

























Perspectives
Multi-Modal Intelligence Platform
18 July, 2024 | Written by: Mark Restall
Categorized: Perspectives
Share this post:
Traditionally, data management systems provided only numerical or textual based business intelligence primarily for back-office users across finance, sales, customer management and supply chain. Today, we are increasingly seeing data management systems which drive key business functions requiring interrogation of multi-modal data sets from documents, presentations, images, videos to audio. This demands a more sophisticated and re-engineered data management solution.
To deliver this functionality, a different approach is required, leveraging machine learning, emerging Gen AI agent-based frameworks and dimensional stores such as Graph/Vector.
Typically, a research or manufacturing company will use a diverse range of data source types, to generate insights, derive business value and maximise business impact enabled by that insight stored within the source type/format; These may be:
- Produce and consume presentation papers from internal and external sources.
- Use photographic images, infographics as e.g. evidence of results or state.
- Query and access to static data sets.
- Notes describing the conditions or results.
- Time series data sets, including audio and video data.
The traditional data platform provides a valuable source of data, and may form part of the solution, but it is obviously not equipped to ingest, store, or analyse the data sets and therefore requires an upgrade or replacement.
The Rise of The Large Language Model
The key on-going challenge is how to store, and analyse, these multi-format data sets and derive insights to provide business value which can be trusted. Large Language models (LLMs) were introduced into the world over the last few years and will have a huge impact on how we individually do work today and in the future. LLMs are rapidly evolving from document summarisation to leveraging specialist agents which can perform specific tasks.
LLMs are trained on very large amounts of data (multi-petabytes) with the aim of predicting the next word that will occur as a response to a prompt or question based on the data set that it has been trained on. They can be asked to perform tasks such as summarisation of text to extract the key points, generate programming code to fulfil a specific task, create a report on a topic, perform tasks and analyse data etc.
More recently has been the introduction of multi-agent LLMs. This technology allows a user to enter a prompt or question to an orchestrator. The orchestrator divides the work up to specialist assistant agents calling upon specialist agent LLMs. The agent LLM’s communicate with one another to achieve the overall task. For example, one assistant could create the code, communicate to the next, the code to execute and create the report or output is returned to the orchestrator and ultimately the end user.
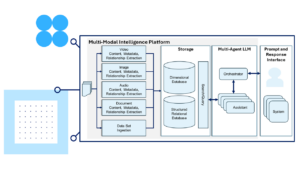
Multi-Dimensional to Complement Traditional Stores
The ability to store content and metadata linked by relationships delivering a dimensional store is becoming increasingly important for even greater insights with LLM’s. Typically, this is achieved through a graph database or vector store. For example, a document contains text, charts, and tables, The detected and derived from text, charts, tables etc. are important to store, but equally metadata giving an indication of location, style, shape, colour etc to add information which we as humans use to interpret the data. A relationship provides a link(s) between elements. A relationship would define the type and strength of connection, which would add another dimension of meaning about the elements, attempting to reflect the mechanism we as humans do in our understanding of the world.
For many use cases, the traditional relational database to store structured and sometime semi-structured data is also required, as it is more efficient for this type of data access.
A future platform for performance and this dimensional data requirement, cannot simply rely on solely one store type over another, but a combination is needed and may be others for specific use cases.
Use of Multi-Agent Providing Specialist Capabilities
Using these technologies, you can see that once the data is stored in these database technologies it would be possible to create a series of assistants with different specialisms in interpreting, generating code, to access the data in the repository and creating results based on their specialism. It is expected that assistant LLM’s numbers will evolve over time, increasing the ability to gain insights into the data stored.
Expanded Ingestion Pipelines
A Business Intelligence platform typically ingests structured file or streamed data, passing through malware detection, a standardisation or conform process which corrects the data if needed and may change the data so that it is e.g. the correct units to store in the database.
While the Business Intelligence data pipeline is retained, other types of data typically can be ingested, including documents, images and timeseries data including video and audio. However, existing ingest pipelines cannot be easily re-worked to extract all the elements from these data types. In addition, traditional stores cannot efficiently hold content, metadata, and relationships between data, while also supporting search for extracted elements in multiple dimensions. Equally, Business Intelligence structured data is well suited to typical relational databases. This requires different ingestion mechanisms for the additional data types supporting content extraction and storage approaches as shown below.
