IBM Data and AI
MLOpsのキホンと動向
2021年07月09日
カテゴリー Data Science and AI | IBM Data and AI | IBM Watson Blog | データサイエンス
記事をシェアする:

MLOpsとは、DevOps + ML(Machine Learning : 機械学習)の造語で、機械学習モデルやAIモデルを一度作っておしまいではなく継続的に本番運用していく仕組みや考え方を指します。昨今のAIブームで、様々な実業務において機械学習/AIモデルが活用されています。しかし、一度作ったモデルが永遠に使い続けられるわけではありません。モデル作成した時とは環境や社会が変わり、データが徐々に変化していくとモデルの予測精度は劣化していきます。例えば30代に売れていた商品が、時間の経過に伴い40代に売れるようになっていたということがあれば、30代に売れることを予測していたモデルの性能は劣化します(厳密には変化しているのはデータの方ですが、モデルがその変化に追随できず予測が外れていくということです)。そのため、データの変化その他に適用するようにモデルを定期的に再学習させるなど、運用を考慮した仕組みが必要です。その仕組みや考え方を総称したものがMLOpsです。
巷にはMLOpsを謳う製品やOSSライブラリが多く登場してきていますが、MLOpsは非常に広い概念であるため、具体的にどのような機能を提供しているのかをひとつひとつ見極めていくことが重要です。当記事では、MLOpsの全体像を示したあと、OSSやIBMのクラウド製品の最新動向に焦点を当てて解説します。
MLOpsのキホン
機械学習/AIモデルは、学習データ(過去データ)から学習アルゴリズムを実行することで生み出されます。学習済モデルの実体は学習データの傾向を要約したメタ情報を持つファイルです。この学習済みモデルは、現在&将来のデータに適用(スコアリング)することで予測値を算出します。
MLOpsの全体像を図1に示します。①モデル作成・パイプラインは、学習データからモデルを作成する一連の処理です。②スコアリング・パイプラインは、モデルの本番運用すなわちスコアリング実行を行う一連の処理です。③モニタリング・パイプラインは、本番運用されているモデルの予測精度が劣化していないかどうかを確認する処理で、②と同様にモデルをスコアリング実行した結果の予測精度を評価する処理、及びその精度に基づいて人が精度劣化を判断するワークフローなどが含まれます。④モデルリフレッシュ・パイプラインは①とほぼ同じ内容で、本番運用モデルの精度劣化が発生した場合にモデルの再学習を行う処理を指します。パイプラインはオーケストレーション、フローなどとも呼ばれますが、複数の処理やプログラムを一連の流れとして処理するものを指します。
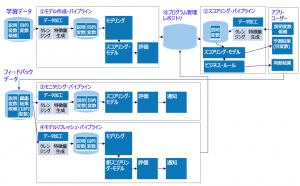
図1. MLOpsの全体像
MLOpsの動向1 : MLFlow (Python&Rライブラリ)
PythonやRなどのデータ分析言語においても、MLOpsを支援するためのOSSの便利なライブラリがいくつか存在します。OSSのライブラリはMLOpsに関する部分的な機能をカバーしているものが多いため、前述のMLOps全体像の中で特に重点的に強化したいところから該当するツールを選択していくことがポイントとなります。
MLflowはDatabricksが開発した機械学習ライフサイクル管理ツールであり、PythonおよびRのOSSライブラリとして入手可能です[1]。MLflowの特徴は以下の3点です。
- 実験管理というモデル学習・評価・スコアリングの実行記録を行うことで、過去の実行結果の参照や再現が可能になります。
- 標準で管理UIがあり、Webブラウザで実験管理の結果を視覚的に確認できます。
- レポジトリでのバージョン管理と、ラベルによる運用対象バージョン管理が可能です。
以下でこれらの特徴を説明します。MLflowは主に4つの機能(図2)から成っていますが、中でもMLflow Trackingという実験管理が得意分野です。実験管理とは、モデル学習や精度評価など何度も条件を変えて繰り返す試行(実験)を記録し、条件とモデル精度の関係などの実験結果の比較をしやすくするための機能です。機械学習モデルを作成したことがある方は経験があると思いますが、何度も学習データ(特徴量セット)や学習アルゴリズムのハイパーパラメータを変更しながらモデル開発を試行錯誤したことがあると思います。ひとつの学習データセットに対してであれば、例えばPythonのscikit-learnにあるグリッドサーチ機能を使うことで複数のハイパーパラメータに対する試行錯誤を自動化し最適なハイパーパラメータを求めることが可能ですが、学習データも何度も作り直しながら試行錯誤する場合はやはり手作業となり、それらの試行錯誤の条件と結果がどうだったのかを記録しておく必要があります。筆者もExcelにその試行錯誤を記録していた経験がありますが、何度も学習と評価を繰り返すうちに「どの条件で作成したモデルが一番良いのか」「この時作成したモデルのパラメータとデータは何か」を見失ってしまうこともありました。MLflow Trackingの実験管理は、このような試行錯誤(実験)を統一的に管理し、さらにその結果を視覚的に見やすくしてくれる秀逸な機能です。

