

























Cloud
AIOps is a Journey and a Destination
8 April, 2021 | Written by: Alan Hamilton
Categorized: Cloud
Share this post:
According to Gartner (Gartner and Moore), IT teams are dealing with increasing amounts of data and a wider variety of tools to monitor that data. This is resulting in greatly increased complexity in keeping the system in a good operational state, and can cause “significant delays in identifying and solving issues”.
“IT operations are challenged by the rapid growth in data volumes generated by IT infrastructure and applications that must be captured, analysed and acted on”, says Padraig Byrne, Senior Director Analyst at Gartner (Gartner and Moore).
All IT departments these days have a vast array of often not- or poorly-integrated IT monitoring systems, and a lack of properly-integrated tools results in a significant impact on your business (TechTarget). Indeed, not doing anything about integrating that system log from your virtualisation server into the corresponding logs from the database environment could be the very undoing of your business:
“Failing to do anything about the poor data quality in your systems, on the other hand, can set you back as much as 100 times the cost of preventing it at the point of entry.” (TechTarget)
So how do you do something about this situation? Recent events have shown that we are all more reliant than ever on our online systems, whether they have become the main source of revenue for sales, or the backbone of our communications system, integrating and managing, and going beyond simply reacting to problems must be the way to maintain control and manage costs.
To bring this level of control, IBM believes there are some key steps involved which all organisations should consider to some degree:
“Planned or unplanned, because downtime = money (that’s lost money/revenue as well as customer dissatisfaction, market share and possibly brand damage etc) these are some of the knock-on effects of downtime. “ (IBM and Metcalfe)
According to the (Aberdeen and Arsenault) report, the average cost per hour of downtime is $260,000. That’s up 60% since 2014. That’s obviously an average, but as (IBM and Metcalfe) point out, the reputational damage to your business could be much worse.
However, for many organisations it is not simply a case that you can implement some solution and suddenly you are able to predict outages and thus reduce downtime. The lack of integration between systems you have means that you have the following hurdles to overcome first:
- Reducing the noise from systems to cut down on duplicate events, unnecessary alerts, etc.
- Standardising (or normalising) the information coming from the different sources so that they can be combined to build a bigger picture.
- Understanding and gaining insight to the actual topology of the systems you are running, and the interactions between the different components. E.g. if that database server goes down, which microservices or functions are affected? If I write poor code in one of my functions, which other components call that function that might be then affected (often referred to as the blast radius).
- Are changes made to the environment to fix issues actually put under change control and documented? Is there an audit trail around the last time that fix was implemented?
- How much control of knowledge capture do you have so that you can learn from previous downtime to allow your teams to reach the solution quicker the next time?
This diagram illustrates the journey all organisations need to take to reach an optimum position. Consider where your company is and where it can reasonably get to:
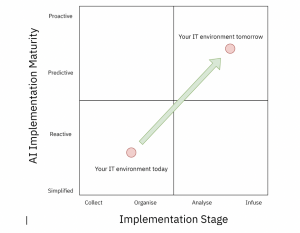
AI for IT Operations is a journey on which your organisation should embark in order to provide a “shift left” in its ability to handle outages and downtime. By “shift left” I mean that issues relating to customer experience (in the case of retailers) or communications can be handled by more front-line IT support people rather than domain experts whose primary job is not to provide support.
AI for IT Operations is not a big-bang. You should start considering how you can collect the information you are generating into one place. All those logs, all those systems spewing out logging information should be brought together so that they can be arranged and analysed to drive better insights.
Once they’re all in one place you need to organise them. This involves normalising the information and bringing the information into similar data structures. A basic example is converting time and date entries in the logs to be the same format.
With the information arriving in a format which is consistent you can start the analysis phase. This is where a product like IBM CloudPak for Watson AIOps brings its IT knowledge rules to help you. Instead of you needing to set up a rulebase in your analysis tool, IBM Cloud Pak for Watson AIOps already has all the information it needs to:
- Detect patterns and recognise issues.
- Tag and classify the elements of the information into related and unrelated events.
- Correlate everything together to give a picture of an incident, the affected components and underlying causes. For example, the slow-running of a website might be down to a long ping time to a database server which is caused by a misconfiguration of a firewall rule.
- “Artificial ignorance” (Digital Guardian and Zhang) to detect anomalies and ignore the routine.
Being able to correlate and isolate issues is a massive step forward for any IT Operations team. It cuts down the hunting for information and utilises the expert knowledge inherent in the components talking to each other which might not otherwise be available in your organisation.
Remember that it’s only when all of the people in your IT Operations team sit in a room and discuss a fault that all of the knowledge about all of the components is there. No one person has a complete view or understanding of the whole system, from networking to firewalls to servers to databases to microservices. Having a “digital twin” in the form of IBM Cloud Pak for Watson AIOps means that it can draw all this information together.