Documents, video, audio files are containers holding rich content as well as metadata and relationships that can be detected or derived. What this means is that we need to build pipelines that can process these data types and extract value which can be used in a meaningful way for by the multi-agent LLMs. For the different data types, we need detect and derive content. Detection means understanding the content, and extraction of key elements e.g. text, shapes/objects, values etc, deriving is where we further process the detected element or combination of elements to gain insight e.g. sentiment, object recognition etc. Additionally, we need to extract metadata; Metadata has many roles; it may describe the context of the data type e.g. where it came from, it’s security, genre, format etc., it can also describe e.g. technical aspects of the data type, bit pattern, position, sample rate etc. as well as other elements of the data set, or created specifically to define, control further data or elements of the data it relates to.
Building Relationships in Detected and Derived Data
As content and metadata from the source, is detected or derived we can build relationships between these elements. Relationships can be used to define parent child relationships, but also the strength/confidence and type of relationship e.g. detected, derived etc. Post processing can be undertaken to derive further elements or build additional business or technical orientated relationships. Care must be taken when deriving new content, or relationships, to minimise or remove bias/ hallucinations/incorrect data to increase trust in the data.
Once the content, metadata and relationship has been built in the graph/vector database/store, it should be able to be queried through any dimension (content, metadata, relationship attributes) or combination of dimensions. This allows a subset of content, metadata, and relationships to be extracted to allow training or query.
For LLM training, keywords and tags can be extracted through further processing based on the problem context that is being solved. For me the most common use case, uses multi-agent LLM’s where the assistant LLM’s with specialist training, can generate code, query, and gain further insights from the data sets used to provide output as a report.
Conclusion
At the start of this paper, we started talking about Business Intelligence platforms, but there is a strong rationale to deliver a new genre of Multi Modal Intelligence Platforms, that have access to rich multi-dimensional detected (directly extracted) and derived (from say feature extraction) textual content, delivering greater understanding and insight made possible through the enormous flexibility and power through dimensional Databases/Stores and LLM’s.
Multi Modal Intelligence Platforms allow you to query and interpret the world of your business in a way that has not been possible until now and it is still a challenge; Yes, you could argue that data lakes could contain the data, but calculations and queries typically were against pre-calculated tables or stored files which represented a very narrow and limited relationship to other data sets without the flexibility that this new genre would bring.
With Multi Modal Intelligence Platforms there is the opportunity to dynamically generate code on demand to perform complex queries, test hypothesis, explore new investigations etc. against related data stored in multiple dimensions within and outside of a single source, giving scope for better interpretation, and understanding.
Multi Modal Intelligence Platforms can unlock a huge range of opportunities, supporting a wide range of use cases applicable to health, life sciences, manufacturing, research etc. using a combination of image, video, audio/timeseries data where there is a core element of the business which is not well served by traditional data platform models.
Is your business ready?
Many thanks to Dr. Nicole Mather, Hywel Evans for their help and contributions to this paper.

Executive Architect, Data Technology and Transformation, IBM Consulting

Preparing for the defence of the Realm
In light of current conflicts, the UK is now faced with real-world military decisions that will affect our immediate future. Ed Gillett and Col Chambers assert that industry and government must switch to a readiness mindset before the European post-war peace shatters. “My vision for the British Army is to field fifth-generation land […]

Frontier Fusion: Accelerating the Path to Net Zero with Next Generation Innovation
Delivering the world’s first fusion powerplants has long been referred to as a grand challenge – requiring international collaboration across a broad range of technical disciplines at the forefront of science and engineering. To recreate a star here on Earth requires a complex piece of engineering called a “tokamak” essentially, a “magnetic bottle”. Our […]

Safer Technology Change in the Financial Services Industry
Many thanks to Benita Kailey for their review feedback and contributions to this blog. Safe change is critical in keeping the trust of customers, protecting a bank’s brand, and maintaining compliance with regulatory requirements. The pace of change is never going to be this slow again. The pace of technology innovation, business […]