図2. MLflowの主要4機能
MLflow Trackingでは、Tracking Serverという常駐の管理サーバーを起動し、Python or Rの機械学習モデル開発プログラムの中からMLflowのAPIを用いてモデル学習や評価の結果をTracking Serverに記録する仕組みとなっています(図3)。

図3. MLflow Trackkingの実験管理の仕組み
学習や評価のPythonコードからのMLflow APIの利用イメージを図4に示します。この例ではscikit-learnのDecisionTreeClassifierを用いて決定木モデルを再生し(学習)、そのモデルの正解率を計測(評価)した後、MLflow APIの”start_run”でMLflow Tracking Serverへ以下の情報を記録しています。
- log_param モデル学習に使ったパラメータ(max_depth)
- log_metric モデル精度評価結果(accuracy)
- log_model 学習後のモデル本体
- log_artifacts その他ファイル(学習データ)
また、register_modelで学習後のモデルをモデルレジストリ(MLflow ModelsおよびMLflow Registry機能)へ新規バージョンとして登録しています。
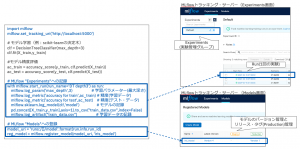
図4. MLflow Tracking Serverへの実験記録の例(Pythonの場合)
MLflow Tracking Serverに記録された実験(学習や評価)の結果は、MLflowの管理UI上で比較することが可能となっています。例えば、学習パラメータや学習データを変更した3種類のモデルを作成し、各々のモデル精度評価を行った3つの実験記録をMLflow管理UI上で比較表示する(図5)ということが可能です。棒グラフや散布図など、視覚的に精度評価指標を比較できる機能が標準で備わっていることがMLflow Trackingの大きな強みと言え、筆者も実案件においてモデル開発〜モニタリング〜モデルリフレッシュを行うMLOpsシステムの主要コンポーネントとして組み込んで活用したことがあります。
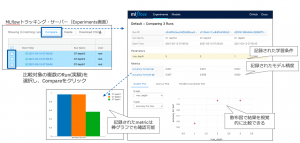
図5. MLflow管理UI上での複数の実験結果の精度比較
なお、MLflowはパイプライン処理の機能はありません。前処理を含むモデル作成・スコアリング・モニタリング・モデルリフレッシュなどのパイプライン処理は、独自のPythonコーディングあるいは別のツールを活用する必要があります。
前述のMLOps全体像において、MLflowがカバーする機能をマッピングしてみると図6のようになります。主要なカバーエリアは次のA,B,Cの3箇所です。
A. 実験管理 – 学習後のスコアリングモデル、学習条件である各種パラメータ、モデル精度評価指標(メトリック)、学習データ等その他の任意のファイルを実験に紐付けて管理することが可能
B. モデルレジストリ – モデルのバージョン管理、リリースタグ管理
C. スコアリングランタイム – Flaskを使ったスコアリングモデルのリアルタイム型実行環境
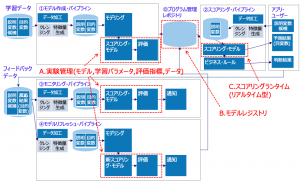
図6. MLOps全体像におけるMLflowのカバーエリア
MLOpsの動向2 : DVC (Pythonライブラリ)
DVC (Data Version Control)は学習や評価の試行の繰り返しの中で大量に生み出されてしまうモデルやコード、データなどの各種機械学習ファイル群をバージョン管理するPythonライブラリです[2]。バージョン管理としてはGitが有名ですが、DVCはGitを補完するような機能を提供します。DVCの特徴は以下の3点です。
- Gitと連携し、学習や評価に使ったモデルファイルだけではなく、データもバージョン管理できます。
- データの格納場所として各種ストレージサービスが利用でき、大量の画像などの大きなサイズのデータを扱うことが得意です。
- パイプライン処理の記述と実行を行い、再現試験を支援します。
機械学習では大量の画像などの大きなサイズのデータを扱うことがありますが、データそのものはDVCのリモートストレージに格納しGitにはそのメタ情報のみを管理するという組み合わせにすることで、大容量なデータも効率的に管理することが可能となっています(図7)。DVCは、基本的にGitライクなコマンドラインインタフェースで操作を行います。MLflowのようなGUI画面はありません。
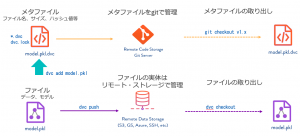
図7. Gitと連携したDVCによるモデルやデータのバージョン管理のコマンド操作
