

























Artificial Intelligence
Impact on Data Governance with generative AI – Part Two
5 November, 2024 | Written by: Mark Restall
Categorized: Artificial Intelligence
Share this post:
Many thanks to, Dr. Roushanak Rahmat, Hywel Evans, Joe Douglas, Dr. Nicole Mather and Russ Latham for their review feedback and contributions in this paper.
This blog is a continuation of the earlier one describing Data Governance and how it operates today in many businesses. In this blog, we will see how Data Governance will evolve to accommodate the demands of generative AI in terms of data capture, through to update and model refresh.
What is generative AI?
Generative AI is a type of artificial intelligence (AI) that can create original content, such as text, images, video, audio or software code in response to a user’s prompt or request. Generative AI relies on machine learning models called deep learning models which simulate the learning and decision-making processes of the human brain. These models work by identifying and encoding the patterns and relationships in huge amounts of data, and then using that information to understand users’ natural language requests or questions and respond with relevant new content.
Training a generative AI model
Training a generative AI model, begins with a deep learning model or foundation model, which is trained on huge volumes of data. This data is ingested, prepared, standardised, to create a neural network of parameters, calculations and data.
Traditional platforms are mainly focused on structured data. However, with generative AI the emphasis is towards multi-modal data. Therefore, the scope of Data Governance must have the policies, processes, and procedures to fully support multi-modal data (more biased towards unstructured e.g. text, images, video, audio,…), which adds different dimensions to how you undertake e.g. data quality checking, data profiling, data history/origin etc.
When driving new techniques of fact checking, for example, multiple source verification may be required. Furthermore, Data Governance can be used to improve explainability of the model outputs, capturing how a model was created (its data and steps to produce) and the influences that were used to shape its output.
This multi-modal data may ultimately live in different contexts, for example embedded/encoded within the model itself, but equally foundation models could use co-located or external data generated as models, to extend the base foundational model, shaping outputs for a particular organisation or give a new area of expertise.
Tuning
To improve accuracy, the model needs to be tuned to the specific task, typically using fine tuning or reinforcement learning with human feedback.
Fine tuning is where labelled model data specific to the types of questions or prompts that the end state model is expected to be asked, is used to train the model and refined to obtain the corresponding correct answers in the desired format.
Reinforcement learning is where human users respond to generated content with evaluations that the model can use to refine its response through re-training.
Data Governance should ensure that data sets, metadata, and human/system feedback responses correctly capture the model history change/lineage.
Monitoring and Refresh
Generative AI models (like all machine learning models) need continual system and user feedback monitoring – defining and evaluating performance metrics, to establish metric thresholds, or frequency when regeneration should occur.
External events such as a change in regulation, or a change in consumer behaviour, may invalidate some of the data sets used to build models forcing a refresh. The Data Governance maintained model and data lifecycle, may also be another trigger event for a refresh or some other action.
Data Governance may also provide guidance on the type of model that an organisation uses. Core foundation models are extremely expensive to produce (£10m-£100m), whereas:
- Retrieval Augmentation Generation (RAG) models can be trained on smaller more focused data sets, extending foundation models, providing more accurate responses, are significantly cheaper, and are more easily tuned to ensure currency for the organisation, which can be fully traceable through Data Governance.
- RedHat’s InstructLab provides a very powerful way to enhance generative AI models with new content. InstructLab provides model upstream maintainers, with the required infrastructure resources, the ability to create regular builds of their open-source licensed models not by rebuilding and retraining the entire model, but by composing new skills into it, significantly saving time and cost, to ensure currency for the organisation – which can also be fully traceable through Data Governance.
What Should Change in Traditional Data Governance?
So, what should change? In summary, it’s the transparent traceability of the elements that go into the process of creating and refreshing the model, combined with monitoring, to ensure that it is compliant, and returns accurate results without favour.
Data Governance Management
Data Governance Management (IGC and DSB) need to create policies, procedures and standards for data preparation, training, tuning, compliance, and lifecycle in the creation and update of models which take into account and monitor that the underlying data may have changed, the world that model exists may have changed, or other factors, requiring different responses than before.
Data Governance Management feedback mechanisms should be updated to ensure that the new technical controls to monitor models and human feedback are used effectively in shaping policies, procedures and standards to deliver the most accurate models, increase trust and reduces risk to the business.
