


























伴 俊広 氏
三菱自動車工業株式会社
グローバルIT本部 デジタルイノベーション推進部
主任
2020年05月13日
カテゴリー Data Science and AI | IBM Data and AI | SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:

三菱自動車工業の伴です。
自動車会社には、開発、生産、流通、販売、品質管理、アフターサービス、広報等の業務に加えて経理、購買、人事等のバックエンドのものまで活用可能なデータが幅広く存在します。さらに自動車業界のコネクテッド化(=C)、自動運転化(=A)、Shared Service(=S)、電動化(=E)、いわゆる「CASE」の流れを受け、当社でも次世代のモビリティサービスのための多様なデータや課題を扱うようになりました。
私の所属するデジタルイノベーション推進部はそういった多様なデータと課題を持つ業務担当者に対してデータ活用を支援しています。データの活用になくてはならないのが分析ツール。整理や可視化にはExcelやBIを、特殊なモデリングにPythonなど複数のツールを使い分けますが、私のチームが最もよく利用して手放せないのがSPSS Modelerです。
SPSS Modelerには様々な機能(ノード)があり、決定木やロジスティック回帰など定番の機械学習ノードはもちろん、特徴量を作りこむ加工ノードは、特に役立ちます。SPSS Modelerの数ある便利なノードから、私の推し、「フィールド作成ノード」を紹介します。
フィールド作成ノードは、読み込んだデータに対し、指定した条件の値を格納する列(フィールド)を1列追加するノードです。
