
西牧 洋一郎
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス
著書に「実践IBM SPSS Modeler 顧客価値を引き上げるアナリティクス」
2020年03月27日
カテゴリー Data Science and AI | IBM Data and AI | SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:


機械学習で性能の良いモデルをつくるために一番重要なことは、説明力の高い特徴量(説明変数)を準備することだと言われます。厄介なことにそういう変数がそのまま生データの中に含まれていることはなかなかありません。したがって仮説を立てながらデータをうまく加工して目的にあった特徴量を作り出していくのですが、この作業に全体の8割と言われる時間が費やされ、その試行錯誤や効率性が分析ツールに求められます。
IBM SPSS Modelerは特徴量を生成するノードを複数搭載しています。その中でも「再構成ノード」は秀逸で、多くのユーザーから支持されています(総選挙では6位)。
私は初めてこのノードを使ったときの衝撃を忘れられません。それまでSQLやETLツールでとても苦労した複雑なデータ加工をアイコンベースで簡単に置き換えたときには感動しました。
ひとことでいってしまえば、縦持ちのレコードを横持ちに変換する(Excelでいうピボット)機能なのですが、その便利さと値打ちを共有できれば幸いです。
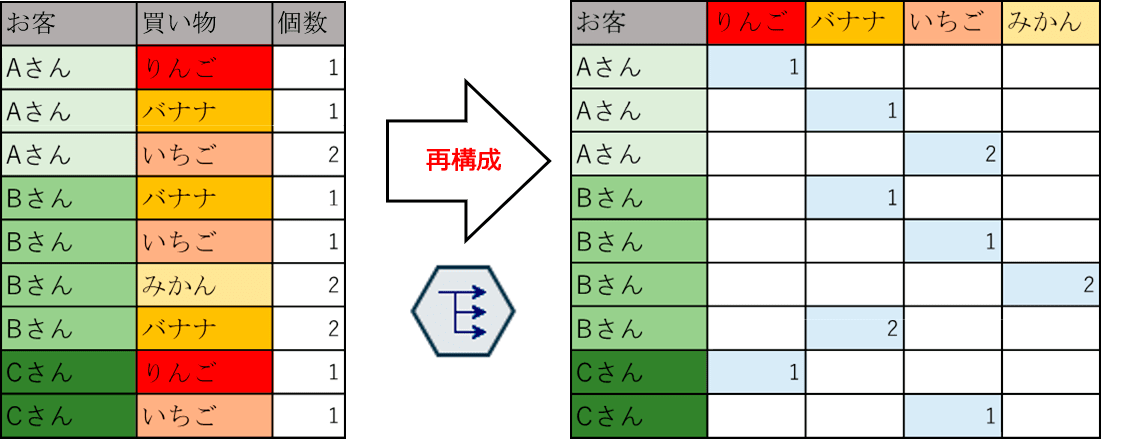
再構成ノードの素晴らしさを、ポイントカードで買い物をした際に記録されるID付POSデータ(顧客ID付き購買時点データ)を使って解説します。
顧客分析というと性別や年齢などの顧客の属性情報にまず目がゆきます。しかし最終的に有効なキャンペーンに結びつけるには、その顧客がどんな商品を購入したかという購買データが重要な手がかりとなります。
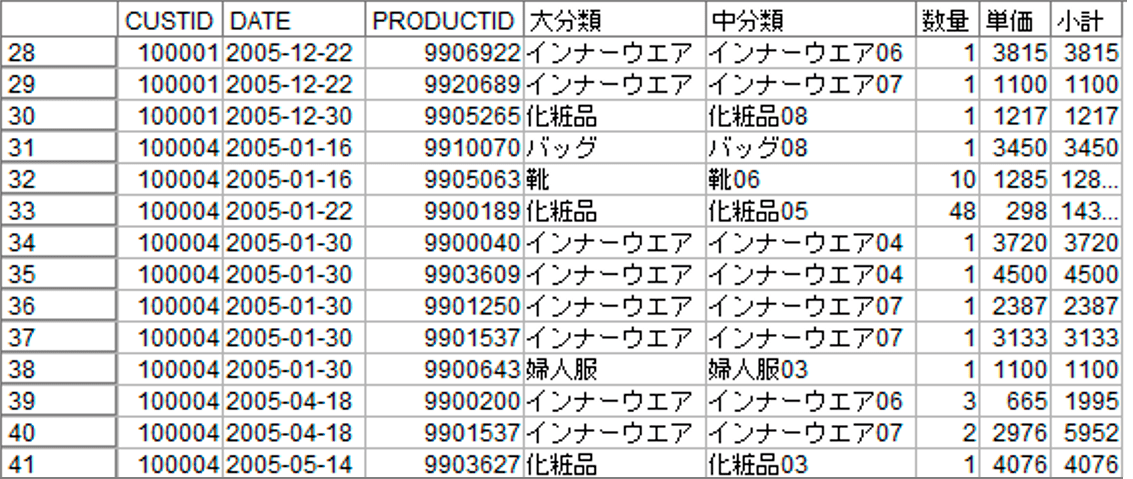
ID付POSデータは、誰(CUSTID)がいつ(DATE)何(PRODUCTID、大分類、中分類)をいくら(数量、単価、小計)購入したかを記述しています。大きな特徴は1人の顧客に対して複数行の購入履歴が存在する点です。
顧客分析する場合には顧客毎に1レコードに購買履歴を要約する必要があります。例えば、商品の大分類ごとに合計購入金額が分かると、その顧客がどのような商品ジャンルに興味を持つかを捉えられ、「化粧品と靴の中心客」や「食品ときどき婦人服」などおおよその顧客特性を理解できます。
