

























About cookies on this site Our websites require some cookies to function properly (required). In addition, other cookies may be used with your consent to analyze site usage, improve the user experience and for advertising. For more information, please review your options. By visiting our website, you agree to our processing of information as described in IBM’sprivacy statement. To provide a smooth navigation, your cookie preferences will be shared across the IBM web domains listed here.
Artificial Intelligence
Engineering bias out of AI
22 November, 2018 | Written by: Chris Nott
Categorized: Artificial Intelligence
Share this post:
Notorious examples of bias in facial recognition algorithms have received a lot of adverse coverage this year. It highlights the explosion of bias in AI systems and algorithms, but according to IBM Research, only unbiased AI will survive. To counter such bias, companies like IBM have been making data sets and toolkits available. An example is a data set of annotations for over a million images to improve the understanding of bias in facial analysis.
Nevertheless, it shows that users of such algorithms to develop critical thinking and not blindly trust artificial intelligence (AI). Furthermore, you cannot eliminate all bias, but it becomes problematic when it turns into prejudice. The challenge is compounded by multiple, sometimes conflicting, definitions of fairness. This is apparent when using the AI Fairness 360 toolkit. It checks for unwanted bias in data sets and machine learning models using multiple algorithms to assess systemic disadvantage in unprivileged groups.
However, organisations and governments would be naïve to focus simply on reducing bias in algorithms because they are not used in isolation. Organisations must consider the overall system to be legal and compliant with policies. Key areas of risk of introducing bias are in the training data and the question posed – what you are trying to achieve. It reaches from data source all the way through to the effects of actions taken.
Here I explore wider concerns for engineers by proposing six principles for reducing the bias in systems that use AI.
Engineering principles to reduce AI bias
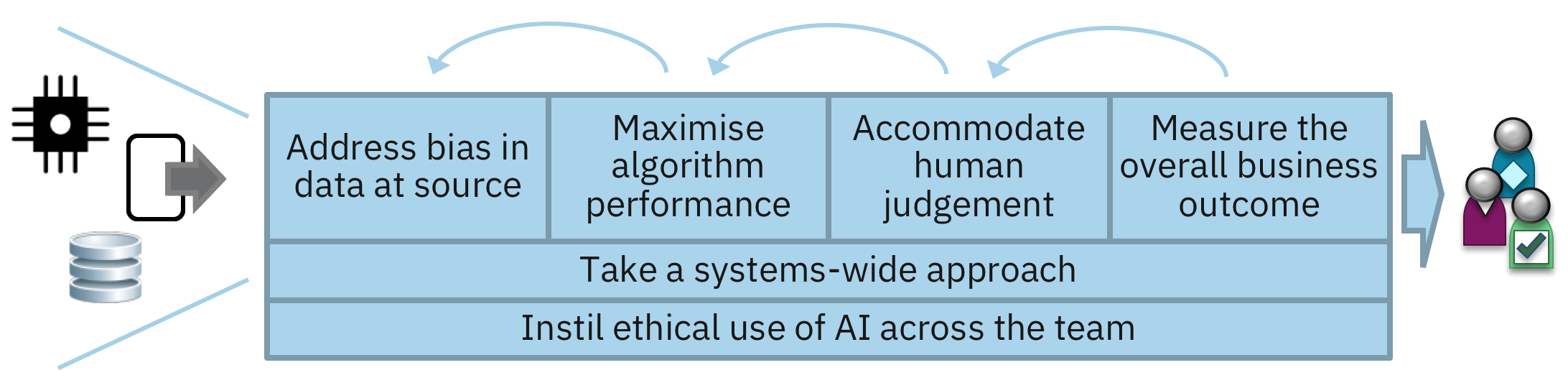
Measure the overall business outcome
It is essential that organisations focus on the measuring the fairness of overall business outcome. This is because the effects of decisions and actions are felt by customers and citizens. It is not just about the algorithm, but how organisations use it.
Inclusion needs to be considered at the outset of the design process to achieve fairness. Design Thinking is a good way to begin because it concentrates on the end users through empathy. It can be used to understand the effects of AI on those users, and to identify extreme users and scenarios for particular attention that can help mitigate bias in meeting the overall objective. As we shall see later, the answer we give to a question depends on the context in which it is asked and in which a decision is made.
Take a systems-wide approach
The overall question being asked by an organisation is likely to have inherent complexity. For example, a desire to remove age discrimination in achieving an objective may be undermined by bias which already exists elsewhere. So, organisations need to look more widely than the algorithm when implementing AI.
Tackling what affects the performance of the task is a systems engineering challenge. This encompasses the systems that provide data and take actions together with the organisation’s delivery practices and governance mechanisms, all of which can introduce bias.
Engineers should assess relevant legal and policy frameworks during design. These generally focus on gender, age and ethnicity. An important application of these frameworks is in assuring that use of algorithms does not extend beyond their intended purpose. Doing so is likely to result in untested and inappropriate use leading to unintended consequences.
Further systems engineering factors for understanding and handling bias in data and dealing with issues of explainability will be discussed later. Nevertheless, an organisation can employ the best performing algorithms by implementing accountability to comply with legal requirements and apply ethical considerations in subsequent components of the system.
Address bias in data at source
A lot of the problems in bias result from the data that feeds algorithms.
It is good engineering practice to implement an information architecture that spans data sources and line of business users within organisations. A governed data lake brings well managed approaches to data access for AI and its traceability, as well as for the use of the recommendations and conclusions reached. It uses meta data describing data sets to check that AI is using appropriate data appropriately. Understanding meta data gives insight into the context of data capture and the context of its use.
Knowing the provenance of the data is of particular importance to engineers. Indeed, an algorithm whose training data is not understood should not be used because its bias is unknown and hard to measure. It also helps counter the threat of subversion. In addition, cleaning data can introduce bias; data with its imperfections may yield more realistic results from AI. Data problems are best solved by going to its source.
There are an increasing number of annotated data sets available offering to help reduce algorithmic bias through training. Care should be exercised in their use because these are not truth data sets: there is no ideal training data in which bias is eliminated. They have been created without regard the context of question now being asked.
