

























Perspectives
Nationwide Building Society engages IBM to assess the capability and maturity of Fully Homomorphic Encryption
5 April, 2023 | Written by: Adrian Townsend, John Patrick, and Omri Soceanu
Categorized: Perspectives
Share this post:
In this blog post, we discuss how Nationwide Building Society partnered with IBM Client Engineering and IBM Research to investigate the functionality, performance and viability of Fully Homomorphic Encryption as a potential candidate technology for the Society’s data security strategy.
Protecting Nationwide member data.
Adrian Townsend, Nationwide Proof of Concepts Lead: Nationwide Building Society is a UK financial organisation offering banking, saving, lending and mortgage services. Nationwide is not a bank; it is a building society – a mutual, owned by its members. The Society is run for the benefit of members and to help communities across the UK, donating 1% of pre-tax profits to charities to help build a better society.
Nationwide is committed to ensuring the safety and security of our members’ data. As services increasingly move to public cloud environments, and cyber security threats increase and evolve rapidly, the Society is continually evaluating new technologies which could improve our security and resilience. Fully Homomorphic Encryption is an example of an emerging technology which has the potential to enforce stricter security protocols and to offer greater protection for member data.
What if you could unlock the value of your sensitive data without ever having to decrypt it?
John Patrick, IBM Client Engineering Senior Solution Architect: Well-designed software applications encrypt sensitive data when it is at-rest or in-transit. This provides robust protection of data in those states; however, to analyse or process data in memory, it needs to be decrypted. This creates a window of vulnerability for hackers to potentially exploit; unencrypted data in-use could be susceptible to external attacks, insider threats, and data theft.
Homomorphic encryption refers to a class of secure encoding methods conceived by Rivest, Adleman and Dertouzos in 1978. Homomorphic encryption differs from typical encryption methods by allowing computation to be performed directly on encrypted data without the need to decrypt it, and without requiring access to a secret key to process it. The result of this computation remains encrypted in-transit and in-use, to be retrieved and decrypted by the owner of the secret key when later at-rest.

