ITコラム
AI時代に求められるクラウド分析基盤と統合データ・プラットフォーム(前編:データの整備)
記事をシェアする:
AIを導入し競争力を強化する動きが加速し、AI活用となるデータの在り方が企業の競争力に直結する状況となっています。しかし多くの企業では、データが散在している、知見をどのように得るのか分からないなど、データ活用における課題・障壁があります。
このブログでは、データを企業で最大限に活用するための、データ管理からAI/機械学習の業務活用までを統合的にサポートするプラットフォームの要件を改めて整理するというデータの在り方について解説します。
そしてその後の、データから価値を引き出すための後編:2つのソリューション「Watson Studio」と「IBM Cloud Private for Data(以下、ICP for Data)」の最新情報について解説はこちら
1. データ活用の取り組みの変遷
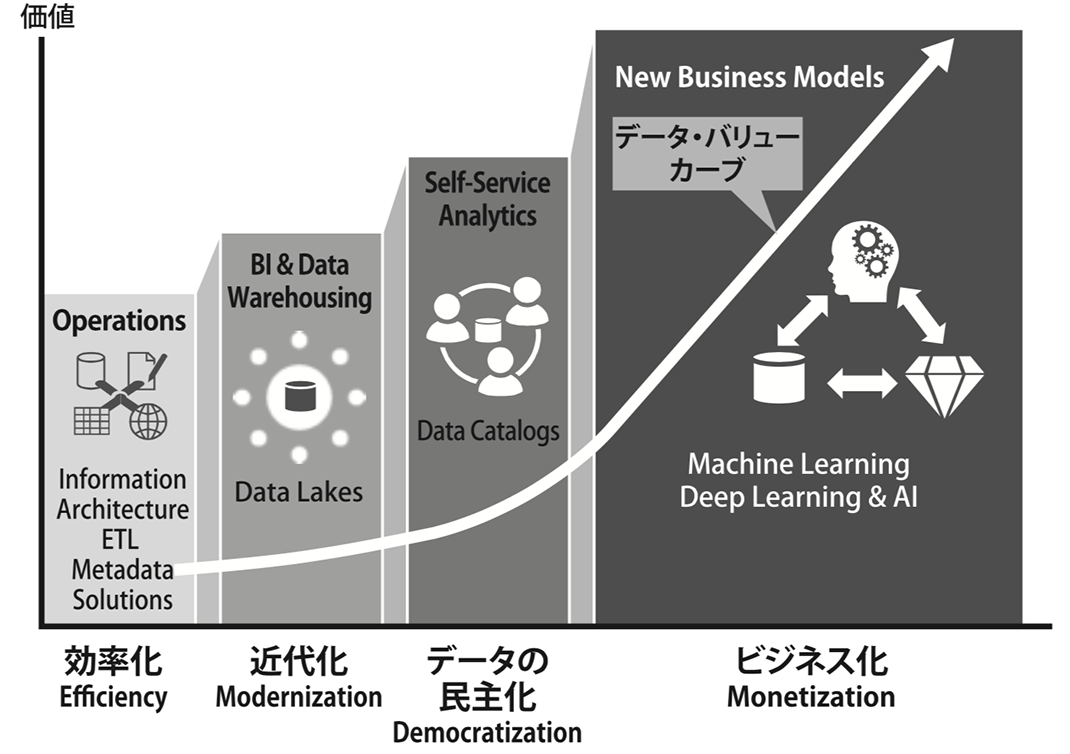
図1. データ活用の取り組みの変遷
これまでは業務処理の単なる記録であったデータが、現在は企業内で共有されることで活用の場が広がり、データは企業の第4の資産と考えられるようになっています。
さらにデータとAIとの融合を行うことで、新たなビジネス・モデルや企業価値の創出につなげる取り組みが加速しています(図1)。
図1. データ活用の取り組みの変遷多くの企業がAI活用によってビジネス・モデル変革を進め、そのベースとなるデータ活用に注力する一方で、世の中の80%の時間がデータの検索に費やされています[*1]。
[*1]FROM DATA TO DISRUPTION: INNOVATION THROUGH DIGITAL INTELLIGENCE: IBM-sponsored report by Harvard Business Review Analytic Services, 2016,
利用するためのデータ自体が手に入らない、手に入ってもデータの整備がうまくいかない、ユーザーのデータ活用がうまく進まないなどの課題が明らかになってきています。そこで、データから価値を引き出してビジネスの差別化に生かすためには、どのようなデータ活用プラットフォームが求められるのかを考察していきます。
2. AI-Readyなデータ・プラットフォームの要件
ビッグデータやAI活用など、昨今のデータ要件の変化に対応するためのデータ・プラットフォームに必要な要件を、機能的側面と非機能的側面から整理します。
2-1. データ活用のステップとプラットフォームの機能要件