このような特徴量を再構成ノードで生成してみます。
再構成ノードは以下のようにデータ型、レコード集計とセットで使われます。

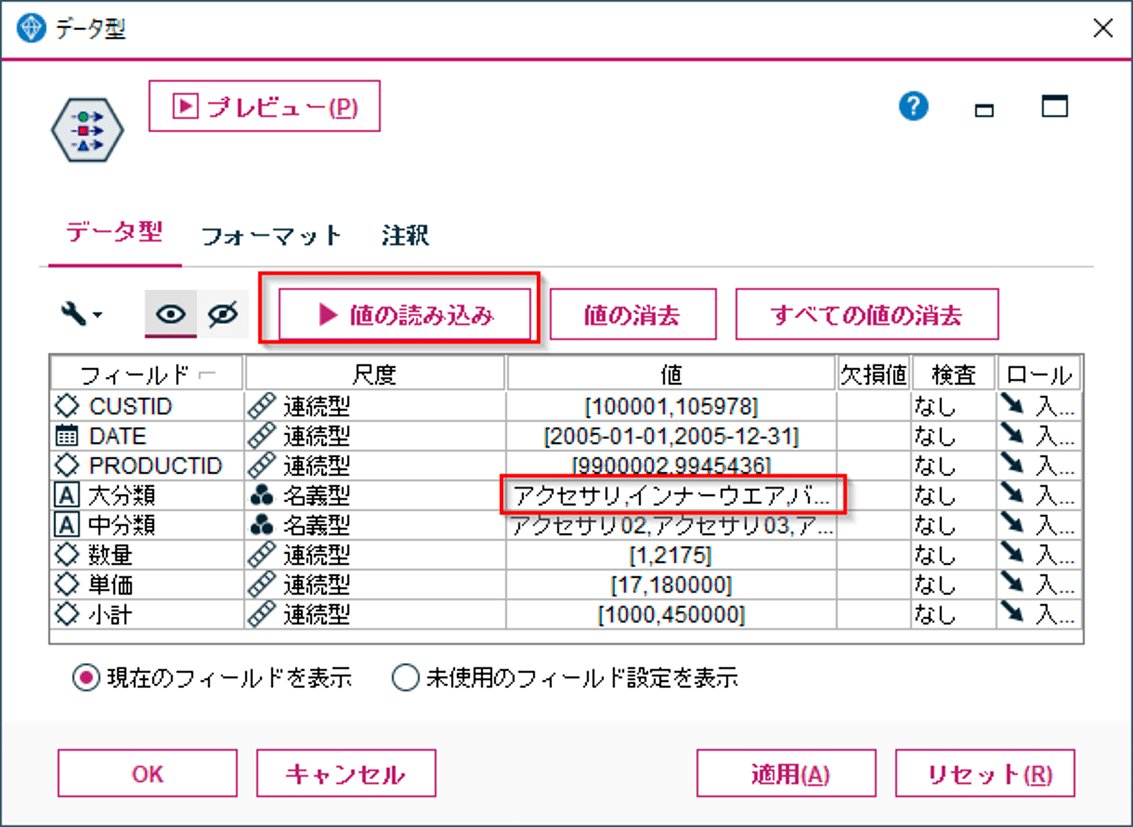
まずデータ型ノードで商品分類にどんなカテゴリ値があるかを認識します。データ型ノードで「値の読み込み」を行うと、自動で大分類のすべてのカテゴリが認識されます。
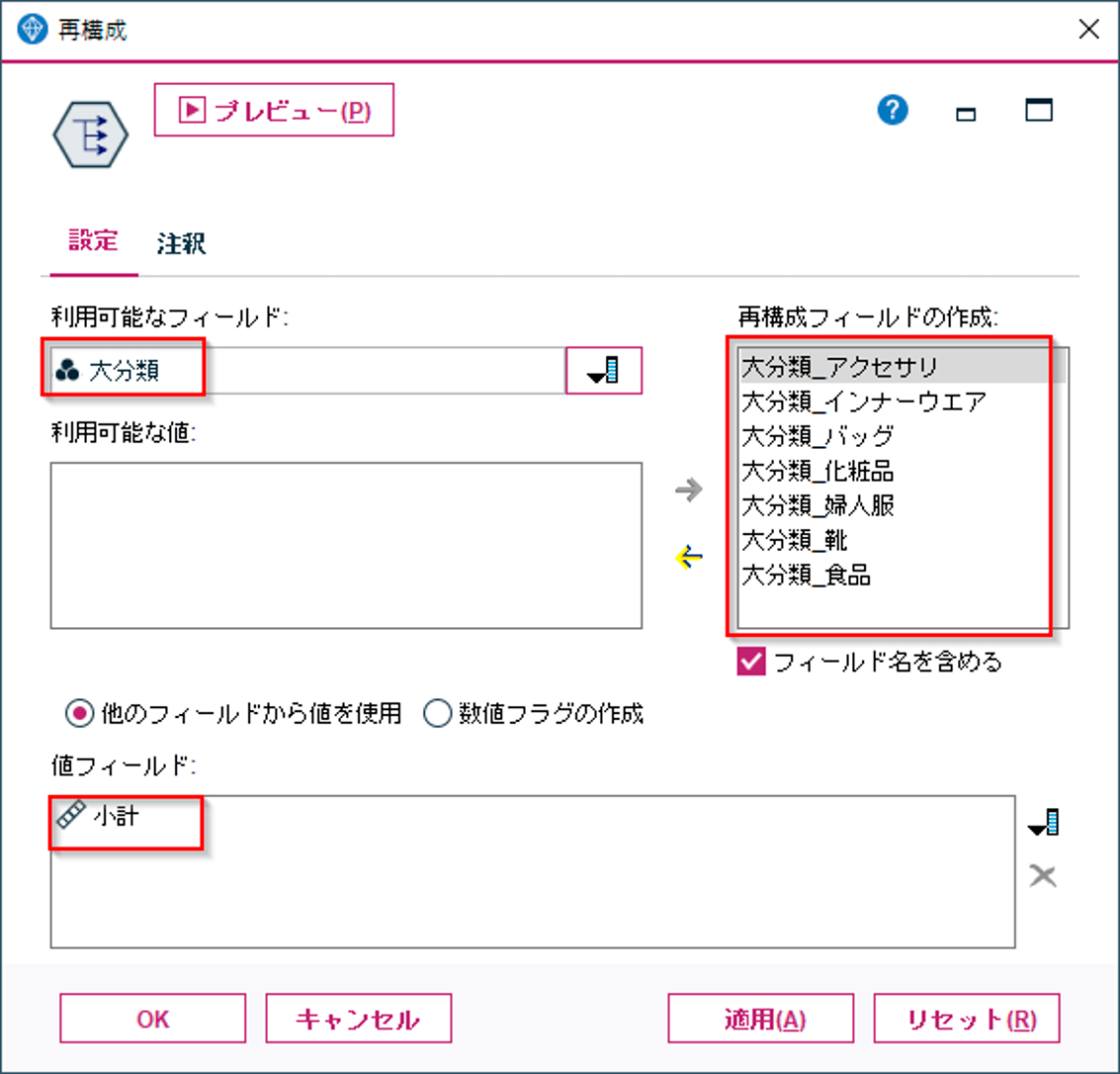
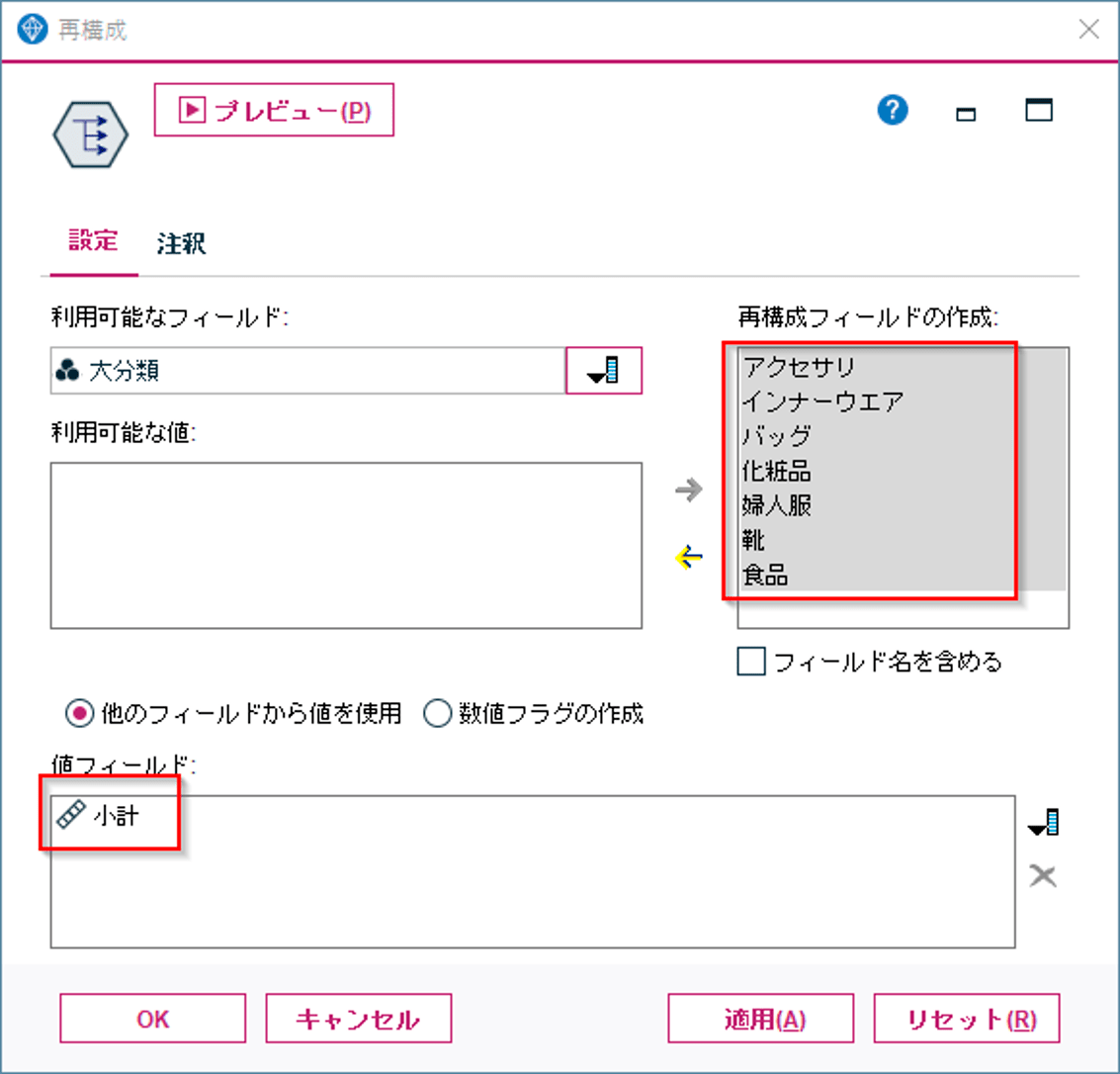
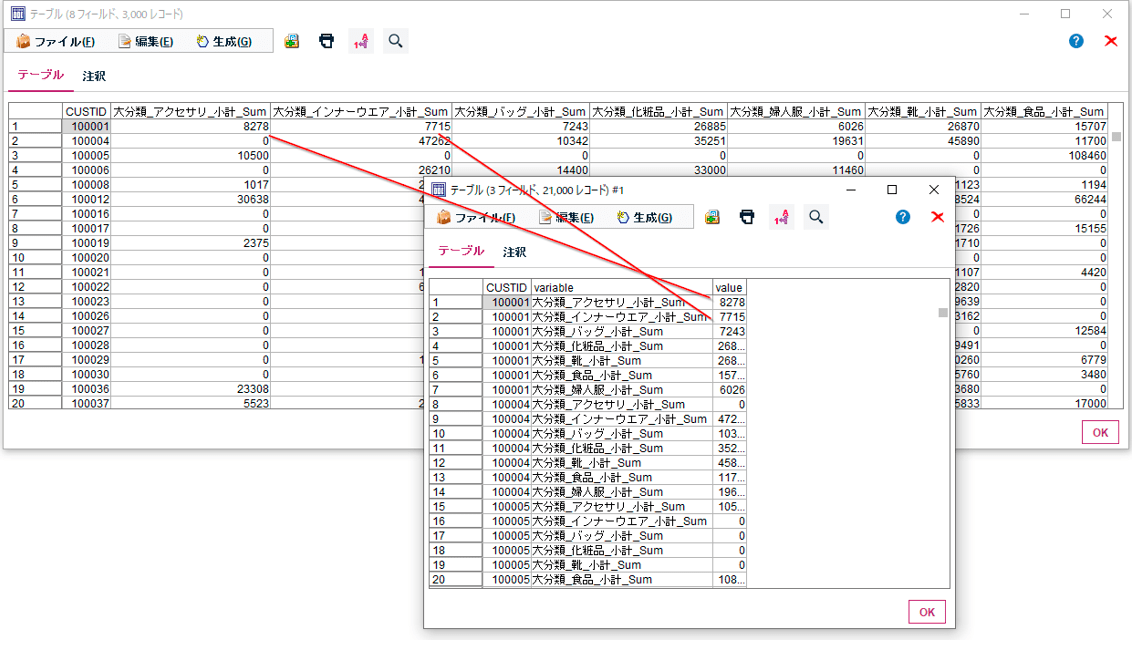
次に再構成ノードで横持させたいフィールドの値を選びます。以下の例では商品大分類にはアクセサリ、インナーウェア、バッグ、化粧品、婦人服、靴、食品があり、これらを列として展開して値には「小計」をセットしています。
この設定の結果は以下のようになります。小計が各商品大分類の列に振り分けられたことがわかります。

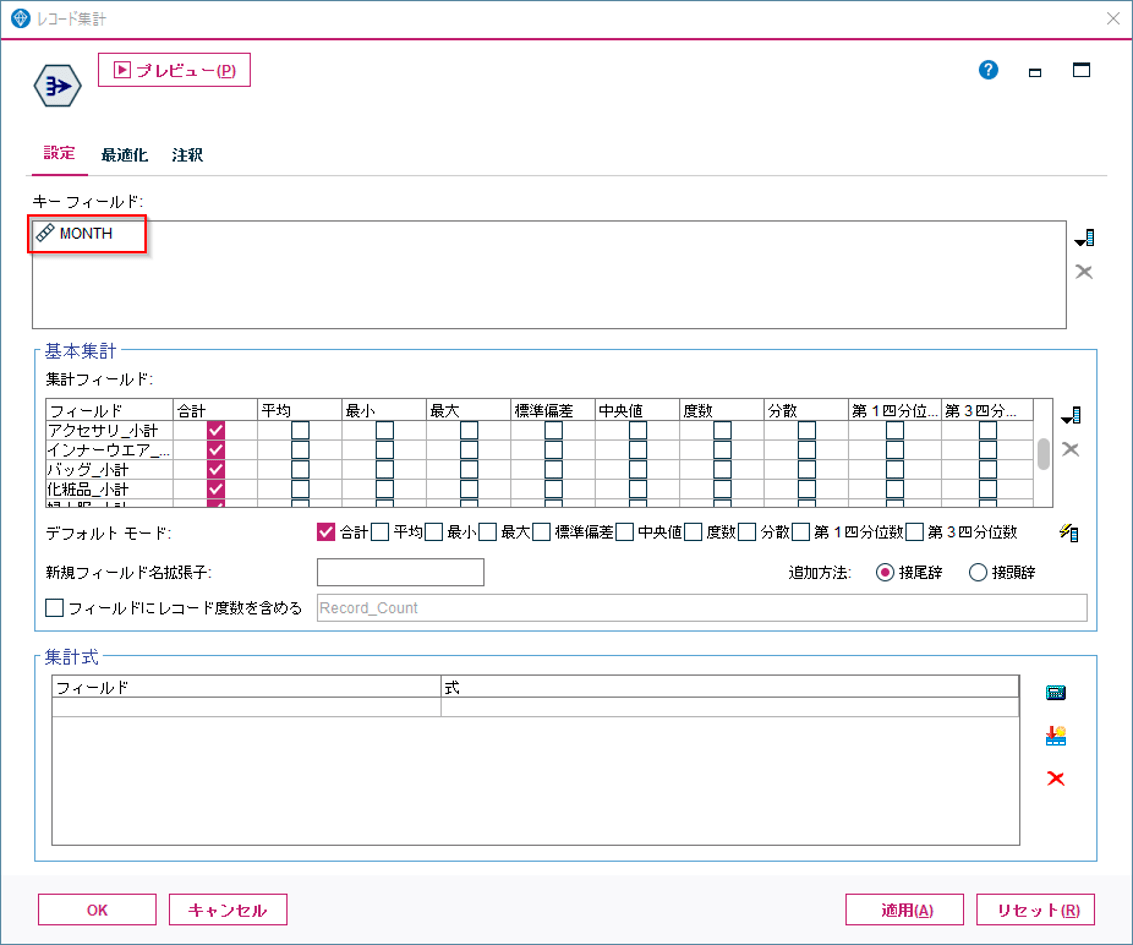