条件はCLEM式と呼ばれるSPSS Modelerの関数を用いて指定します。「派生」の選択肢(CLEM式、フラグ型、名義型、ステート型、カウント型、条件付き)により、条件分岐を指定することも可能です。
Excelに例えれば、表の末尾の列に、関数などを用いて必要な値を追加する操作です。
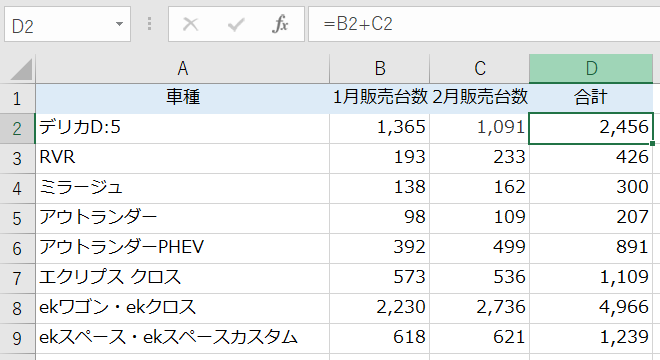
最も単純なケースで、複数の列の和の値を追加したいとします。Excelでは次のよう関数を作り、追加した列にコピー&ペーストするでしょう。
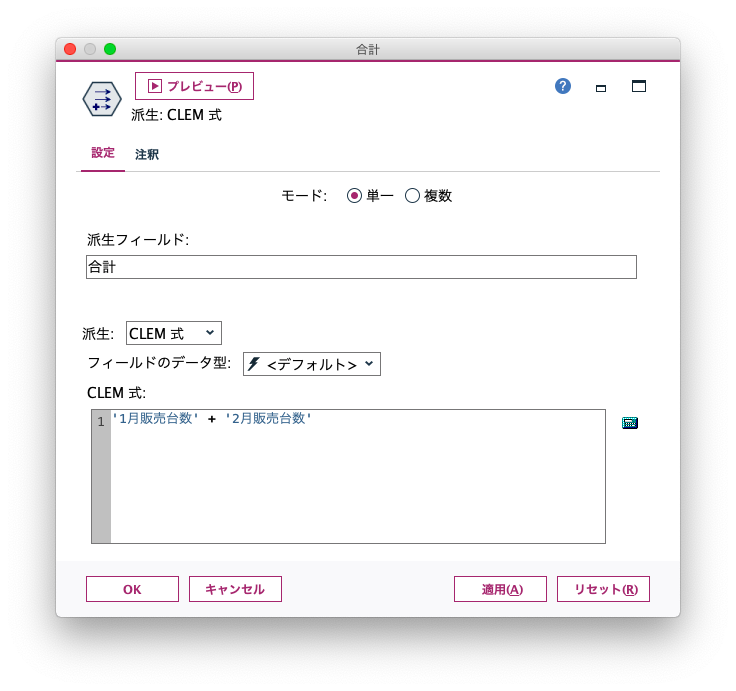
フィールド作成ノードを使って同じようことをしたい場合、次のようにします。
CLEM式では、セルではなく、列(フィールド)を指して計算をします。
IF文のような条件分岐も可能です。例えば、目標値、実績値があり、実績値が目標値を超えたかでフラグを立てるケースを想定します。Excelでは次のようにするでしょう。
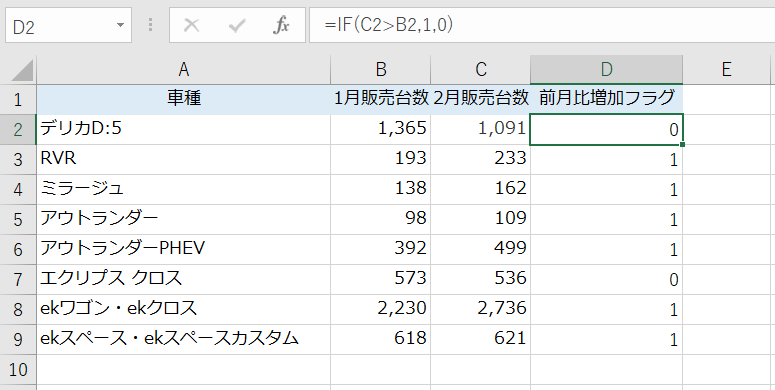
フィールド作成ノードでは次のように作ることができます。得られる結果は同じです。
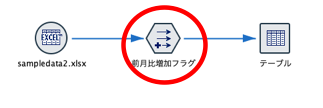
関数を記述するCLEM式は多彩な機能があります。三角関数なども扱えますし、文字列処理もできます。ノードとして実装されているような機能も含め、一般によく使うようなExcel関数の機能は揃っています。
Excelでは1行前を参照するような指定もできますが、同様にフィールド作成ノードではCLEM式の@OFFSET関数を使えば、前の行を参照させることができます。
例えば、異なる仕様を平行して生産する生産ラインでの製造記録から、仕様が切り替わったタイミングを把握するため、その仕様を表すコードが前後で変化したことを検知させるケースを想定します。
