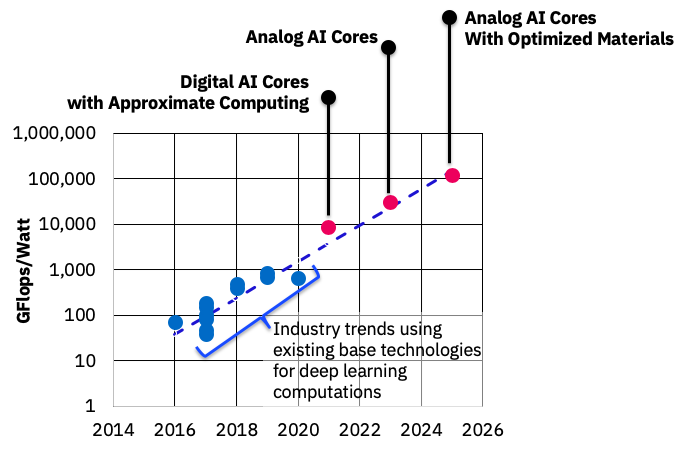
人間の知能に匹敵しないまでも、AIの需要は年々増大し、計算もより複雑になってきています。このため、プロセッサー・アーキテクチャーを改良することにより、AIを高速化・低消費電力化する研究開発が世界中で活発に行われています。IBM基礎研究所でも、以下の図の通り、2025年ごろまでに電力当たりの処理能力を100倍程度向上させるロードマップを基に研究開発を行なっています。
ソフトウェアはどうする?
今後しばらくは、AI向けに最適化されたAIプロセッサーの進化は続くと予想されますが、そこで動くソフトウェアはどうなるのでしょうか?最近のAIソフトウェアの研究開発の多くは、AIフレームワークと呼ばれるミドルウェアを前提にしていることが多いと言えます。
例えば、TensorFlow、PyTorch、ONNX などが有名です。これらは、深層学習を実現する計算、すなわちニューラル・ネットワークを設計し、正解データを使って学習させ、推論(例えば、物体認識なら物体の識別)の実行を容易にしてくれます。
さらに、深層学習の計算を高速に実行できる形式のプログラムに変換することができます。特に、学習は多くの正解データで繰り返し実行する必要があるため、莫大な計算量が必要です。元々はパソコンの画面描画を高速に行うために作られたグラフィックス用プロセッサー、GPUを使って学習を行うこともよく行われます。これは、画像描画と深層学習で共通の計算要素があり、GPUは深層学習の計算を通常のCPUより高速に実行できるためです。
しかしながら、新たに出てくるAI用プロセッサーは、従来のCPUやGPUと互換性がなく、今までのプログラムはそのままでは実行できません。特に、AI用プロセッサーが進化してくると、従来のCPUやGPUとの乖離が大きくなり、ソフトウェア資産に相当する、既存のAIフレームワークや学習済みの深層学習モデルを実行するには大きな労力と時間がかかる可能性も出てきます。これでは、ソフトウェア資産がハードウェアの進歩を妨げてしまいます。
通常のプロセッサーとそのソフトウェアの歴史を振り返ると、ハードウェアとソフトウェアの進歩を支えてきた技術としては、言語処理系の役割が大きいと思います。よく知られている例が「Write once, run anywhere:一度書けばどこでも走る」を標語として掲げたJava言語があります。これはJava Virtual Machine (JVM)と呼ばれるJavaの言語処理系を各プロセッサーごとに実装しておけば、Java言語で一度プログラムを書くと、どのプロセッサーでも実行できるという意味です。すなわち、プロセッサーが進化しても、JVMがその進化に追随していれば、今までのソフトウェア資産は新しいプロセッサーでも活用できることが期待されます。
さらに、Javaという単一の言語だけでなく、複数のプログラミング言語に対して複数のプロセッサーで動作することを容易にする、言語処理系フレームワークもあります。代表的な例には、LLVMがあげられます。LLVMを使った言語処理系は通常、ソース・プログラムをLLVM中間表現という、プログラミング言語に依存しない形式に変換しそれをプロセッサーに依存しない最適化や変換を行い、最後にプロセッサーに依存した最適化や実行可能コードの生成を行います。
新しいプロセッサーを作った場合、最後のプロセッサーに依存した部分のみ作成すれば、LLVMで処理できるプログラミング言語で書かれたプログラムを、新しいプロセッサーで動作させるめどがつきます。例えば、Apple社が開発したモバイル用プログラミング言語Swiftの言語処理系はLLVMを採用しています。LLVMは多くのプロセッサーに対応しているため、モバイルだけでなく、パソコンからメインフレームなど、幅広いシステムでSwiftプログラムを走らせることができます。