データからうまく価値を引き出すためのデータ活用のステップを、「データ整備」「分析・可視化」「業務適用」「継続学習」の4つに分けて要件を整理します。データ活用の4つのステップについて、企業データから機械学習を用いて有力顧客を抽出するユースケースを図2に例示します。
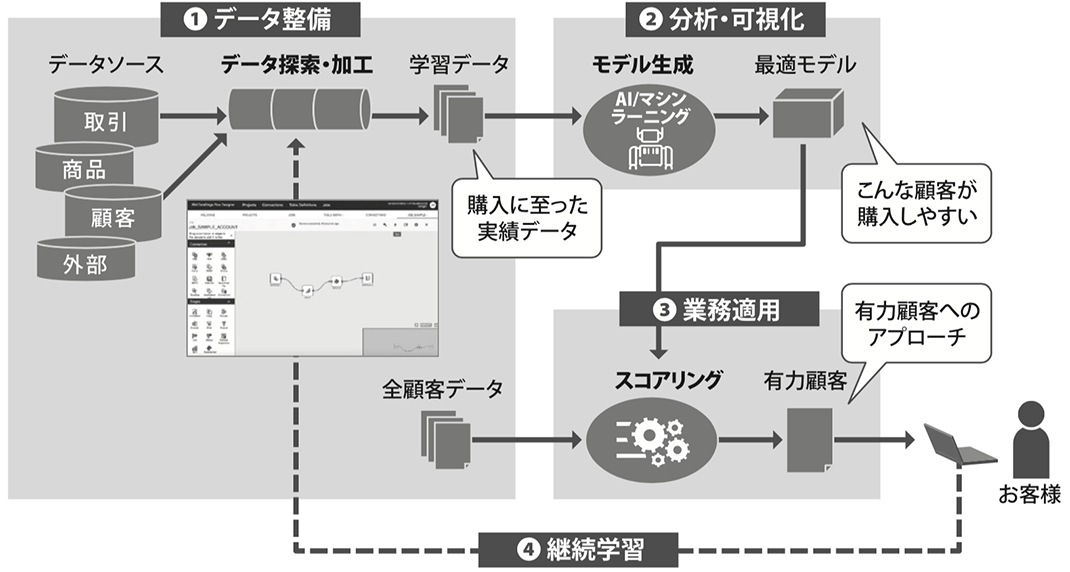
図2. データから価値を引き出すためのステップ例
(1)データ整備
企業内外にデータが散在している、データのフォーマットが統一されていないなどの理由から、データ活用プロジェクト全体の8割の工数は、データ収集から加工までの作業にかかると言われています。効率良く、スピーディーに、低コストで、質の高いデータを整備することが、このステップにおいて強く求められます。
(2)分析・可視化
このステップでは整備・加工したデータを基に非定型分析を行ったり、ダッシュボードなどに可視化したり、学習データとして機械学習機能で学習させ予測モデルを作ったりします。以下の点が求められます。
- 高度な分析スキルがなくとも精度の高い予測モデルが作れるような機械学習機能を装備し、多くのユーザーがデータから価値を創出できること
- 各担当者が利用しやすいツールを使い、生産性を上げられること
- AIプロジェクトに関わるメンバー各自が開発したデータや分析モデルなどのアセットを共有・再利用しながらも、権限管理などのガバナンスを効かせられること
(3)業務適用
このステップでは作成したモデルをビジネス・プロセスに組み込みます。データ活用は「分析をする」ことが目的ではなく、「価値を高める」ことが目的です。分析のアウトプットを業務に組み込み、顧客にサービスを届けることで、データがビジネス価値となります。そのためには全社を俯瞰し、従来の業務をどう刷新していくかを考え実装する必要があります。つまり、分析のアウトプットを業務に実装するための仕組みが求められます。
(4)継続学習
上記に示す3つのステップを効率的に循環させ、継続的に精度を上げることも、データ活用をビジネス・プロセスに組み込む仕組みとして重要です。
2-2. プラットフォームの非機能要件
昨今のデータ活用要件の変化から導かれる、ビッグデータを収集・蓄積し最新のデータ活用を支援する基盤の非機能的な側面を図3に整理します。
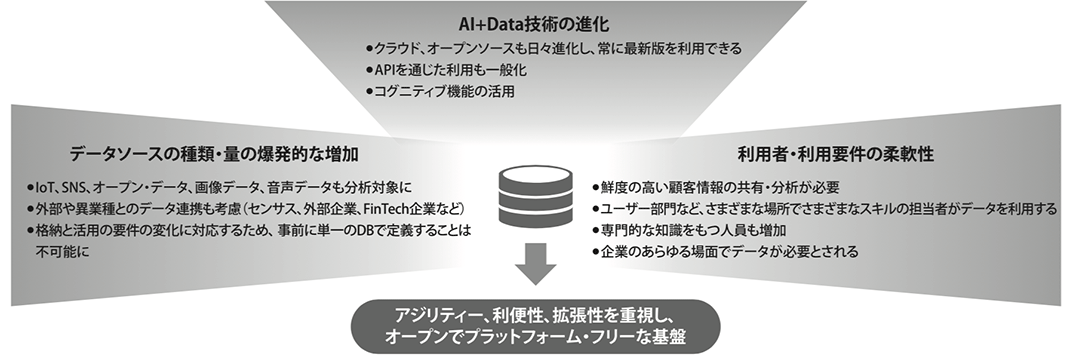
図3. データ活用要件の変化とプラットフォームの要件
第四次産業革命の中核となるIoT、AI技術の活用に向けて[*2]、ウォーターフォールで要件定義を経て設計・実装される従来型のデータウェアハウス(以下、DWH)の発想を脱却した、アジリティーや拡張性を重視したオープンなデータ・プラットフォームが求められています。[*2]内閣府経済財政政策-日本経済2016-2017, 第1節 第4次産業革命のインパクト