次に「レコード集計」ノードをつかってこの各商品大分類の小計値を顧客で1レコードに集計します。
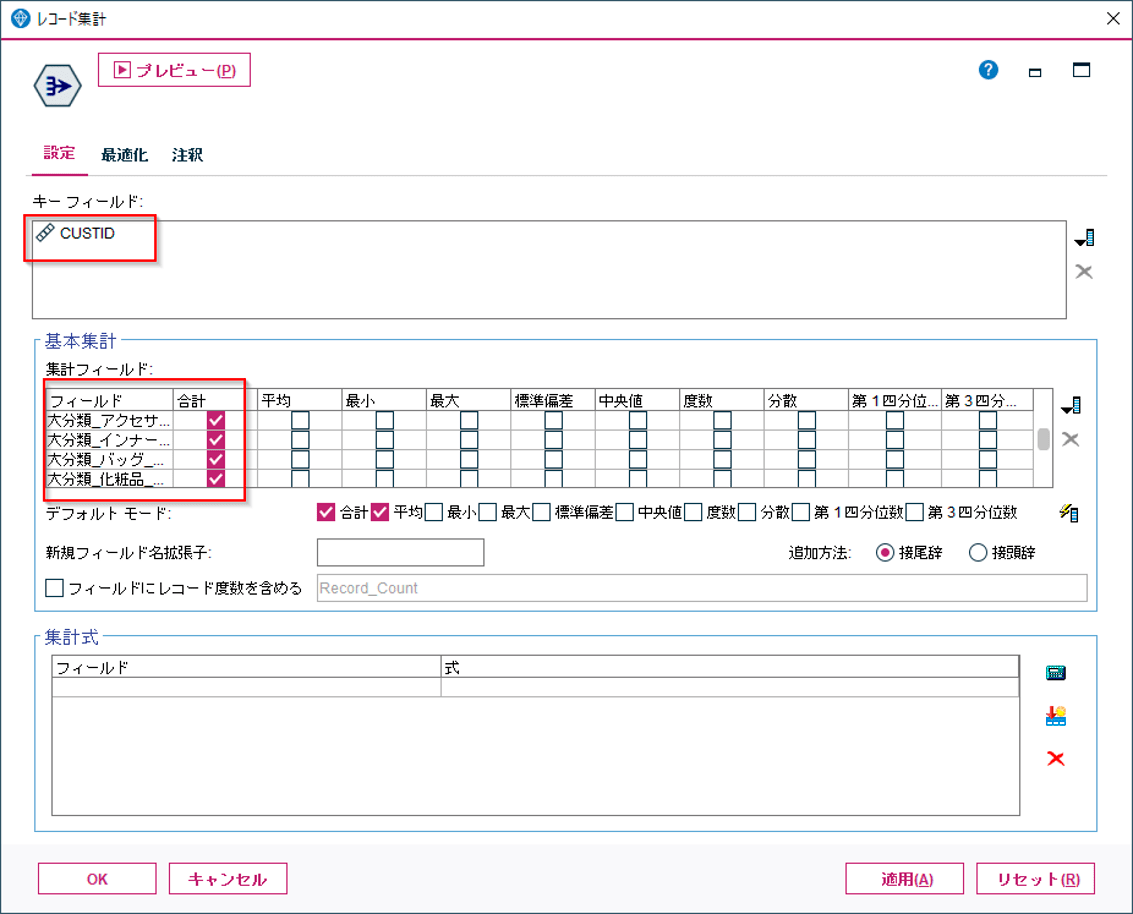
結果は以下の通りです。顧客毎に商品の大分類毎に合計購入金額がでました(ここでは合計ですが平均などの別の統計量で集計も可能です)。
顧客ID100001は化粧品と靴をいずれも27000円くらい購入しています。
一方で、顧客100005は食品で10万円くらい購入していますが、他のジャンルでの購入はほとんどありません。
このように、ID付POSの縦持ちデータのままではわからなかった、商品ジャンルごとの購買傾向がわかることで各顧客がどんなものを求めているか把握できます。
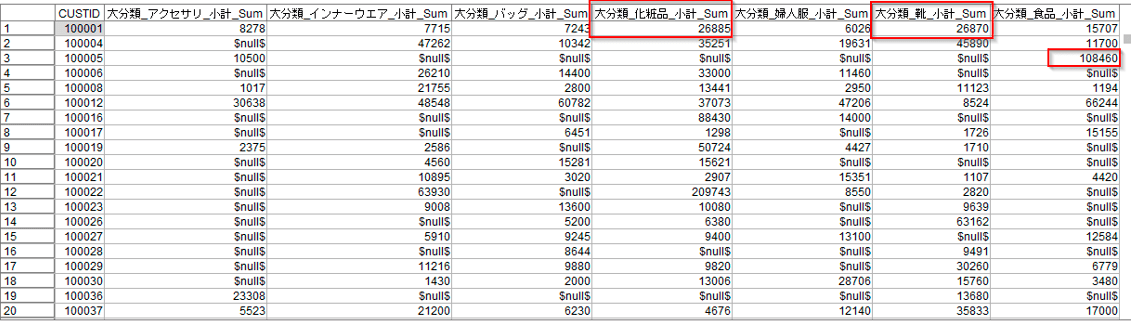
さらに以下のようにクラスター分析を用いると大分類毎の購買類似性によって顧客を分類できます。このように購買行動が近いクラスターを識別し、その特徴に応じた施策を展開すると顧客全体に同一の対応をするよりも高い販促効果を期待できます。
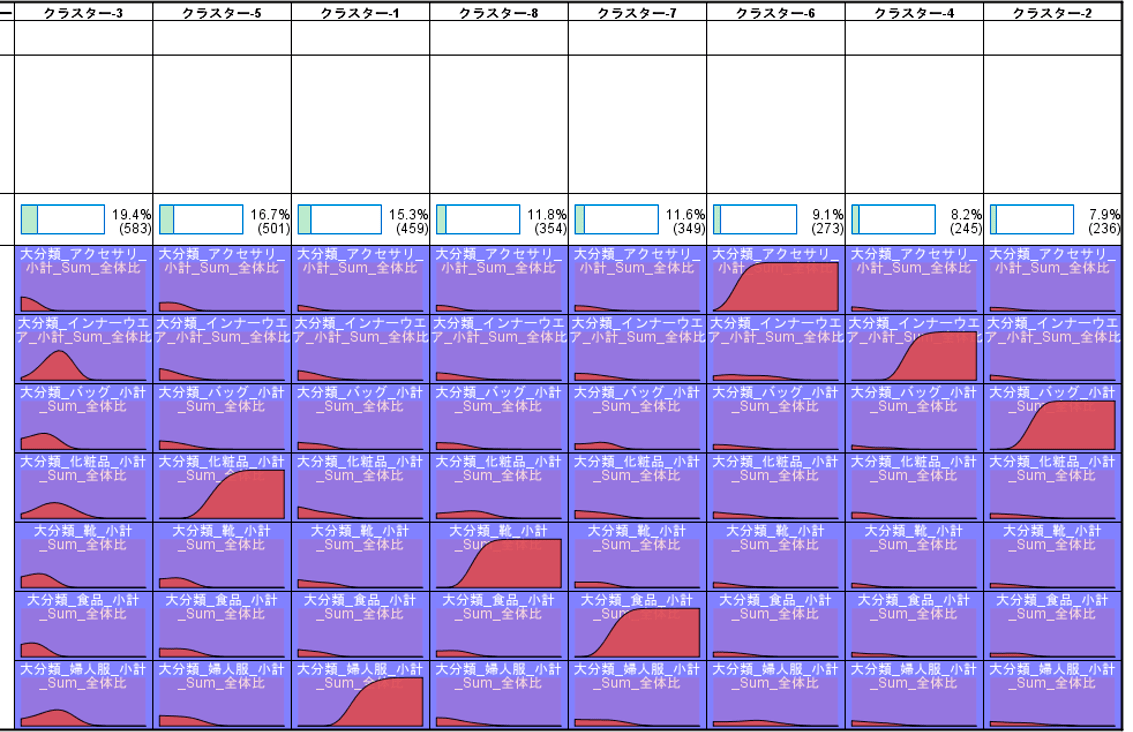
また再構成ノードはさまざまな集計を行いたい場合にも役に立ちます。例えば、月毎の商品大分類別の売上合計のクロス集計表をつくってみます。