“Lab glovebox” representation of processing homomorphic encrypted data.
Homomorphic encryption uses multiple types of encoding schemes to perform different classes of computation on encrypted data. Computations are represented as circuits (Boolean, arithmetical) and gates (addition/subtraction, multiplication/division). Some types of homomorphic encryption can evaluate multiple circuits with one gate, others can evaluate subsets of circuits with multiple gates. Fully Homomorphic Encryption (FHE) is the strongest notion of homomorphic encryption, enabling evaluation of arbitrary circuits composed of multiple types of gates of unbounded depth.
The first plausible FHE scheme was constructed in 2009 by Craig Gentry at the IBM T.J. Watson Research Center, using a form of lattice-based cryptography. IBM has continued to research and develop FHE technology since this breakthrough, culminating in the announcement of IBM HELayers in 2021. IBM HElayers is a software development kit (SDK) for the practical and efficient execution of encrypted workloads using FHE data.
Adrian: Nationwide recognises that FHE has the potential to support a zero-trust strategy by keeping our members’ data, the models that process the data and the generated results encrypted end-to-end, including during computation. This advanced security approach can help to protect against external attacks and insider threats stealing intellectual property or sensitive information, intentionally or inadvertently.
The Society monitors the progress of emerging technologies which would offer greater protection for members’ data. We determined that FHE had reached a level of maturity that warranted consideration of its viability as a candidate for our security strategy, and selected IBM HELayers to examine the functional capabilities and performance of FHE.
Nationwide and IBM Value Engineering workshops.
John: In mid-2022, the Nationwide PoC team joined IBM Client Engineering and IBM Research to participate in a series of Value Engineering workshops based upon the IBM Garage Methodology. This is an Enterprise Design Thinking framework which encourages a blue-sky collaborative approach to help define a business opportunity, or to drive new insights into an existing idea. The methodology identifies and understands context, constraints and challenges, and defines the scope of a prototype solution which would be required to prove or disprove agreed hypotheses.
The first session was a Business Framing Workshop. This gave the IBM teams an opportunity to listen and learn about the Society’s business, goals and challenges, and for Nationwide and IBM to identify and agree the priority Use Case to move forward with.
Adrian: Nationwide wanted to explore the feasibility of integrating FHE into the Society’s technology estate. The Framing Workshop gave us the opportunity to discuss the business areas which would benefit, examine the in-depth configuration of our existing platforms, and prioritise a Use Case for a PoC to confirm whether FHE has reached a level of maturity which is viable for enterprise use.
This collaborative approach and exchange of knowledge enabled us to agree that enhancing the protection of data when performing analytics would provide the most thorough examination of the functional and performance capabilities of FHE. Through a set of prioritisation exercises, we decided that using machine learning to detect potential money laundering provided the best Use Case to address the assumptions that we needed to prove. We agreed to prioritise our public cloud environment for this investigation and established a PoC Use Case statement:
“Safeguarding data when leveraging public cloud infrastructure to analyse transactions to determine the probability of money laundering.”
John: The second session was a Scoping and Solutioning workshop. Building upon the output from Business Framing, Scoping acknowledges that we know the problem that we want to solve but need to define the riskiest assumptions to be tested, and Solutioning determines what we need to build to address the challenges that we’re trying to solve.
The Scoping exercise prioritised two assumptions which required proving by the proposed PoC:
- Security: Provide evidence that FHE security is strong enough for Nationwide stakeholder buy-in, and that data is secure in the cloud.
- Performance: Provide evidence that FHE compute speed is comparable to day-to-day, and that data can be processed as quickly – or within an acceptable overhead – as when unencrypted.
The Solutioning exercise confirmed that IBM Research would provide the PoC platforms, and that the components for the PoC build and tests were to be IBM HELayers and its implementation on public cloud: IBM HE4Cloud. In order to prevent the need to obtain and obfuscate Nationwide members’ sensitive personal data, it was agreed that the PoC base dataset to use for Anti-Money Laundering (AML) analysis would be a Kaggle Synthetic Financial Dataset for Fraud Detection. Since the proposed tests would require datasets with a variety of size and diversity, the Society provided a Python script to extend the data breadth, depth, and balance.
The final output of the Scoping and Solutioning workshop was a PoC Statement to define the scope and deliverables of the solution to be built:
“If we provide Nationwide Data Science and Security Teams with an FHE cloud-based test platform populated with Nationwide-provided sample data, we will address understanding of performance overhead, speed reduction and result set equivalence when processing FHE vs. unencrypted data.”
Adrian: On completion of the workshops we had a clear and joint understanding of our goals and objectives. The sessions were very well-structured, fast-paced and encouraged discussion. The approach helped the team to challenge the issues and discover practical and innovative ways forward.
A Proof of Concept built in four weeks.
John: The build was undertaken by the IBM Research team. We defined two two-week iterations to test, measure and analyse both functional equivalence (FHE vs unencrypted processing result sets) and non-functional differences (compute resources and speed differential between FHE and unencrypted processing):
- Iteration one – Train and run AML Machine Learning models on HELayers.
- Iteration two – Run the trained AML Machine Learning models on HE4Cloud on public cloud.
