

























テクノロジー・リーダーシップ
事例で理解する、ビッグデータの活用におけるデータモデリングの必要性
2018年11月26日
カテゴリー テクノロジー・リーダーシップ
記事をシェアする:

著者:奥井 敦子
IBM認定上席ITスペシャリスト 日本IBM グループにおける情報技術の専門家集団である日本IBMシステムズ・エンジニアリング株式会社に所属
ホスト、分散、ビッグデータ等のデータベースのモデリング、設計、構築、チューニング等のサービスを数多くのお客様に提供。サポート領域は、大量のトランザクションを扱う基幹業務から、巨大データを扱うビッグデータ活用までと幅広く、製品やソリューションも日々アップデートされているが、基本的な考え方は共通する部分が多いと考えている。このブログでは、製品の特性を理解しビッグデータの実測値をもとに適切なデータモデリングの方法を解説します。
ビッグデータはそのサイズが従来とは比較にならない程大きい事もあり、データモデリングのやり方によって、その性能は大きく変動する。一方ビッグデータを扱うミドルウェア(DWHアプライアンスを含む)は、複数ノードによる分散処理を前提としている為、通常のRDBよりも高性能が期待できる事もあり、データモデリングをあまり意識しないケースも散見されます。
しかし、Analytics製品の中にはデータの抽出、加工、分析処理をSQLに変換し、データベース側に当該処理を実行させるものもある。この様な機能を使用する場合は、テーブルの構造次第でデータベース側で実行されるSQLおよび処理時間が変化するため、データモデリングは重要な考慮事項となる。今回はビッグデータを扱うRDBとしてPureData System for Analytics以下、PDA(現在のIIAS)を例に解説。
ビッグデータ(RDB)のデータモデリングを実施しようとしている方は是非参考にしていただきたい。尚以下の実測では金融業界のキャッシュフロー分析の社内検証結果のデータを元にしています。
データモデルによる処理時間の違い(実測例)
グラフ1は、512列(A表)の表と、22列(B表)の表に対して、次の(1),(2)の処理(同じSQL文)を実行した場合の違いです。
- 95億件に対して、比較的簡易なNULL値を0で置き換えの更新 (対象6列)
- 20億件に対して、演算処理を含む更新(対象6列)、JOINあり
いずれも、22列の表の方が大幅に処理時間が短縮されている。また、(1)の単純な処理の方が、(2)の演算処理よりも、データ容量における影響をダイレクトにうけているのが読み取れます。