再構成ノードの設定は先ほどと同じです。
次のレコード集計でMONTHをキーにレコード集計をすることでクロス集計が完成します。
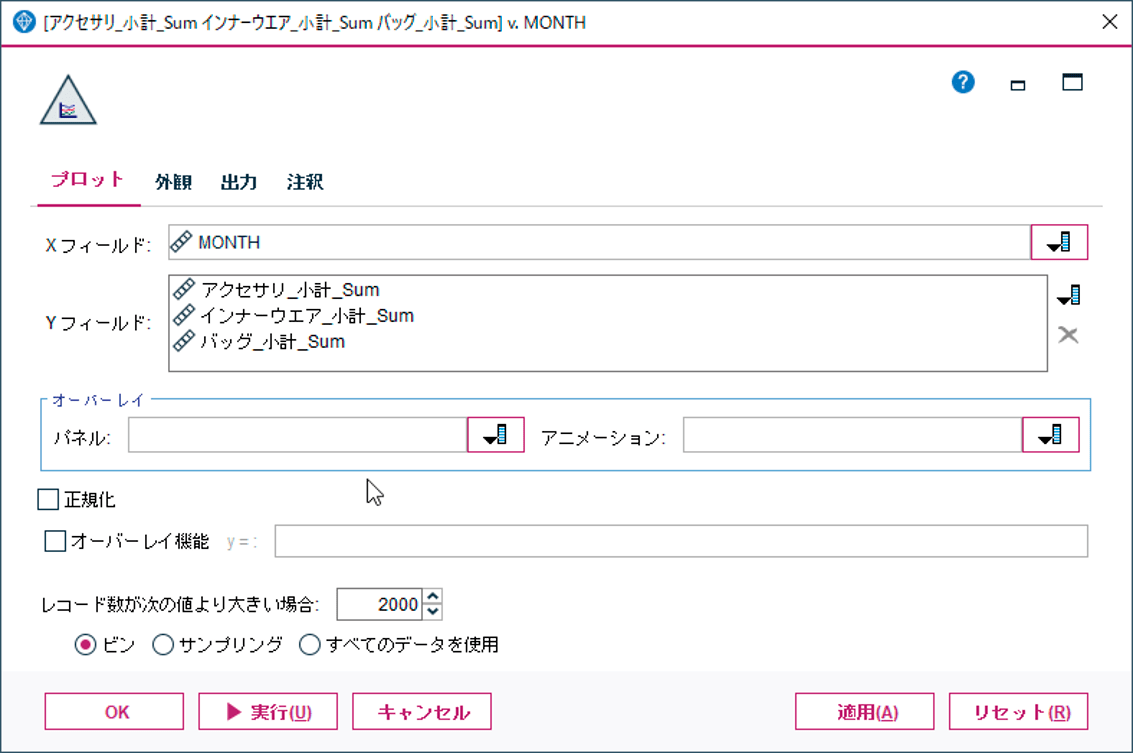
単純にクロス集計表を作りたいだけであれば、クロス集計ノードを使えばよいのですが、クロス集計ノードはターミナルノードなので、それ以降の加工や処理が行えません。再構成ノードと集計ノードを使えばその後に加工や別の処理が可能です。グラフを実際に作ってみます。
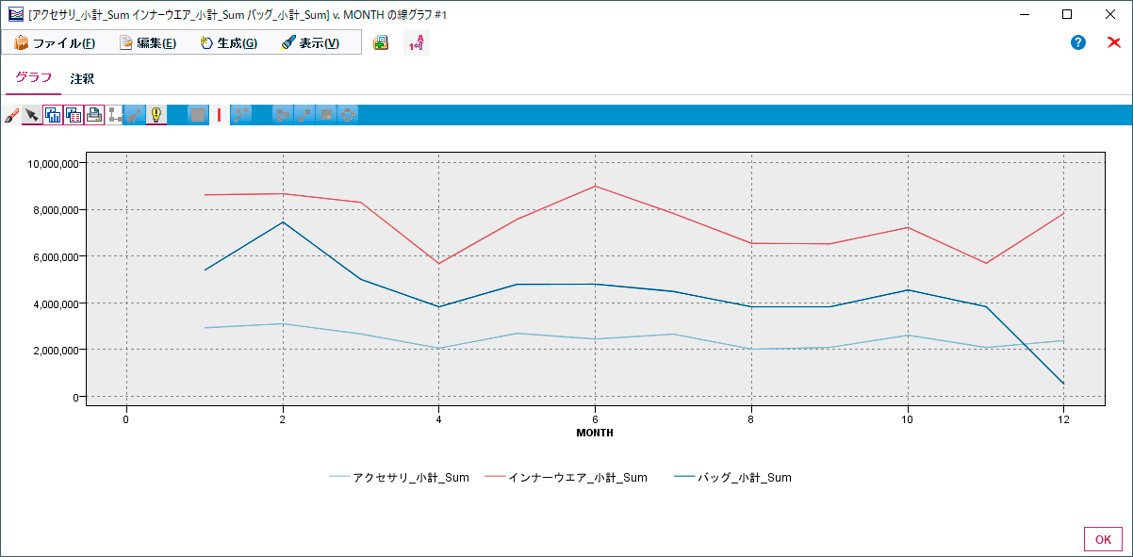
X軸に月(MONTH)を設定、アクセサリとインナーウェア、バッグの月別売上推移をみるグラフを線グラフノードで描いてみます。
バッグが2月に売れて以降、売り上げが下がっていっていることがわかります。クロス集計表だけでは捉えにくい傾向もグラフによってわかりやすくなりました。
ここまで再構成ノードはID付POSデータの特徴量抽出や基礎的な加工で役に立つことをご紹介しました。他にもさまざまな用途で活用できます。
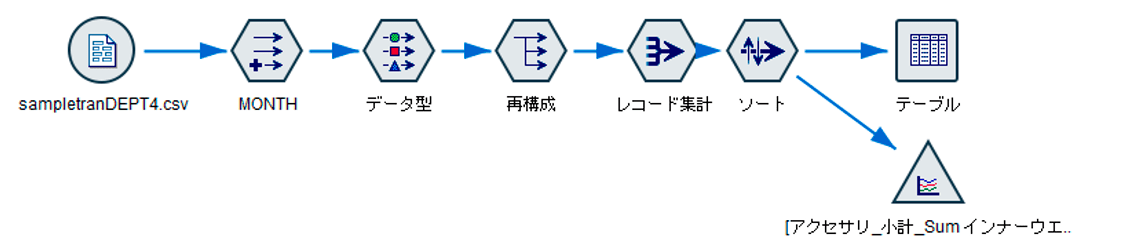