Maximise algorithm performance
People explain their decisions in ways that typically reflect only a few major factors. This simplification is natural and reflects deterministic thinking. However, in reality we do not make decisions in the simplistic way we say we do; we actually take account of a huge number of factors. This is context. Decisions using AI typically use many more variables and probabilistic approaches which are difficult to explain. The danger here is that imposing too many constraints reduces algorithmic performance, i.e. weakens it.
Engineers need to ensure that the systems they build that use AI do not mirror such human failings. Decisions using AI rely on weak variables that are difficult to explain. This differs from traditional analytics that can be performed in a logical programme. Instead, systems design must avoid constraining AI to using few variables or cleaning the data. It degrades performance because subtleties in data are thrown out.
(As an aside, the fallacy of removing latent variables – those inferred rather than observed – from decision making is being pursued in drawing up regulations. Simplistic, deterministic approaches to policy making don’t work because the variables removed can be back inferred. It forces characteristics that go against what the data says which are problematic and risk introducing bias.)
It might not be possible to explain an algorithm, for example, whose intellectual property is protected. This may not be an issue in areas of high precision where the focus is on the benefits afforded in the outcomes. More generally, engineers should take a systems-wide approach to explainability: unpacking how a decision is reached across all the components. Indeed, it is really accountability for the results of the overall system that matters in building trust.
Accommodate human judgement
We have seen earlier how we simplify to justify decisions. AI is necessarily a simplification too because algorithms cannot take account of every factor or the specific context of each situation. It may be best, ethically, optimally or otherwise, for someone to make a judgement that goes against the recommendation made by an AI algorithm. The risk is that the AI recommendation is blindly followed to avoid having to defend alternative action.
Engineers should proceed in the use of AI for automation with caution in favour of using it to assist humans in achieving the desired outcome in the best way. It requires organizational capacity to accommodate varying individual judgement, and mistakes.
Instill ethical use of AI across the team
Projects are increasingly diverse in their use of technology and delivery approaches. Technological advances bring more automation and more complexity. Success depends on multi-disciplinary teams where individuals hold multiple roles. These roles extend to understanding the business value of the technology being deployed so that tasks are not undertaken in isolation.
This does not mean that engineers need to become experts in AI nor are they expected to address all ethical concerns. Rather, that ethical use of AI is embedded in training for engineers. Teams will be well served by hiring experts in AI who have an appreciation of engineering practices and, of course, ethics.
The role of the engineer
Engineering practices for AI are emerging as the challenges become better understood. Unfortunately, the debate is becoming confused as use of terminology is overloaded and concepts become blurred. It may be helpful in applying the principles above by separating out three differing aspects of bias:
- The design of systems, including the people – this is domain of the engineer.
- Deterministic coding used in traditional analytics – includes data engineers and data analysts.
- Machine learning algorithms – data science and the use of toolkits such as AI Fairness 360.
As with all engineering projects, multi-disciplinary teams are required. This applies similarly to reducing bias and addressing ethical concerns in achieving the desired outcomes.

Chris Nott
Global Technical Leader for Defence & Security
More Artificial Intelligence stories

By Col Chambers and Ed Gillett on 5 February, 2025
Preparing for the defence of the Realm
In light of current conflicts, the UK is now faced with real-world military decisions that will affect our immediate future. Ed Gillett and Col Chambers assert that industry and government must switch to a readiness mindset before the European post-war peace shatters. “My vision for the British Army is to field fifth-generation land […]

By Juan Bernabe Moreno and others on 12 December, 2024
Frontier Fusion: Accelerating the Path to Net Zero with Next Generation Innovation
Delivering the world’s first fusion powerplants has long been referred to as a grand challenge – requiring international collaboration across a broad range of technical disciplines at the forefront of science and engineering. To recreate a star here on Earth requires a complex piece of engineering called a “tokamak” essentially, a “magnetic bottle”. Our […]

By Nick Levy on 9 December, 2024
Safer Technology Change in the Financial Services Industry
Many thanks to Benita Kailey for their review feedback and contributions to this blog. Safe change is critical in keeping the trust of customers, protecting a bank’s brand, and maintaining compliance with regulatory requirements. The pace of change is never going to be this slow again. The pace of technology innovation, business […]