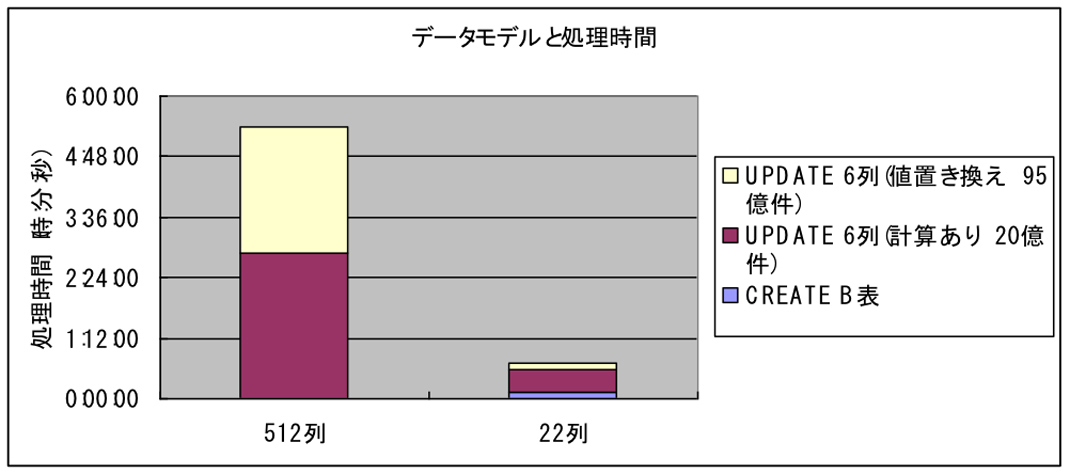
グラフ1 測定環境:N2001-10 PureData System for Analytics(測定結果はモデルにより変動します)
JOINあり/なしでの処理時間の違い(実測例)
大型の表同士のJOINの場合は、2つの表の突合せ処理のオーバーヘッドが大きい為、JOINありの方がオーバーヘッドがあります。
グラフ2は、同じ処理(大量更新処理 512列)を、1つの表から読み込んで実施した場合(JOINなし)と、2つの表から読み込んで実施した場合の違いを表しています。
- JOINなし
512列SELECT、計算あり(1表)96億件+512列INSERT(1表)48億件 - JOINあり
512列SELECT、計算あり(2表)96億件+512列INSERT(1表) 48億件
これらの処理は、大容量更新を伴うものであり、読み込み処理と更新の処理の割合により、JOINのオーバーヘッドの大きさは変動する。
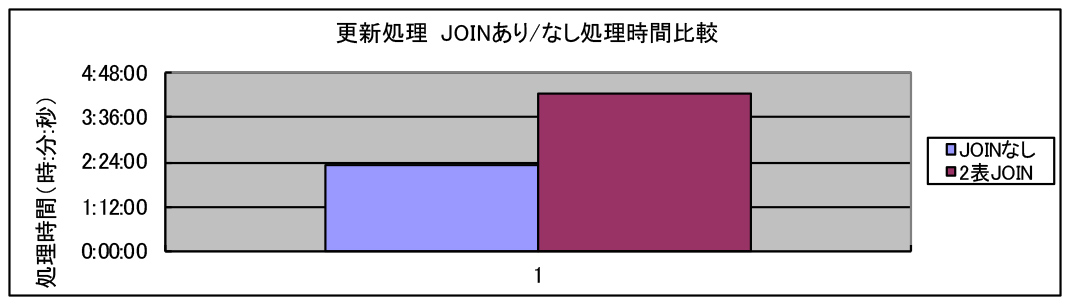
グラフ2 測定環境:N2001-10 PureData System for Analytics(測定結果はモデルにより変動します)
小さなマスター表の場合
一方小さなマスター表については、以下の様に各々のノードに飛ばすブロードキャストJOINの方式がとられる為、ほとんどオーバーヘッドが無い(図1)
- 3600件程度の表とJOINしてSELECT/INSERTしたが、単表からSELECT/INSERTするのと処理時間は変わらなかった
- 小さな表であれば内部的にブロードキャストJOINが実行される(小さなマスター表については、自動的PDAが各ノード「DataSlice」に飛ばしてJOINを実行する)
- 表の大きさが20~30MB以内であればJOINしても処理時間にインパクトを与えない
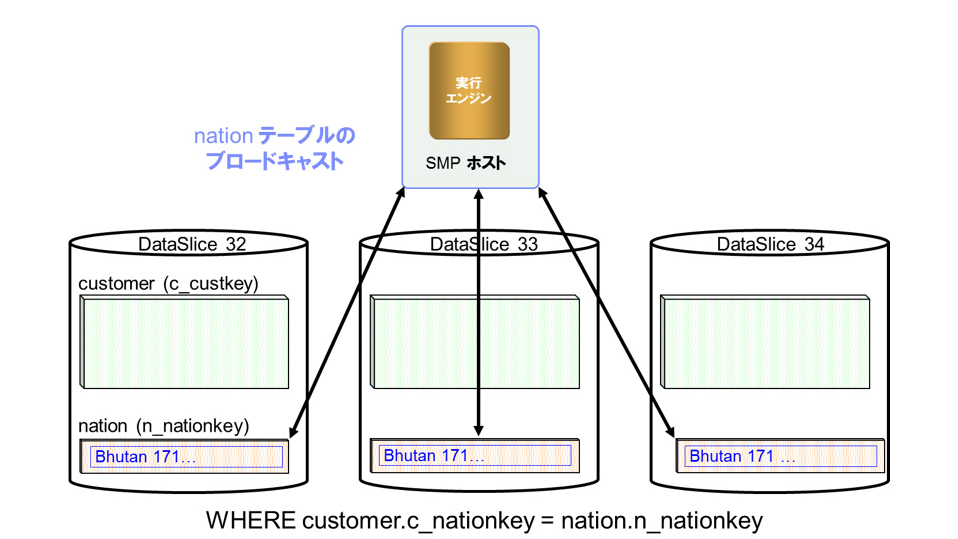
図1
推奨されるPDAのデータモデリングのポイント
PDAにおけるデータモデリングについては、以下が推奨されます。
- 特に更新についてはデータ容量(行長×処理件数)に処理時間が影響を受ける為、データ容量を削減できるモデルが望ましい
- データサイズが同じ場合は、TallモデルであってもPDAでは性能に影響は出ない為データサイズが小さくなるモデルが望ましい(一般にRDBのTallモデルではFETCHの件数が多いのでCPU時間が長くなる影響がある)