後編:2つのソリューション「IBM Watson Studio」と「IBM Cloud Private for Data(以下、ICP for Data)」の最新情報を解説はこちら2つのソリューションはともに、このページで述べたデータ・プラットフォームの要件を実装しています。提供形態は異なり、Watson Studioはクラウド上のフル・マネージドなSaaSソリューションとして、ICP for DataはオンプレミスやIaaSに導入可能なコンテナ・ベースの統合ミドルウェアとして提供されます。
データからより高い価値を引き出すというゴールを実現には、3つの基本的な課題「データのアクセスしやすさ」「データの品質」、および「人材不足」の改善に取り組むことが必要です。また進展をつづける各種法制度に対応していく必要もあります。これらの課題を解決することが、重要事案に対する意思決定やAI活用に役立つ、信頼できるデータ基盤を構築するための足掛かりとなります。

久保 俊彦 Toshihiko Kubo
日本アイ・ビー・エム株式会社 IBMクラウド事業本部 シニア・アーキテクト
1999年日本IBM入社。電子カルテシステムの開発プロジェクトへの従事を経て、Information Architectとして、金融・製造・流通業の基幹系/情報系システムのコンサ ルティング、アーキテクチャー設計を、海外SMEと連携し推進。現在は金融機関のビジネス/IT部門とともに、企業横断でのデータ・AI・クラウド活用による価値創出を推進している。

時光 さや香 Sayaka Tokimitsu
2002年日本IBMにSEとして入社。金融・製造・流通など様々な現場で8年間オープン系アプリケーションのデータ設計・データ関連コンサルティング、情報系システム構築を担当。7年前からは技術営業として、データ分析製品の選定支援を行う。現在はWatson Data &AIを中心としたクラウド・サービスの選定支援を行っている。


多言語自然言語処理研究の基礎を支える、評価尺度BLEU
ディープラーニングが自然言語処理の世界を席巻するようになり、翻訳や要約など様々なタスクにおいて精度を向上させる新しい手法が毎日のように提案されています。 一方、精度がどのくらい向上したかを判断するための評価手法については […]

人間中心のAIとは?
AIは、営業、財務、人事など様々な領域で、ますます応用されています。本記事では、AIシステムの開発において、IBMリサーチが採用している人間中心のアプローチを紹介します。 自動車の自動運転、創薬、ニュースや […]