DVCの大きな特徴のひとつが、パイプラインです。データの前処理・学習・評価などの一連の処理をdvc.yamlというYAMLファイルに定義します。YAMLファイルの定義はエディタで一から記述していくことも可能ですが、各処理ステージに該当するコードや出力ファイルなどをオプション指定したdvc runコマンドを実行することで自動生成できます。dvc.yamlに定義されるのは、パイプラインの各ステージで実行するコマンドや前提となるファイル、実行結果として出力されるファイルなどです。dvc reproコマンドでdvc.yamlに定義された一連のパイプライン処理が実行されます(図8)。このようにYAMLファイルに処理を記述していく性質があるため、DVCのパイプラインはモデル学習の煩雑な試行錯誤フェーズではなくある程度処理の流れが固まったモデル再学習や評価という定型的なタスクが使いどころであると言えます。
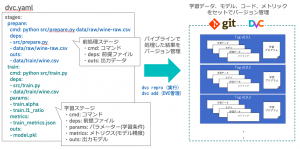
図8. DVCのパイプライン定義(YAML)とdvc reproコマンドによる実行
注意したいのはDVCとGitリポジトリの関係です。ひとつのGitレポジトリ配下で複数のDVCパイプライン定義を管理したいケースです。ひとつのGitリポジトリ配下にDVCが管理する(dvc initされた)複数のディレクトリを作成して複数のパイプライン定義dvc.yamlをバージョン管理することは可能ですが、そのパイプライン処理で使用するソースコードやデータなどのファイルは基本的に各DVC管理ディレクトリ内である必要があります。例外的にexternalオプションをつけることでDVC管理ディレクトリ外のファイル(例えば親ディレクトリにおいたデータやソースコード)をDVC管理に含める事も可能ですが、データファイル本体をGit管理外にするための.gitignoreファイルが自動生成されないため、適切にGitバージョン管理するために.gitignoreを何度もメンテナンスする必要があります。これは少々トリッキーな使い方を要求されます。
他にもステージの並列実行は制御できない(並列実行したい場合は各々をdvc reproコマンドで実行する必要がある)という制約もあるため、DVCのパイプライン機能は比較的簡易的なものと考え、本格的なパイプライン処理を実装するのであればKubeflowなど別のツールを検討するほうが良さそうです。
前述のMLOps全体像へDVCの機能をマッピングしたものが、図9です。主なカバーエリアは次のA,Bの2箇所です。
A.パイプライン定義と実行 – モデル作成(学習と評価)、スコアリング(実行)、モニタリング(評価)、モデルリフレッシュ(学習)などのパイプライン処理の定義
B.プログラム管理レポジトリ – モデル、パラメータ、コード、データなどの機械学習リソースのバージョン管理
図9を見るとDVCのカバーエリアは広く見えますが、パイプライン処理の個々の処理内容(前処理・学習・評価など)はユーザーがコードを書く必要がある点にご注意ください。
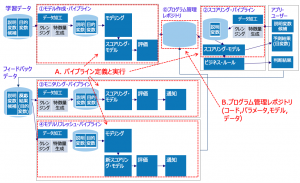
図9. MLOps全体像におけるDVCのカバーエリア
MLOpsの動向3: IBM Watson Studio + Machine Learning + OpenScale
Watson Studio、Machine Learning、OpenScale は、IBMのCloud Pak for Data[3]というデータの管理基盤のデータ分析に関する機能群です。Watson Studioはモデル作成、Machine Learningはスコアリング基盤、OpenScaleはモデルのモニタリング基盤です。これらを組み合わせることでMLOpsが実現できます。Watson Studio + Machine Learning + OpenScaleの特徴は以下になります。
- 機械学習やディープラーニング、SPSS Modelerのモデルなど様々なタイプのモデルに対応可能です。
- APIによる連携が柔軟な連携が可能です。
- ROCなどのモデル性能の評価以外にも公平性のモニタリングやドリフトのモニタリングが可能です。
Watson Studioでは、Jupyter Notebookを使ったPythonやSPSS Modeler互換ツールのModeler Flowでモデルを作成することができます。PythonではScikitlearnやTensorflowなど人気のあるフレームワークに対応していますので、幅広い機械学習やディープラーニングのアルゴリズムに対応することができます。
実現の手順を示します。
まず①モデル作成のパイプラインは1つのNotebookにデータ加工、モデリング、評価の一連の流れを記述して作成することができます。作ったNotebookはプロジェクトに保存します。プロジェクトではバージョン管理は困難ですが、外部のGithubに保存することもできます。
次に、作ったモデルはMachine Learningにコピーしてデプロイし、REST API化することができます(特徴2)。②データ加工やビジネスルールはモデル作成時のNotebookを参考にしながらアプリケーション側で実装し、オーケストレーションします。