Omri Soceanu, IBM Research AI Security Group Manager: IBM received the AML dataset which we used to train two models in the clear: a Logistic Regression model and an XGBoost model. The performance and accuracy of these models served as a baseline against which we could compare our results using encrypted data. We then created an FHE version of both models, and for the Logistic Regression model we performed the training over encrypted data. The resulting models were used both in a Jupyter Notebook and as part of IBM’s FHE Cloud Service – HE4Cloud – which can run on different secure public cloud platforms, on-premises systems (e.g. IBM z15 and IBM z16), and secure execution environments (e.g. IBM Hyper Protect Virtual Server).
Adrian: Throughout the build process the Nationwide team was kept up to date on progress through regular discussions and demos. Each interaction gave the opportunity to ask questions and shape the next steps of the process. It was an informative and enjoyable process to see FHE in action, and to learn more about the technology.
Results.
Omri: The results for the FHE models showed minimal degradation in terms of accuracy compared to the original cleartext model (in most cases there was no degradation at all). In terms of performance, we were able to classify a baseline FHE dataset containing over 92K transactions in 3.44 seconds with the Logistic Regression model, without using special hardware.
At Nationwide’s request, we also classified the same dataset using an XGBoost model. Unlike Logistic Regression and Neural Networks, XGBoost is not considered to be an FHE-friendly framework; even so, we were able to classify the 92K transaction sample set in 103 seconds (i.e. 9 records classified per 100ms). This represented acceptable performance, since XGBoost is used in systems that are not real-time and which process smaller datasets.
The following table summarises the results of the baseline 92K transaction dataset. Illustrated are inference time per sample, area under the ROC curve (AUC), and F1 model accuracy score.
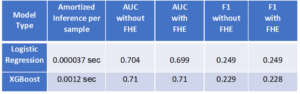
Results Summary against baseline dataset (92,254 transactions)
We then tested the Logistic Regression and XGBoost models against a variety of different versions of the dataset, ranging in size from 1K to 1M transactions. In addition to altering the depth of the dataset, we altered the width across the different versions by combining numerical columns to create additional features. We also altered the class imbalance of potentially fraudulent transactions within the data, with a range between 1K and 100K records for the 1M sample.
Across all test datasets, the Logistic Regression model delivered consistent accuracy, and performance was found to scale linearly. For the XGBoost model, accuracy was also consistent across all test datasets. XGBoost works best with batch sample sizes of 16K, and performance scales linearly as the number of samples increases, at a rate of circa 800 records per second.
As noted above, we used standard hardware in testing, all of which was CPU-based. Our lab tests have confirmed that replacing CPUs with GPUs would deliver an accelerated performance gain of approximately 10x on these figures.
In the second PoC iteration, the models were run as part of the HE4Cloud SaaS solution running on public cloud, and on an IBM zSystem. These tests confirmed that accuracy and latency in those environments was equivalent to that observed in the iteration one tests.
Conclusions.
John: The final PoC playback between the Nationwide and IBM project teams, attended by Society stakeholders including Heads of Engineering and Data & AI, confirmed the following outcomes:
- Compute and speed differentials are understood and in an acceptable range across all tests.
- The FHE result set is equivalent to the unencrypted result set across all tests.
Adrian: This engagement concluded that FHE has reached an inflection point where it is a viable candidate for practical application. Going forward, we are continuing our investigations and looking to confirm further candidate Use Cases for development with IBM Research.
I would like to give thanks to the IBM Client Engineering and Research teams for sharing and demonstrating their expertise in Fully Homomorphic Encryption. We’ve been able to understand how IBM’s HElayers SDK makes FHE easily accessible despite the encryption’s complexity, and how FHE takes security to the next level for protecting our organisation’s data. The IBM teams were highly experienced, knowledgeable, considerate, and first-class to work with. The team was communicative, open throughout the process, and committed to ensure that we received exactly what we needed.
For more information on IBM Client Engineering, please visit: https://www.ibm.com/client-engineering
For more information on Fully Homomorphic Encryption, please visit: https://aip360.mybluemix.net/tools
For more information on IBM HELayers, please visit: https://ibm.github.io/helayers

Nationwide Building Society Proof of Concepts Lead

IBM Client Engineering Senior Solution Architect

IBM Research AI Security Group Manager

Preparing for the defence of the Realm
In light of current conflicts, the UK is now faced with real-world military decisions that will affect our immediate future. Ed Gillett and Col Chambers assert that industry and government must switch to a readiness mindset before the European post-war peace shatters. “My vision for the British Army is to field fifth-generation land […]

Frontier Fusion: Accelerating the Path to Net Zero with Next Generation Innovation
Delivering the world’s first fusion powerplants has long been referred to as a grand challenge – requiring international collaboration across a broad range of technical disciplines at the forefront of science and engineering. To recreate a star here on Earth requires a complex piece of engineering called a “tokamak” essentially, a “magnetic bottle”. Our […]

Safer Technology Change in the Financial Services Industry
Many thanks to Benita Kailey for their review feedback and contributions to this blog. Safe change is critical in keeping the trust of customers, protecting a bank’s brand, and maintaining compliance with regulatory requirements. The pace of change is never going to be this slow again. The pace of technology innovation, business […]