Within an organisation, there also needs to be a Senior Responsible Owner (SRO) who is the designated Model Owner (potentially, distinct from the Chief Data/Information Officer) and is responsible for all aspects of the model generation and running. The Model Owner will be a member of the Information Governance Board or Data Strategy board (as outlined in the earlier blog).
Model Owner
Generative AI models are different to machine learning models that have gone before, they use knowledge to create content, advise and sometimes make decisions. The Model Owner for key generative AI models will decide on what happens to the model, strive to deliver the best outcome, protecting the organisation from any legal ramifications and reputational damage.
Updated Traditional Data Governance Diagram
In the earlier blog we provided a diagram illustrating the key elements of traditional Data Governance. We can evolve this model to include the changes and added elements due to (applications for Machine Learning and) generative AI and this is illustrated below.
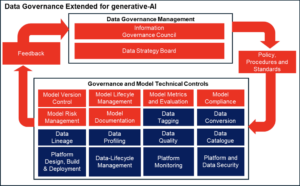
The following types of Data Governance controls can be used, leveraging and extending some from the traditional framework and adding new ones:
Model Version Control
To build trust and ensure compliance and tracking of model code, data preparation code, test, and generation data sources used for model training should be fully captured under version control.
Model Life Cycle Management
Data Governance Model Lifecycle Management tracks the model during its lifetime and assigns it to a stage in the lifecycle e.g. Model Proposal, Model Design, Data Preparation, Model Building, Model Training and Tuning, Model Testing, Model Deployment, Model Deployment Testing, Model Re-Training and Tuning, Model Destruction etc.
Generative AI models differ from other digital assets in so far as their “knowledge” may have a time currency. A digital photo does not expire, the photo is a true and accurate reflection of the scene that was captured at that time. Its purpose is not to evolve how the scene evolves and nor can it. Generative AI models may require refresh to maintain its currency (due to events like regulatory change, failure to meet new metrics, user feedback, business feedback etc.), triggering a move to a different stage (e.g. Model Re-Training and Tuning, or Model Destruction) in the model life cycle.
Model Metrics and Evaluation
The Model should be evaluated against established model metrics agreed by the IGC and DSB, during testing and continuously during its execution. The key aims are to establish the model’s performance, fairness, and stability. The following could be used to monitor generative AI:
Data Drift
Data Drift is where the statistical properties of the target variable (key input data) or input features change over time. By comparing (with the metrics) the model results with historical data, we can see if the results still reflect the expected historical data. If there is a difference, then this is due to data drift.
Model Performance
As part of model training, we established metrics for the model performance using a dataset or test dataset. Throughout its lifecycle, the model is evaluated against these metrics to ensure that it is working as expected.
Model Fairness
Model Fairness metrics ensure that models make predictions without introducing or perpetuating biases or discrimination.
Model Explainability
Model Explainability is the ability to interpret and explain how the model arrives at a given output.
Feedback
Feedback such as user feedback needs to be captured and incorporated which give evidence for change in the metrics above.
Model Compliance
Generative AI models are being used today to check for document regulatory compliance and for other tasks where validation against Government, Industry, or other body regulations are required.
Regulation can change quickly and many large organisations are affected by a wide range of regulations. Keeping track, and more importantly, deciding when to update is key to compliance.
Many of these tasks were done manually, but tooling is available today to support automated compliance checking to identify and enforce up and coming regulations.
Automation allows for recording of these changes in the Data Governance and triggering model changes ensuring that the organisation is up to date. Metrics would also need to be created so that when the model is not compliant it is flagged.
Model Risk Management
We are beginning to place huge levels of trust in our generative AI and ML models. As they become more sophisticated, they drive new risk profiles and complexities.
The Data Governance tooling using the approaches described can minimise privacy and copyright violations, as well as incorrect data which leads to false, misinterpreted, misleading or simply wrong outputs.
Data Governance tooling can also work with the test/monitoring tools to set alerts to detect when specific metrics (human feedback, model fairness, bias, drift and specific model characteristics) are out of tolerance and then inform or re-train (refresh) the model to correct the issue.
Model Documentation
Increased transparency brings increased confidence in the model validation processes. It also supports and increases the explainability of AI for regulators, auditors and consumers.
It is not a great stretch to see the concept of a generative AI passport showing the family tree of data and processing being provided with each model.
Extended Traditional Data Governance Features
Data Tagging, Data Conversion, Data Lineage, Data Profiling, Data Quality and Data Catalogue etc. will be extended to support multi-modal data which means incorporating new metadata for data source types, results of more detailed profiling covering sentiment analysis, feature detection etc. with at scale data sets.
Data Conversion and Data Quality