By now we’ve reached the Reactive stage in our implementation maturity, where we are able to make smarter and quicker decisions because we’re armed with all the relevant information. But how do we take it to the next level?
Being able to predict problems and therefore be proactive where AI is infused in your IT Operations landscape is where organisations need to get to in order to be able to maintain control over the increasingly-complex and increasingly-mission-critical environments they preside over.
There are two dimensions to this – anomaly detection and protection. Anomaly detection is primarily where you want things which are beginning to go wrong to be detected and for you to be alerted with recommended next best actions. It’s not enough to sample logs coming into the management system on a frequent basis. What if something happens between times when the samples are taken? You need to read every line of the logs and decide whether what you see is “normal” or not.
You also need to be able to review what you did the last time this kind of anomaly occurred. Was there an Ansible runbook you ran to fix something? Did you deploy more containers or pods to raise the compute power available?
The constant vigilance is something which IT Operations teams are struggling with most. To be always on top of whats going on, weeding out the noise from the real issues, and knowing what to do about it – if anything – is what an AI for IT Operations tool does.
However, spotting anomalies and acting before they become issues is one thing if the system is relatively static. Where you have developers adding new functionality or updating existing functionality you have an additional vector of code change which can have unintended consequences on your IT Operations.
While your crack team of software developers may be amongst the best in the business, you need to consider the dependability (Laprie and Kanoun #) of changes to the code. They are under the same spiralling complexity situation as the Operations team. They don’t have a complete understanding of every line of code running and are assuming that if they do their job right (according to the documentation) when it comes to publishing an API or calling an endpoint then all will be well. But how do you know?
The second dimension of constant vigilance, therefore is spotting potential flaws in code being injected into the environment before it goes in. This is where Application Performance Management (APM) tools such as Instana help you.
Being able to discover, map, find root cause and optimise code before it is let loose in your environment is something that you build into a CI/CD pipeline to further protect your system. In addition to proactively trapping issues before they become problems, you also need the kind of fine-level instrumentation of the code that running as you do of the IT environment it runs on.
You know how many compute cores are being used, network bandwidth consumed and memory allocated to servers, but do you know which components in your kubernetes pods are capturing all the resources? Which module is killing the response time to a database? Without a tool such as APM the chances are you don’t.
So in addition to bringing the logging information together for your physical and virtual IT environment, you need the instrumentation and logging of the performance of the code. It’s at this point you move to Proactive actioning of issues where AI is infused not only into the operating environment but also every line of code.
IT organisations are dealing with an ever-increasing level of complexity, from IT operations itself to the developers. Using a tool like IBM Cloud Pak for Watson AIOps with Instana allows you to become proactive and to be better and quicker at resolving issues, often before they become issues at all. The impact of this on your business is cost mitigation or avoidance together with your ability to further scale the sophistication of your customer experience to meet expectations. Getting to this point is a journey and one which every organisation starts at a different place.
Join us for an interactive discussion to learn more.
Bibliography
Aberdeen, and Ryan Arsenault. “The Rising Cost of Downtime.” Stat of the Week, Aberdeen, 21 04 2016 Accessed 30 03 2021.
Digital Guardian, and Ellen Zhang. “What is Log Analysis? Use Cases, Best Practices, and More.” Data Insider, Digital Guardian, 12 09 2018 Accessed 30 03 2021.
Gartner, and Susan Moore. “How IT operations can use artificial intelligence to monitor data and reduce outage times.” Smarter with Gartner, Gartner, 26 03 2019 Accessed 30 03 2021.
IBM, and David Metcalfe. “AIOps – reducing the cost of downtime.” Perspectives, IBM, 28 08 2020 Accessed 30 03 2021.
Laprie, Jean-Claude, and Karama Kanoun. Software Reliability and System Reliability. Computer Society Press, 1996. Handbook of Software Reliability Engineering Accessed 30 03 2021.
TechTarget. “How poor data quality impacts your business.” Data Science Central, TechTarget, 5 1 2021 Accessed 30 03 2021.

Senior Sales Leader - AIOps and Cloud Paks

Preparing for the defence of the Realm
In light of current conflicts, the UK is now faced with real-world military decisions that will affect our immediate future. Ed Gillett and Col Chambers assert that industry and government must switch to a readiness mindset before the European post-war peace shatters. “My vision for the British Army is to field fifth-generation land […]

Frontier Fusion: Accelerating the Path to Net Zero with Next Generation Innovation
Delivering the world’s first fusion powerplants has long been referred to as a grand challenge – requiring international collaboration across a broad range of technical disciplines at the forefront of science and engineering. To recreate a star here on Earth requires a complex piece of engineering called a “tokamak” essentially, a “magnetic bottle”. Our […]

Safer Technology Change in the Financial Services Industry
Many thanks to Benita Kailey for their review feedback and contributions to this blog. Safe change is critical in keeping the trust of customers, protecting a bank’s brand, and maintaining compliance with regulatory requirements. The pace of change is never going to be this slow again. The pace of technology innovation, business […]