Excelでは次のようにしたとします。
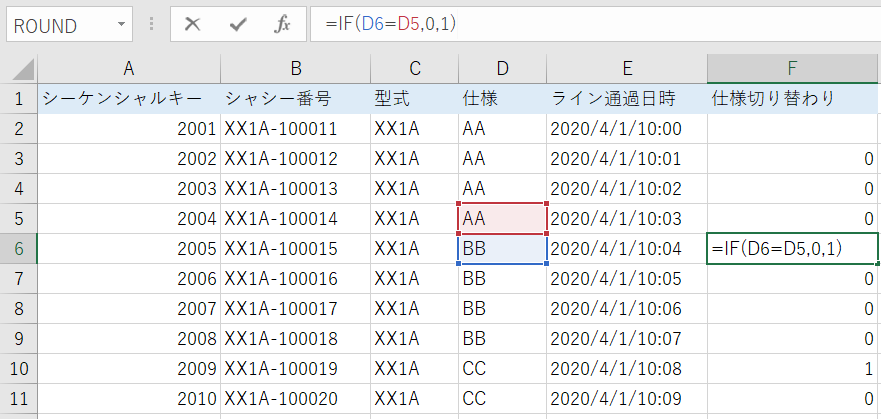
SPSS Modelerで次のようにフィールド作成ノードを用いれば、同じ結果を得ることができます。この例では1行前を参照させていますが、パラメータで指定すれば何行前でも参照できます。
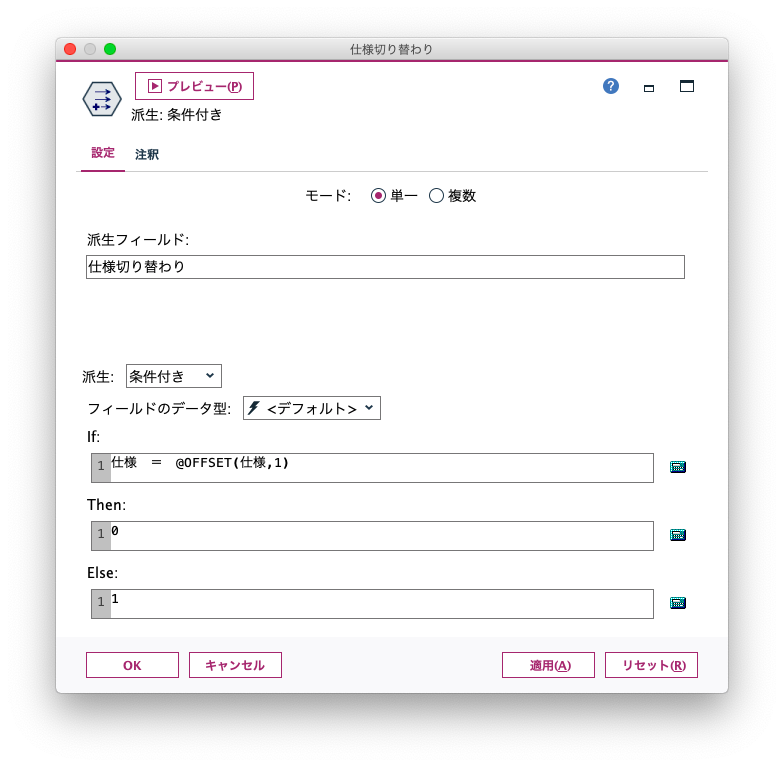
複数条件の分岐はExcelでは複雑なIF文を組む必要がありますが、派生で「名義型」を指定すればすっきりと分岐させることができます。
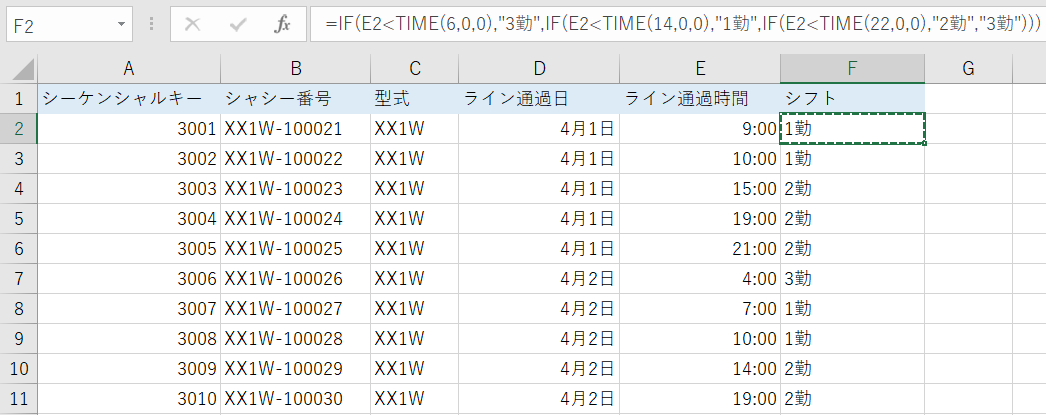
例えば、3交代勤務のシフトが敷かれる生産ラインの記録データで、どのシフトで生産されたかをライン通過時間から判定するケースを想定します。
Excelであれば、次のように入れ子のIF文を作るなどするはずです。
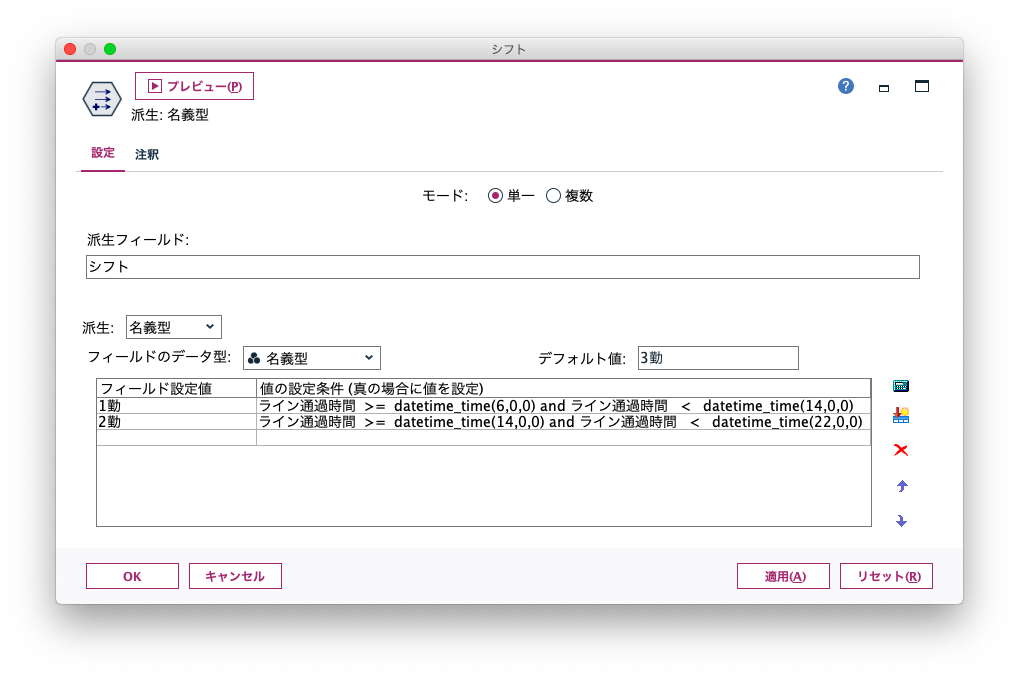
SPSS Modelerのフィールド作成ノードでは、次のように指定すれば同じ仕分け結果を得ることができます。
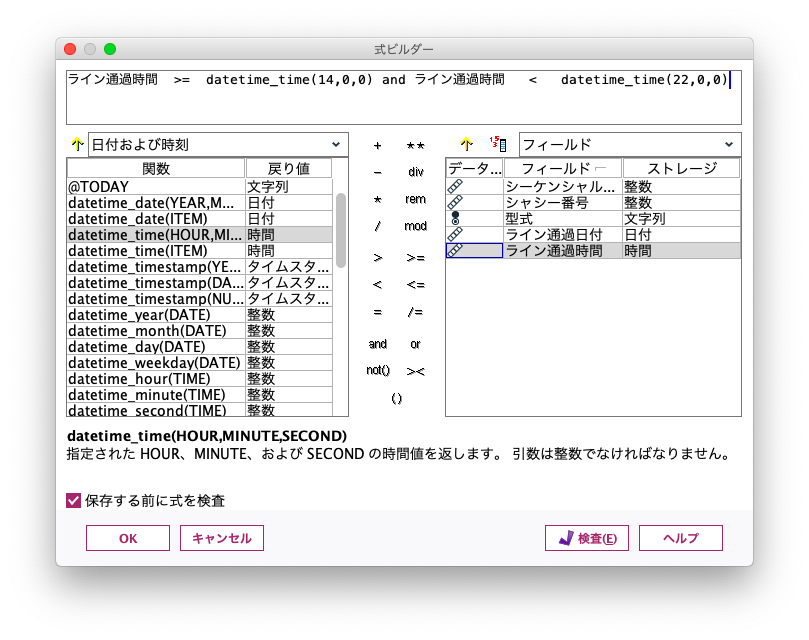
値の設定条件は、次のように式ビルダーで関数を呼び出しながら記述します。
Excelの入れ子のIF文は、複数に分岐する判定ロジックを実装出来る身近な方法ですが、読み取り辛さやメンテナンス性の悪さに苦労された方も多いと思います。
並列な条件を並列に記述できることは、可読性やメンテナンスの面で非常に有利です。
*意図的にIF文で分岐させる場合にはこちらを参考にしてください。
