

























Artificial Intelligence
Impact on Data Governance with Generative AI – Part One
28 October, 2024 | Written by: Mark Restall
Categorized: Artificial Intelligence
Share this post:
Many thanks to, Dr. Roushanak Rahmat, Hywel Evans, Joe Douglas, Dr. Nicole Mather and Russ Latham for their review feedback and contributions in this paper.
Introduction
As artificial intelligence (AI) and machine learning (ML) technologies continue to transform industries and revolutionise the way we live and work, the importance of effective Data Governance cannot be overstated. With the emergence of generative AI, organisations are facing new challenges and opportunities in managing their data assets. This paper (over two parts) explores the intersection of Data Governance and generative AI, examining the traditional Data Governance model and its evolution to support generative AI.
What is Data Governance?
Data Governance is an applied framework that combines management, business, technical processes and technology to ensure that data is accurate, reliable, and secure. It involves tracking data throughout its lifecycle, from creation to disposal, to understand its meaning, control its use, and improve its quality. By building trust in data, Data Governance enables organisations to make informed decisions, comply with regulations, and maintain data security. This is achieved by setting internal standards, or data policies, that dictate how data is gathered, stored, accessed processed, and ultimately disposed of.
Business Benefits
The biggest challenges organisations are facing to make themselves more “data-driven”
- Data is often not trusted.
- Hard to find and access data.
- Duplicated costs to the business as solutions developed in silos.
- Lack of traceability as to where data originated.
- Not having the right skills (data science/ architecture).
The greatest business benefits can accrue to an organisation when data is consistent, accessible and well-managed. Conversely, managing data effectively including understanding its quality, history, security, compliance and consent is important to reducing risks. These activities comprise data governance, and are critical to driving efficiency, productivity and trusted data, for better outcomes.
Purpose of Data Governance
The primary purpose of Data Governance is to achieve:
- Shared Understanding: Provide a living framework for cross-organisational teams to have a common understanding of the data, who owns it, and how it should be handled.
- High-Quality Data: Deliver high-quality data meeting metrics of high integrity, accuracy, completeness and consistency.
- Data Profiling: Understanding of data based on factors such as accuracy, consistency/statistical of what it contains and timeliness.
- Privacy and Compliance: Policies, standards and procedures drive technical and operational behaviours that ensure the systems meet the demands of government and industry regulations regarding sensitivity data and privacy, e.g. General Data Protection (GDPR), US Health Insurance Portability and Accountability Act (HIPAA), Payment Card Industry Data Security Standards (PCI DSS), Emerging AI regulations etc. Failure to comply has a significant impact on organisations.
- Facilitate Feedback and Improvement: Provides a mechanism for human and technical feedback improve processes, policies, standards, technical controls which improves quality and security of the data.
- Reduce Operational Cost: Process and storage of data is expensive, duplicate data sets and data workflows are not optimal, systems are not built using common standards etc. Data Governance has a role in addressing these areas and can help reduce the overall operational cost of the systems, support and underlying platforms.
- Support Advanced Analytics and AI Use: Ensure high quality data to support advanced analytics, machine learning and generative AI initiatives. Analytics and Model trust driven, by trust in the data, drives adoption of models.
- Monitor AI Use: Monitoring Machine Learning and generative AI is critical to detect results/out which cause reputational damage, incorrect behaviour, wrong advice, failure to comply or meet regulator enforced standards etc. Data Governance has a clear role in monitoring, reacting before and when things are going wrong.
Organisational Data Governance
It must be recognised that organisations differ significantly in operating model, purpose etc. As a result, the Data Governance models applied will vary significantly, and they may focus on specific elements, and be developing others, or not at all.
While organisations approach Data Governance in different ways, there is a pattern which emerges, which we will call “Traditional Data Governance” illustrated below.
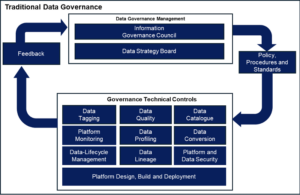
Data Governance Management
Data Governance, needs from an enforcement perspective, to be rooted in the organisation’s senior leadership represented on the Information Governance Council (IGC), and through the day-to-day Data Strategy Board (DSB). Typically, a Senior Responsible Officer (SRO) such as a Chief Data Office or Chief Information Office is a role on the board of Directors and is ultimately responsible for data, how it’s used, protected, worked on etc. within the organisation.
The IGC supported by DSB, is there to be the single data authority which owns, informs, monitors, enforces, creates, updates, retires etc. policies, procedures, standards and technical controls to support the business need.
Information Governance Council
The Information Governance Council is led/chaired by the SRO and sponsors, approves, and champions strategic information plans and policies. It owns the organisational mission for Data Governance within the organisation.
Data Strategy Board
This board handles the day-to-day issues regarding data and provides responses to those issues. The DSB owns and monitors the goals of information governance within the organisation, in line with those set by the IGC.
IGC and DSB Representatives
The IGC and DSB will have appropriate representatives to provide user, business, data, security and technical perspective etc. These representatives typically are:
- Chief Architect: The Chief Architect can have oversight of the architectural, engineering and possibly support aspects of the organisation’s platforms. Senior and more junior architects are represented in the Data Custodian persona. The Chief Architect is there to ensure common standards to architecture, component selection/recommendation and best practice.
- Data Owners: Data Owners are typically represented by senior officers / executives who have the authority to make decisions based on the information that belongs to them. They make decisions about the data to address the needs of their business function or the wider organisation. Data owners may not be involved in the day-to-day management of data. They will usually delegate data-related operational responsibilities to Data Stewards as appropriate; they cannot delegate their accountability.
- Data Stewards: Stewards are managers of the data (information) and of its implications. Stewards are responsible for championing data, as well as maintaining and reconciling across different business units etc. the definitions for data, data quality, definitions and semantics, business rules and anything else delegated to them by the Data Owner.