- 行長は短い方が1件あたりの性能が良い為、余計な列は所持しない事(PDAでは更新は、列単位ではなくレコード単位。DELETE+INSERT)
- その為、例えば繰り返しフィールドは外出しにしたり等、正規化が推奨される
一方複数表のJOINに関して以下の考慮点もあります。
- 数万件(数10MB以内)の小さなマスター表(コード表や名称表等)については、JOINしても性能上問題が無いため、切り出す
- ただし、1000万件を超える表(数GB~)についてはJOINする表の数に考慮が必要
- 性能は単表の場合に比べて劣化するので、注意が必要(JOIN結果サンプルを参照)
- JOINするそれぞれの表から読み出す件数(アンサーセット)が多く、行長が長い場合には一時表スペース等のサイズにも留意が必要
今までご紹介した点を踏まえて、実際に筆者がユーザーのプロジェクトでデータモデリングを実施した際の手順のポイントは以下の通りです。
データモデリング手順例
1.フラットファイル(ホストや基幹システム)から転送される形式
フラットファイル(ホストや基幹システム)から転送される形式をそのままDBにする方法は単純であるが、列数が多く、データの冗長性も高く、DISK容量も多くなり、処理時間が長い。また非定型検索に適した形にならない場合が多い。
2.表を正規化する
データの冗長性を廃し、DISK容量を減らすことと、それに伴う処理時間を減らすという側面からも正規化を行う(性能や保守性等の非機能要件)。この中でデータの縦もち/横もち等も検討していく。
同時に、機能要件、分析要件に対する充足度を考慮する。
その際に考慮すべきポイントは、以下の通りである。
- 最大列数の制限・・・DBMSにより異なる
- DISK容量
- 処理時間
- 検索、集約(GROUP BY)や集計処理の要件
- ファイルから加工して表に格納する際の加工処理
3.表の非正規化を行う
正規化したモデルから、以下を考慮して表の非正規化(統合化)を行います。
- 一緒に使用される度合い
- JOINする表の数と性能
一般に非定型検索等では、正規化した複数の表を一緒に使用する事が多い。この場合、大容量の表を多数JOINすると大幅に性能が劣化したり、一時表がパンクして実行ができなくなるケースがあるので非正規化を実施します。
また同時に、集約処理や非定型検索要件を充たすかどうかの検討も併せて行います。
4.非正規化項目についての考慮
以下を考慮の上、重複項目の所持を検討します。
- 非正規化項目を複数表に所持する事によるデータ容量の増加
- 項目を非正規化しない場合に、大容量の表のJOINの数が増える事による性能のオーバーヘッド
- 集約や、一緒に使用される頻度
まとめ
ビッグデータの実測例を元に、より性能が出せる様にデータモデリングを行うための方法について解説しました。通常のRDBと共通の考え方の部分もありますが、少し異なる箇所もあります。製品の特性を理解し、適切にデータモデリングを行えば、より性能の良いシステムを構築可能となります。
女性技術者がしなやかに活躍できる社会を目指して 〜IBMフェロー浅川智恵子さんインタビュー
ジェンダー・インクルージョン施策と日本の現状 2022年(令和4年)4⽉から改正⼥性活躍推進法が全⾯施⾏され、一般事業主⾏動計画の策定や情報公表の義務が、常時雇用する労働者数が301人以上の事業主から101人以上の事業主 […]

賞金付き量子コンテスト「Open Science Prize 2022」の発表
今年のIBM QuantumのOpen Science Prizeの課題は、量子状態の準備です。 IBM Quantumは今年、3年目となるOpen Science Prizeを発表します。このコンテストは、量子コンピュ […]

The best of IBM Japan 2022
「The best of IBM Japan 2021」に引き続き、「日本」「日本人」という視点で選んだ2022年の日本IBMの10のトピックを紹介する「The best of IBM Japan 2022」を公開します […]