→https://qiita.com/416nishimaki/items/0742e7ad71cf563a6ebf
「複数」モードでは、同様な変換・計算などを複数フィールドに適用し、結果としてフィールドを追加することができます。
例えば、今般の新型コロナウイルスに関する統計で、判明した感染者数の合計を対数化したグラフをよく目にします。東京都・愛知県・京都府・岡山県の感染者数のデータをいずれも対数化したいケースを想定します。Excelであれば次のように変換します。
1つのセルに関数を書いたら、ひたすらコピー&ペーストをしなくてはいけません。
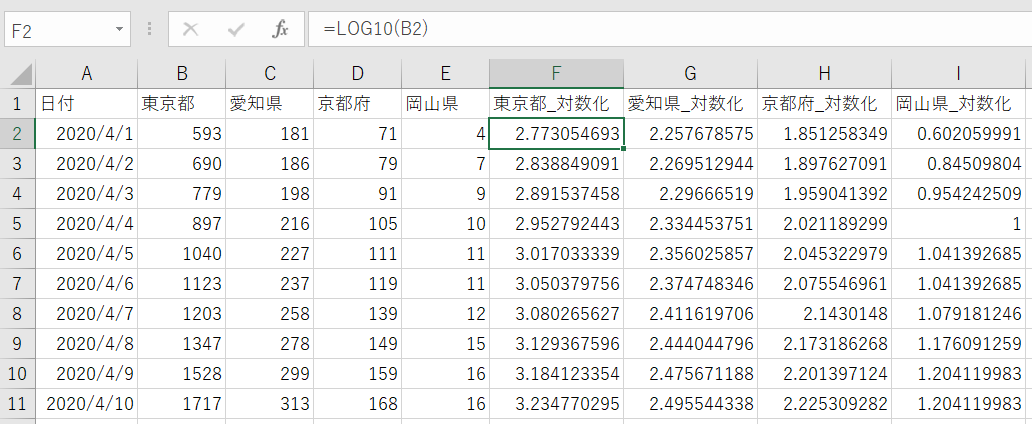
SPSS Modelerのフィールド作成ノードでは、次のように「複数」モードを使えば同じ結果を得ることができます。
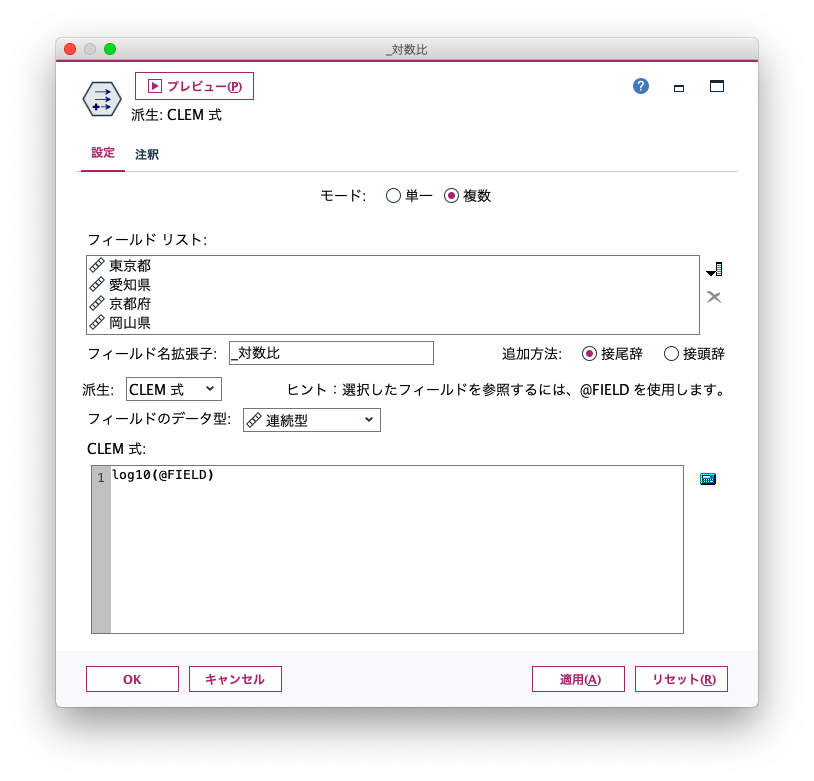
複数モードでは、CLEM式で記述した内容を、フィールドリストで選択した全てのフィールドに対して適用することができます。
各フィールドの値を引用する場合は、@FIELD関数を指定します。
CLEM式が適用された結果のフィールドが作成されますが、フィールド名は元のフィールド名に「フィールド名拡張子」で指定したサフィックスを追加したものになります。
比較してきたように、フィールド作成ノードの機能を用いるデータ加工は、凡そSPSS Modelerを使わずともExcelでもできますし、PythonやRでも代替できます。
ではなぜSPSS Modelerのフィールド作成ノードを使うのかと言うと、次のメリットがあるからです。
Excelとの実装方法を比較してきましたが、比較した通り、Excelに比べ加工の際の手間を省くことができます。CLEM式を記述する必要はありますが、Excel関数、や、Python・Rを記述することに比べれば省力化できます。