- Data Custodians: Data Custodians (typically technical teams) work closely with Data Owners, Data Stewards, and data security and protection teams to define data security and access procedures, administer access systems, manage the disposition of the data day-to-day (for example, management of a cloud data store), and provide backup and disaster recovery capabilities.
- Platform and Data Security: Typically, a chief security officer would be represented on the IGC with senior security leads on the DSB. They would contribute to the overall Data Governance framework from a security perspective ensuring approaches and relevant standards are incorporated. At a DSB level they would represent the security teams working on a day-to-day level ensuring compliance and working to resolve any incidents.
Applied Data Governance
Policies, Standards and Procedures shape the entire data platform, data storage and data processing, from design to operation and through to decommissioning.
Below we cover the Data Governance technical controls (defined by the Policies, Standards and Procedures) which are used to improve the trust in the data.
These controls are not just for design and build, but throughout the support and the destruction of the data and platform.
Platform Design, Engineering, Deployment
Today, almost every component e.g. application, application code, infrastructure etc. of a platform can be deployed and configured through scripts. The collection of scripts, code and other artefacts are assets which can be stored and versioned.
DevOps tooling provides the ability to automatically and repeatably deploy, update and test the solution. The use of these standards and policies, in creation, reviews and revisions through feedback, it is possible to drive those assets to a state fully supporting the organisation’s Data Governance goals for data and architecture.
Platform Security
Data security is embedded at design and throughout the platform lifetime, covering at-rest, on-the-wire encryption, strong role-based-access control (RBAC) model etc. Data Governance security standards, policies and procedures, for platform and data, enabling and controlling how architects, support, security etc. design, operate and monitor, ensuring the organisation is protected.
Data Governance Technical Controls
Data Governance technical controls embedded in the platform, monitor data, record and provide access to technical metadata about the data, monitor and improve data quality, track data processing etc. Platform Data Governance technical controls typically come in the form of:
- Data Lineage: Tracking/data flow and metrics of processing of the data.
- Data Quality: Checking the data against a defined set of rules.
- Data Profiling: Creating statistical metrics on the data itself.
- Business-Glossary: Stores a list of business terms and definitions used in describing data and its processing.
- Data-Catalogue: Stores list of fields, data type, descriptions, and other metadata describing is owner, location etc.
- Quality-Correction: Algorithms to correct errors in the data.
- Data Conversion: Basic algorithms to convert data formats or perform lightweight conversion of data values.
- Data Tagging: Added fields at ingestion to allow rollback, transformation, and deletion of selected datasets. Fields could be e.g. ingest-time, data owner, source, pipeline, security credentials etc.
It should be noted, that what is actually deployed will depend on the use-case (s) and organisational Data Governance requirements.
Data Life Cycle Management (DLM)
Data Lifecycle Management places data in a state for example data creation, data collection, data storage/stored, data processing, data sharing and usage etc. These states may change due to events, for example, requirement to destroy data, transfer to different systems, rights to use expiration, or simply change as part of navigation through the ingest data pipeline or processing operations.
The data state can be identified by its physical location in the platform layers, attributes in the Data Catalogue, specific Data Tagging etc. which requires different handling to move to the next state as defined by Data Governance policies and procedures.
Data Governance creates and enforces a DLM for data, ensuring the platform design, upgrade and destruction comply.
Platform Monitoring
Platform monitoring provides support teams with early warning of data and processing issues, predicts demand for optimal operation, capacity and demand management, and expense controls for example. Data monitoring using Data Governance platform technical controls, alerts the Data Custodians if there is increased quality-rule non-compliance from the source provider or perhaps problems in earlier stages in the platform, allowing investigation by Data Custodians and if required, feedback on standards, processes and procedures.
What Needs to Change in Traditional Data Governance?
Traditional Data Governance has served well over the years, however, there need to be increased capabilities or new elements added to support generative AI. Traditional Data Governance has:
- Largely been focussed on structured data, however, to evolve to support generative AI, this needs to be expanded to support unstructured data derived from images, video, audio, and text for example at scale.
- Limited/non-existent, support for model management, model history including generation, configuration, processes, data sources, model evaluation and test models to show a clear tree/lineage of the model, configuration and data at scale.
- Only really tracked data preparation steps through a combination of DLM, data lineage and code version control. There needs to be a better understanding as to whether these preparation steps have introduced unhelpful artefacts into the model and creating a detailed versioned record of each step, including code, processing sequence and data used in these steps, in the model history.
Next Blog
Having provided the definition of Data Governance, the next blog in this series, will explain how Data Governance will need to evolve to meet the needs of businesses, in supporting generative AI.

Executive Architect, Data Technology and Transformation, IBM Consulting

Preparing for the defence of the Realm
In light of current conflicts, the UK is now faced with real-world military decisions that will affect our immediate future. Ed Gillett and Col Chambers assert that industry and government must switch to a readiness mindset before the European post-war peace shatters. “My vision for the British Army is to field fifth-generation land […]

Frontier Fusion: Accelerating the Path to Net Zero with Next Generation Innovation
Delivering the world’s first fusion powerplants has long been referred to as a grand challenge – requiring international collaboration across a broad range of technical disciplines at the forefront of science and engineering. To recreate a star here on Earth requires a complex piece of engineering called a “tokamak” essentially, a “magnetic bottle”. Our […]

Safer Technology Change in the Financial Services Industry
Many thanks to Benita Kailey for their review feedback and contributions to this blog. Safe change is critical in keeping the trust of customers, protecting a bank’s brand, and maintaining compliance with regulatory requirements. The pace of change is never going to be this slow again. The pace of technology innovation, business […]