例えば装置のセンサーデータ分析での、縦持ちセンサーデータの横持ち加工があります。センサーデータは取得項目数が増減することがあるので縦持ちしていることがあります。
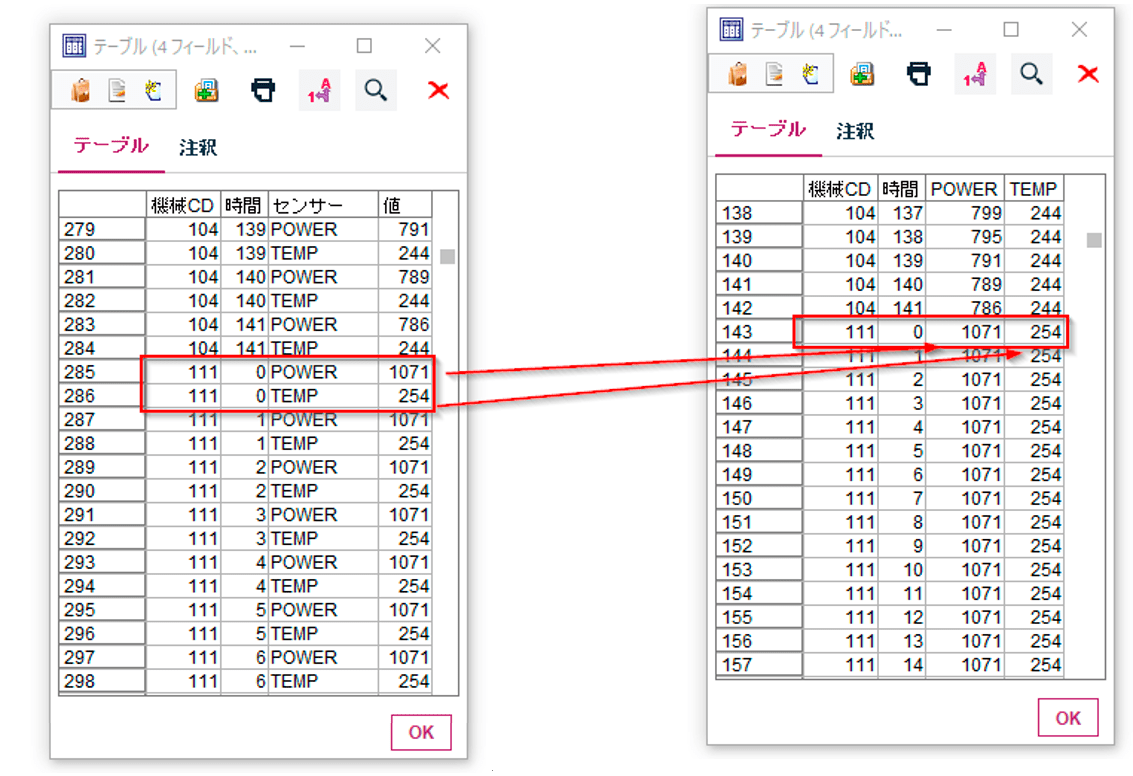
以下のデータでは、機械が出力する温度(TEMP)と電力(POWER)のセンサーデータの2レコードが毎時記録されています。これを1レコードに変換することができます。
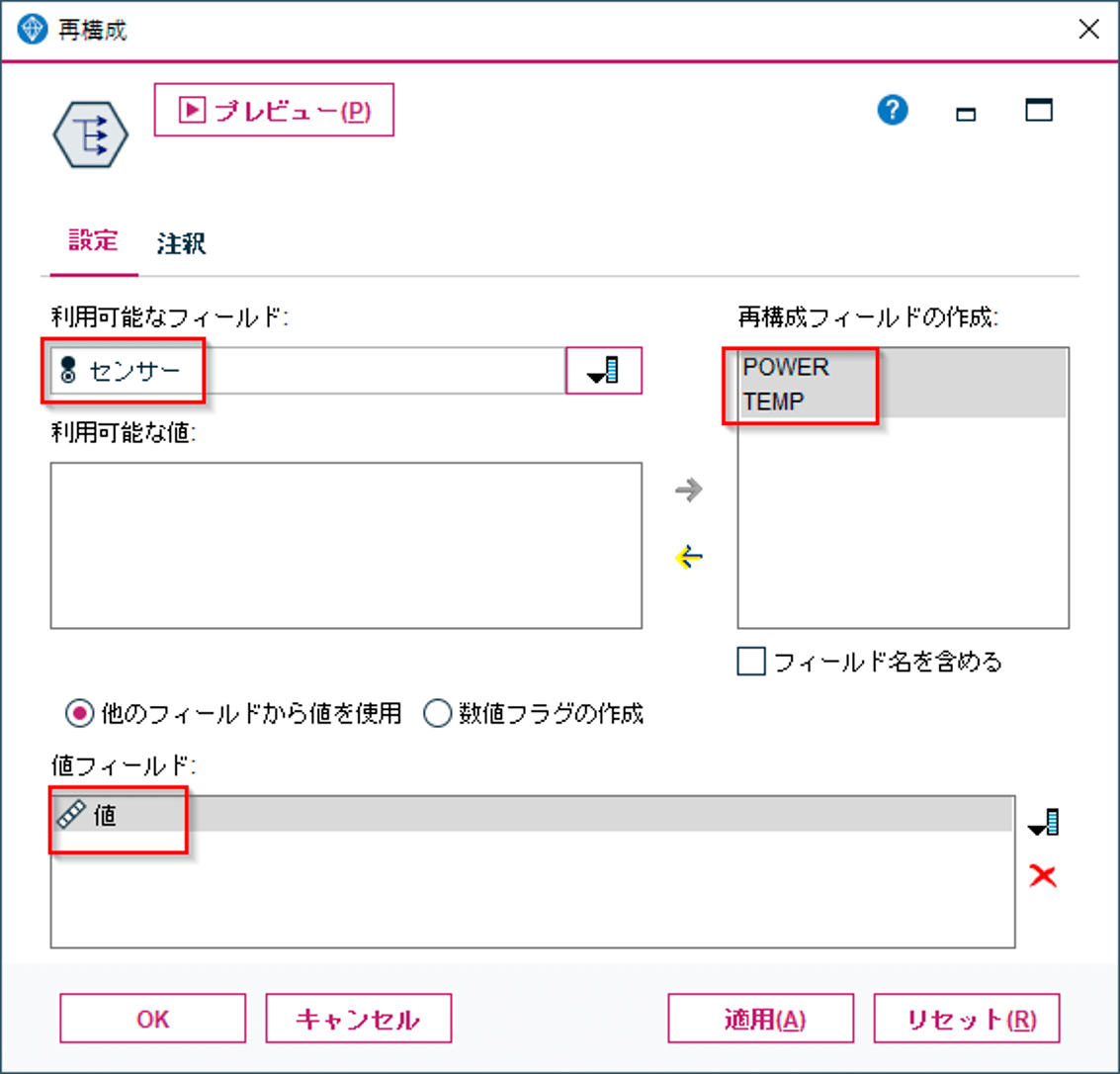
再構成ノードの設定は以下のようにしています。POWERとTEMPで新しく列をつくっています。
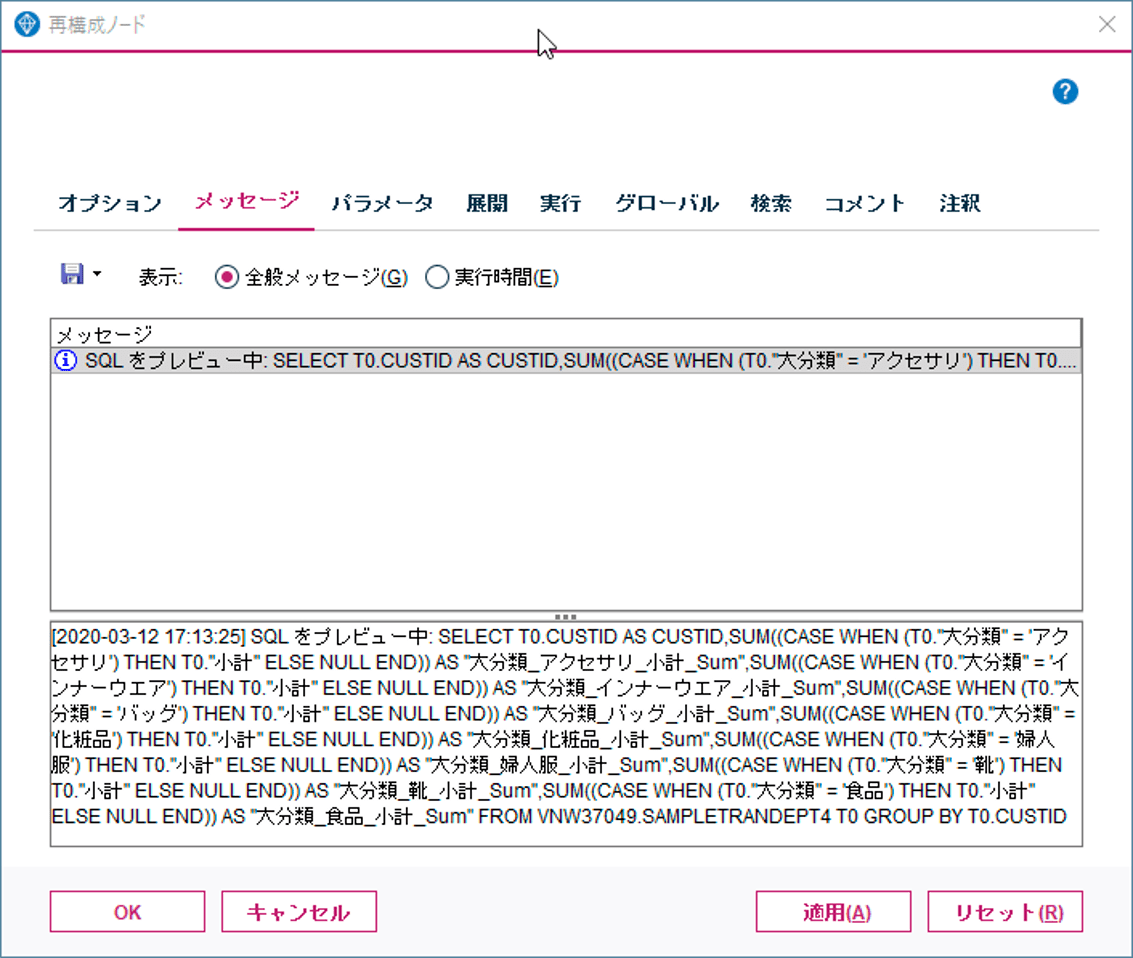
再構成ノードのさらにすごいところはその処理がSQLプッシュバック可能なところです。SQLプッシュバックは、ストリームがそのままSQLに自動変換されてデータベースに処理を委ねる機能で、SPSS Modelerユーザーにはおなじみの機能です。

人手ではあまり書きたくない面倒なSQLを自動生成してくれます。列に展開されるカテゴリが多いほど、この機能的、時間的な恩恵が高まると言えます。
再構成ノードには似た機能を持つ仲間のノードがあります。先ほど触れたクロス集計ノードもその一つです。