またStreamを繋げることで、複数の工程を一括で実行きます。データの加工後にグラフ・表へのプロットや、統計解析・機械学習を行う場合、それもワンストップで行うことが出来ます。
このような生産性はエンタープライズの分析活動では非常に重要です。
データ分析活動の初動で、業務関係者からデータが提供されてから早期にアウトプットを出すことは、関係者の分析活動に対する意欲や期待を保ち、当面の活動の落着点の目途付けを行い易くします。
一方で、業務関係者から得られたデータは、日常業務に利用するリストであったり、データベースのダンプであったりしますが、それらは大概にしてグラフ・表へのプロットや、統計解析・機械学習は想定されていません。そのようなデータと向き合いながら、速やかに集計軸や特徴量を作りこみ、統計解析・機械学習が出来るようにするにはツールによる後押しが必要です。集計軸や特徴量を作りこむノードは他にもありますが、最も柔軟性が高く、様々なデータやモデリングに対応できるのはフィールド作成ノードです。
近年は「AutoAI」や「DriverlessAI」のように、そのような工程を自動化する製品も出ています。データサイエンティストの立場では、初動でモデリングの当たりをつけるのにそのようなツールは便利なのですが、初動の段階では業務関係者の意図や仮説をしっかり取り上げていくことも重要です。それには言わば「効率良く手作業をする」ツールが望まれます。
また、継続的な活動では運用を省力化する必要があります。運用作業自体は勿論重要ですが、ルーチン的な作業は極力減らし、その労力を、得られた結果をビジネスに反映することや、改良・改善に振り分けることがあるべき姿のはずです。