LLVMはオープンソースであるため、開発は閉じた企業や組織に縛られず多くの人が開発に参加可能です。新しいプログラミング言語やプロセッサーでLLVMを活用したい場合、その追加を希望する企業や組織がLLVMの開発に参加することが可能で、言語処理系をゼロから開発する必要がありません。
今後の展望
AIフレームワークやAIプロセッサーはまだ歴史が浅く、LLVMに相当する言語処理系が存在していません。しかしながら、似た動きはあります。一つはONNXです。AIには、主に、学習とその結果を使った推論の2つの処理があります。ONNXはONNX formatという標準の学習モデルのフォーマットを定義し、他の複数のAIフレームワークで学習した学習モデルからONNX formatに変換することで、それらのモデルを使った推論を実行することができます。すなわち、AIプロセッサーで実行できるコードをONNXが生成できるように拡張すれば、複数のAIフレームワークで学習されたモデルからの推論をそのプロセッサーで行えることになります。
さらに、このブログを執筆中に大きな動きがありました。LLVMの開発コミュニティに対して、マルチレベル・インターミディエイト・リプリゼンテーション(MLIR)を導入する提案が出ました。AIの言語処理系は、ニューラル・ネットワークから実際にプロセッサーで実行可能なコードに変換する過程で、ネットワーク構造の変換、最適化を繰り返し行い、入力である必要な計算を抽象的に記述したグラフ構造をプロセッサーで実際に実行する具体的なコード列に変換していきます。すなわちこの過程で、計算を示すデータ構造の抽象度を段階的に下げていきます。
MLIRの「マルチレベル」は、このような異なる抽象度の計算表現を扱うことを意図したものです。MLIRがLLVMに導入されると、究極的には、複数のAIフレームワークがMLIRを使って実装され、MLIRという共通の表現の上で、複数のAIプロセッサーに最適されたコード生成することが夢物語ではなくなってきます。
こうなると、LLVMが複数AIフレームワークと複数AIプロセッサーを結びつけるハブの役割を果たすことになり、AIフレームワークとAIプロセッサーの発展を加速することが期待されます。AIプロセッサーやその言語処理系はまだまだ発展途上であり、LLVMのオープンソースとしての開発モデルと相まって、今後の一層のイノベーションが期待されます。

これからのプログラミングを助けるAI
2021年12月6日から14日まで、機械学習(AI)のトップ国際学会のひとつである Conference on Neural Information Processing Systems(略称:NeurIPS)が開催され […]

ラボの枠を超えて:IBMリサーチ、企業のためにAIの進歩のパイプラインを強化
AIによる自然言語処理には、技術的にまだまだ多くの課題があります。文法や綴りなどの言語的なルールは必ずしも規則的であるわけではなく、言語が異なれば、ルールも異なります。また、ある程度ルールがわかりやすい言語においても、地 […]

なぜ第一生命は「AI活用」に踏み込んだのか?コンタクトセンターの“大改革”の舞台裏
このエントリーをはてなブックマークに追加 第一生命は、コールセンターの業務改善に向けてIBM Watsonを採用。AIコンタクトセンター支援システムを導入した事例と将来の展望について語ります。 ※この記事は2019年8月 […]