そのほかにもフラグ設定ノードや縦横変換ノードがあります。
フラグ設定ノードは各カテゴリ値のレコードがあるかないかを判定してフラグを立てます。

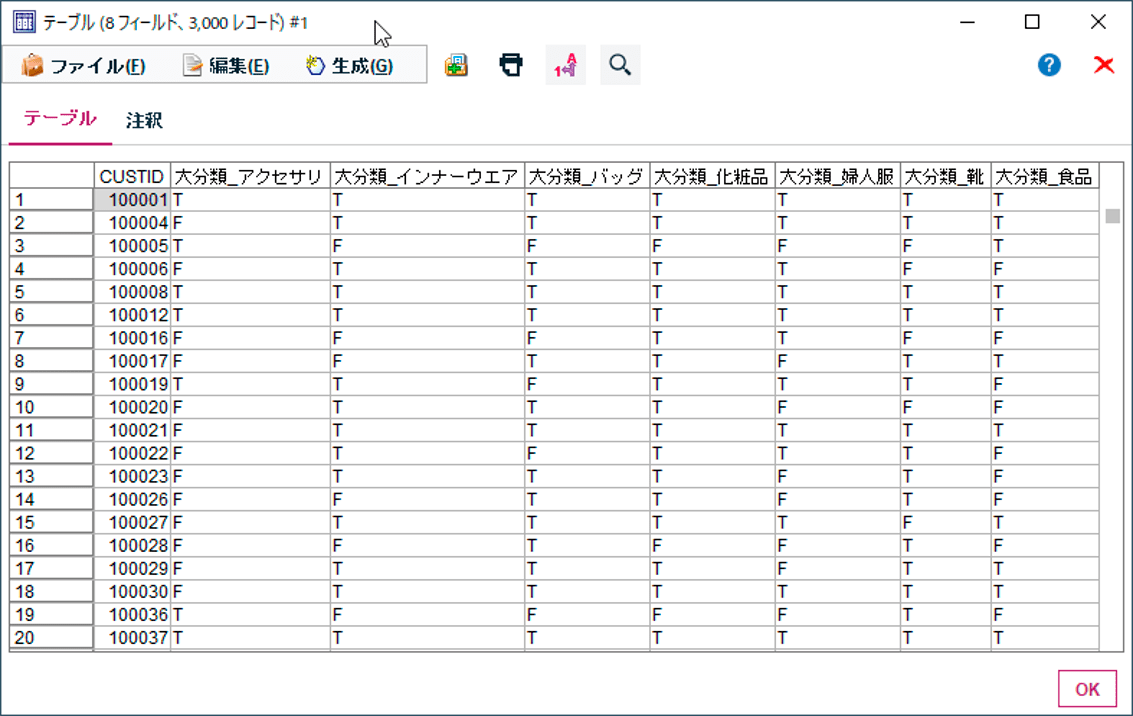
先ほどのID付POSデータで試してみると、再構成ノードと同じように、各大分類項目で列をつくるのですが、カラムには売上値ではなく、T か F の値が入ります。
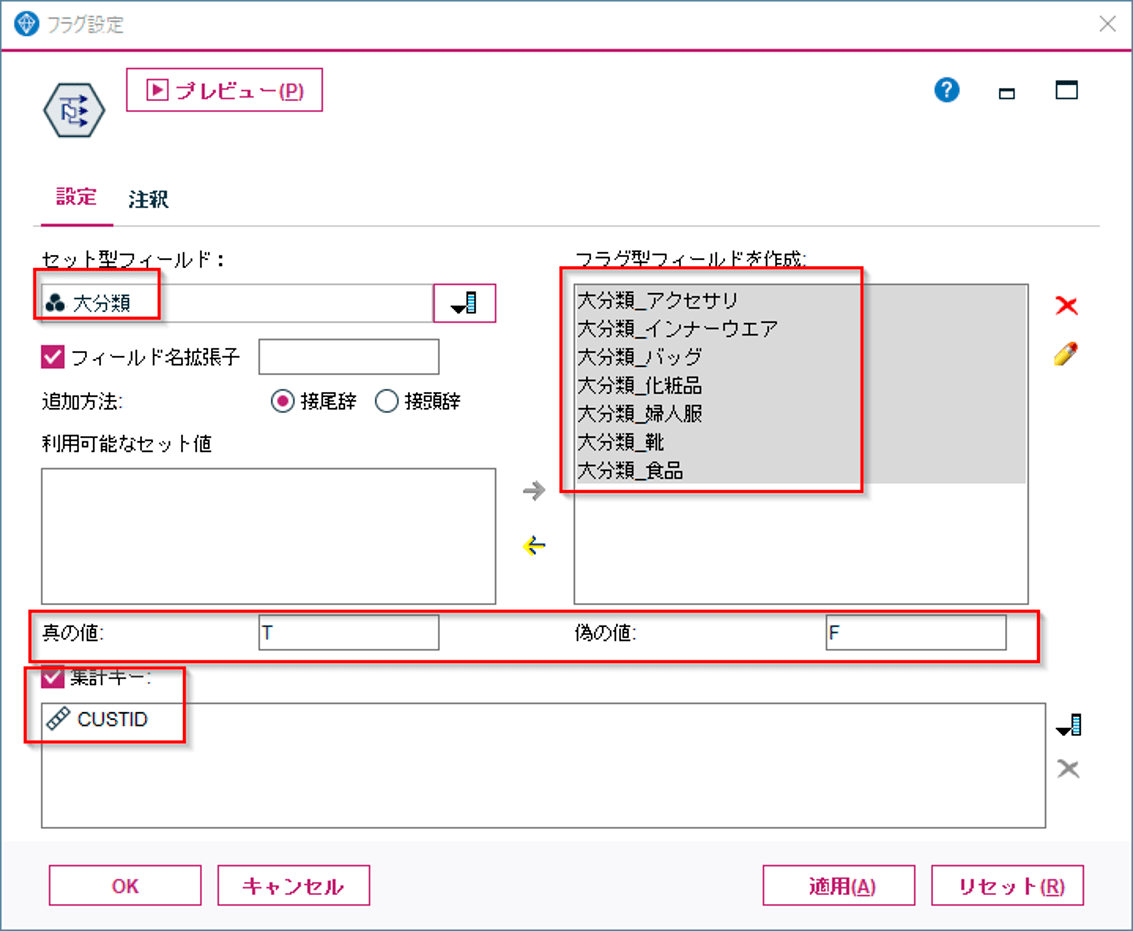
以下のように誰がどのジャンルの商品を買ったことがあるかをフラグ化できます。金額の情報までは不要であればフラグ設定ノードのほうがシンプルに使えます。
フラグ設定ノードはAprioriなどのアソシエーションのアルゴリズムの前処理によく使われます。
行列入替ノードは、再構成ノードで行う縦横変換と反対の横縦変換ができます。
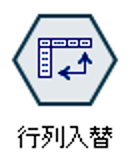
以下のように値として各列を指定すると、行として展開されます。
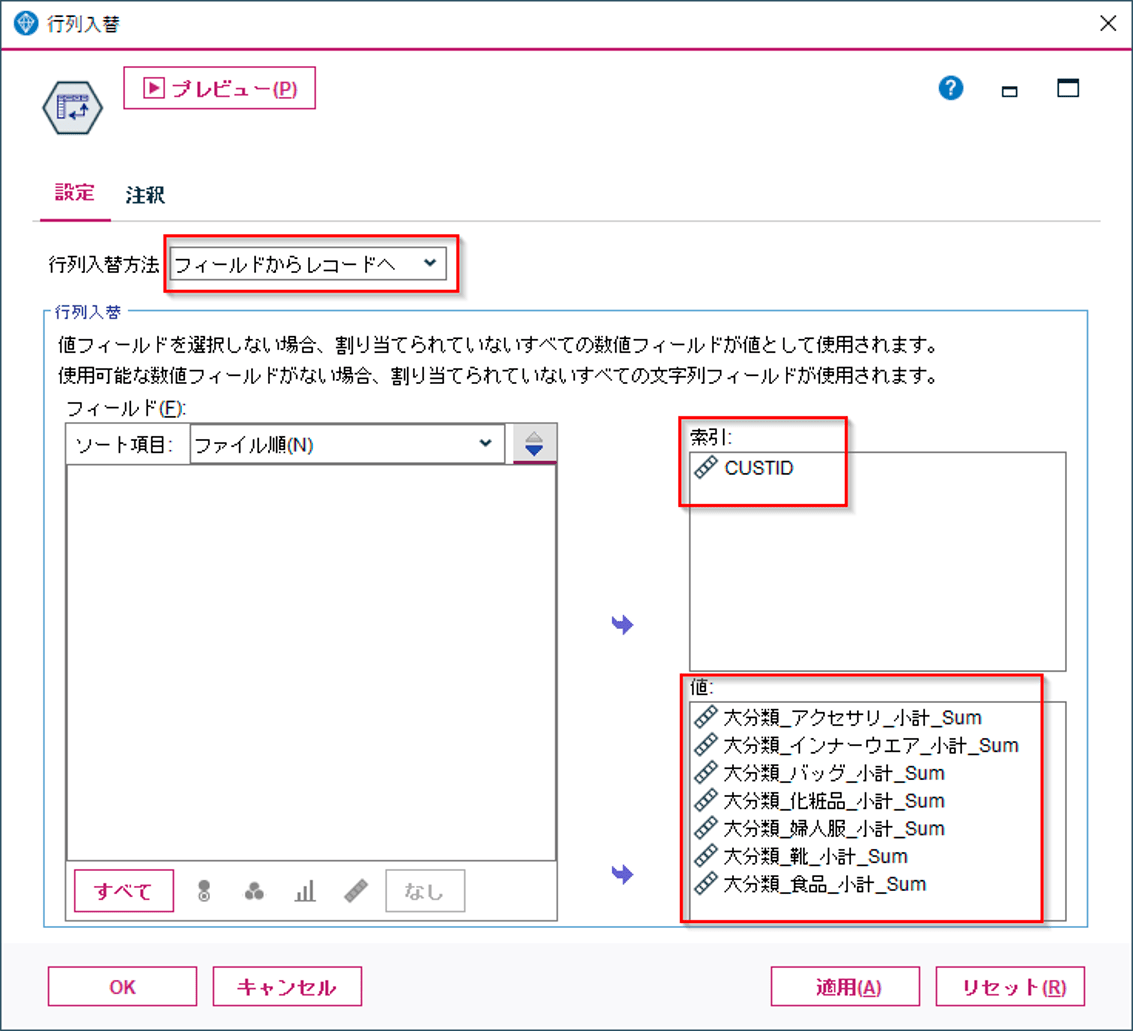
ちなみに実は行列入替ノードでも縦横変換ができるのですが、こちらはSQLプッシュバックが効かないので、縦横変換では、再構成ノードを推奨します。
時系列で顧客や設備の変化が記録される縦持ちのデータはシンプルですが、そのままアルゴリズムにかけられないものがほとんどです。分析者は、そこから目的に応じた知見・モデルを得るために無駄のない、スピーディーなデータ加工が求められます。また、その過程で作られる特徴量の良し悪しがモデルの精度を左右するため、何度も作り直す必要も生じます。ご紹介した「再構成ノード」はまさにそういった分析者の悩みを解決するスゴ技ノードであり、多くのユーザーの推しメンとなっています。是非使い込んでその良さを実感していただければ幸いです。
リレー連載次回推しノード#05は株式会社MAIの木暮様がデータの自動準備ノードを語ってくださいます!
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら
西牧 洋一郎
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス
著書に「実践IBM SPSS Modeler 顧客価値を引き上げるアナリティクス」

皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む