昔に作ったExcelの入れ子のIF文を手直ししたり、解読したりするのは難しい作業です。
自分で作ったものならまだしも、前任者から引き継いだものであれば尚更です。また、そのExcelファイルの中での参照関係に気づいていなければ、うっかり触ると他の部分の結果に影響がありかねません。
SPSSのフィールド作成ノードであれば、上掲の通り可読性は良いですし、他の工程と関係があるとすれば、それはStreamから読み取ることができます。
フィールド作成ノードの利便性はCLEM式に支えられています。そして、CLEM式はSPSS Modelerとともに進化しています。
例えばSPSS Modeler 16からGeohash(地球上をグリッド分けした位置情報)を用いるspace-time-boxesが追加され、Geohashと緯度・経度を変換できる式などが追加されています。我々の様なモビリティを考えている者にとってこれは嬉しい機能追加です。
フィールド作成ノードの進化と、我々ユーザの工夫が一層進み、データ活用がより活発になることを願っています。
次回のリレー連載推しノード#08はIBMのソフトウェアサービス牧野さんが「異常検査ノード」について解説されます。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら
伴 俊広 氏
三菱自動車工業株式会社
グローバルIT本部 デジタルイノベーション推進部
主任

目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む

生成AIによるビジネス革新は、オープンなデータストア、フォーマット、エンジン、製品指向のデータファブリック、データ消費を根本的に改善するためのあらゆるレベルでのAIの導入によって促進されます。 2023 オープン・フォー ...続きを読む