Data Conversion and Data Quality needs to be more carefully handled to ensure any change in the content during data preparation and generation, does not adversely affect the information in the data and the model output. The processing code, data, data pipeline, and testing needs to be recorded as it tells the story of how the data is/has changed. These elements and flow would be recorded as part of the model version control, model metrics and evaluation, model documentation and data lineage.
Platform Monitoring
Existing platform monitoring will need to be updated to support continuous evaluation of the model using the Model Metrics including user and other relevant feedback.
Note: The scale of the training data (which in some cases is multi-Petabytes) means that practically (not from a technical perspective) tracing every data set from source could be difficult, time consuming and very expensive. However, with a world of litigation and copyright infringement, demands for increased trust in the models, detection of bias, reducing risk of reputational damage, the ability to support increasingly strenuous model validations etc. I see this transparency becoming a mandatory part of the generative AI toolkit.
Data and the generative AI Sceptic
One of the key roles of Data Governance is to communicate to the communities that use or consume the data. Traditional Data Governance would provide reports on, Data Quality, Data Profiling and Data Lineage showing the state of the data and where it has come from.
In the world of generative AI this becomes even more important as they are using the tools and creators, advisers and sometimes decision makers, the job of the Data Governance Board with the Model Owner is to be a sceptic of generative AI, advising clearly where and where it cannot be used for different use cases, with active feedback (human and technical) based on the current output, advising on improvements.
Generative AI As Part of The Solution
As well as presenting new opportunities for organisations to leverage their data in ways that previously were not economically possible, generative AI can also be part of the solution, as a crucial tool for helping automate a lot of the routine processes that would otherwise be entirely reliant on human input. The main barrier to data governance at enterprise scale is effective user adoption due to time commitments and changes in organisation structure over time, so it makes sense wherever possible to explore the benefits of automation. Generative AI can support a number of key areas for Data Governance, specifically:
- Data Quality – automation of DQ checks, identification of errors and validation of data against pre-defined rules
- Data Cataloguing and Metadata Management – automation of the creation and management of data catalogues, making it easier to discover, access, and understand data assets and keep them up to date
Automation is crucial because it has the potential to reduce manual effort, freeing up resources for more strategic activities, improves quality and consistency enabling more informed decision making, and support organisations to meet regulatory requirements and standards – reducing the risk of non-compliance.
IBM has been supporting organisations to use generative AI to automate data governance processes that until recently could only be carried out by people. For example, reducing the time to collate and update metadata on image files not only significantly reduces time, but makes the exercise plausible and sustainable at an enterprise scale.
Conclusion
This blog has hopefully helped describe the evolution of Data Governance in a world of generative AI. Today, we live in uncertain times, models have been created built on untrusted data sets, there is a lack of transparency in the generation and tuning, and as a result exhibit bias, lack accuracy etc. Unfortunately, due to poor metrics, the true state is not really known, leading to issues for the consuming organisation which may well impact their consumers.
Tools are emerging and established in the market to address these challenges, tools like IBM watsonx.data Governance, which provides significant capabilities today addressing Model Risk, Model Compliance and Model Lifecycle supported by comprehensive Data Governance capabilities.
RedHat’s InstructLab, further drives the cost and time down, to deliver the business freshness of generative AI models, and when combined with strong Data Governance can go along way to building trust in this technology.
In addition to the tooling, Data Governance frameworks need to evolve to address these challenges as outlined in this blog.
Is your business ready?
Learn more about watsonx.data and watsonx.governance.

Executive Architect, Data Technology and Transformation, IBM Consulting

Frontier Fusion: Accelerating the Path to Net Zero with Next Generation Innovation
Delivering the world’s first fusion powerplants has long been referred to as a grand challenge – requiring international collaboration across a broad range of technical disciplines at the forefront of science and engineering. To recreate a star here on Earth requires a complex piece of engineering called a “tokamak” essentially, a “magnetic bottle”. Our […]

Unlocking the Future of Financial Services with IBM Consulting at Think London 2024
In a world where financial services are evolving at an unprecedented pace, staying ahead of the curve is crucial. The recent IBM Think London event, IBM’s flagship UK event, brought together industry leaders, partners, and clients to explore how cutting-edge technologies like generative AI and hybrid cloud infrastructure are transforming the sector. For IBM […]

Converting website traffic into happy customers with a smart virtual assistant
With a long track record of guiding companies across various sectors through digital transformation, IBM Business Partner WM Promus is now focusing AI innovation. Eileen O’Mahony, General Manager at WM Promus, explains how her company helped a UK-based commercial finance brokerage enhance customer experience, and develop new sales leads using IBM watsonx and IBM […]