③モニタリング・パイプラインのメイン部分はOpenScaleを使って作ることができます。OpenScaleで監視対象のモデルやモニタリング対象指標を指定します。OpenScaleではMachine Learningで行ったスコアリング結果を自動的に保管する機能もありますが、フィードバックデータの加工はOpenScaleの中では行えないので、やはりモデル作成時のNotebookを参考に作成し、作った加工済みデータをOpenScaleにAPIで渡します。その後は評価から、通知までをOpenScaleが行います。Notebookでパイプラインを作った場合には、その自動実行にはWatson StudioのNotebookのジョブ実行機能があるのでそれをつかうと便利です。
④モデルリフレッシュも、モデル作成時のNotebookを参考に作成するのが良いと思います。通知機能は持っていないので、Pythonで作成することになります。さらに新モデルに自動的に置き換えていく場合はMachine LearningのAPIやOpenScaleのAPIをつかってそれぞれのモデルを置き換えていくパイプラインをPythonプログラムで作る必要があります。モニタリングと同様に、Notebookでパイプラインを作った場合はWatson Studioの機能でジョブ実行することができます。
前述のMLOps全体像へWatson Studio + Machine Learning + OpenScaleの機能をマッピングしたものが、図10です。主なカバーエリアは次のA,B,C,Dの4箇所です。
A. プロジェクト – Watson StudioでつくったNotebookやモデルはプロジェクト内のオブジェクトとして管理
B. Juypter Notebook – データ加工、モデリングなどを含む一連の処理とそのパイプライン
C. Machine Learning – モデルのスコアリングAPI化機能
D. OpenScale – モデルの評価
図10を見ると一通りカバーできているように見えますが、各パイプラインをPythonのプログラムとしてJupyter Notebookで作ることになります。しかしこれは、加工やモデリング、評価などの処理内容の重複したJupyter Notebookをプログラムで複数つくりこむことになります。筆者も各パイプライン処理をNotebookとして開発し、ジョブとして定時実行させる仕組みを作ったことがあります。
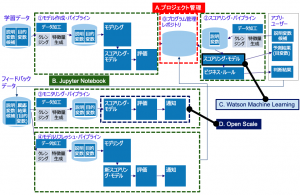
図10. MLOps全体像におけるWatson Studio + Machine Learning + OpenScaleのカバーエリア
なお、パイプラインをGUIで作成するOrchestration Flowという機能が、IBM Cloud上のWatson Studioで提供されました[4]。Orchestration Flow をつかうとWebブラウザ上で、ドラッグ・アンド・ドロップでNotebookなどの処理を部品として配置して矢印でつなぐという、グラフィカルな操作でパイプライン定義を作成できます(図11)。さらにNotebookだけではなく、Watson Studio内のData Refinery(データ加工)やModeler flow(SPSS Modelerでのデータ分析)のような別ツールで作った処理もパイプラインの一部として利用することができます。
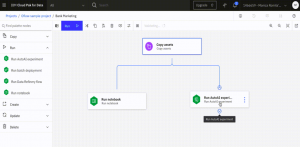
図11. IBM Watson Studio Orchestration Flowの操作イメージ
Orchestration Flowの裏側では、Kubeflow + Tektonがパイプラインのエンジンとして動いています。TektonはCI/CDのパイプライン機能を持つKubernetesネイティブなOSSで、Kubeflowはパイプライン機能だけでなく機械学習モデルの開発とデプロイのソフトウェア群を含むKubernetes上で稼働するOSSです。Orchestration FlowはこれらのOSSの力を借りながら、IBM Watson Studio上でユーザーが開発した個々のアプリケーションを組み合わせたパイプライン処理を提供します。
MLOpsの動向4 : Elyra (Pythonライブラリ)
最後に、IBMが開発に貢献しているMLOpsのOSSとして、Elyraをご紹介します。Elyraはパイプラインの定義作業を支援するOSSで、Jupyter Labの拡張機能として提供されています[5][6]。Jupyter Lab / Jutpyter Notebookは、データサイエンティストのPython機械学習のワークベンチとして非常に人気があります。Elyraは、Jupyter Lab環境にVisual Pipeline Editorというグラフィカルなパイプライン記述機能(図12)を追加することで、データサイエンティストが分析に使ったJupyter Notebookをそのままパイプライン処理に組み込んでいくことが容易になっています。
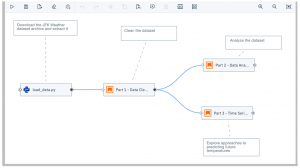
作成したパイプライン定義の実行環境としては、ローカルのJupyterLab環境だけでなく別途用意したKubeflowやApache Airflowの環境を指定することも可能です。ElyraはGitHubで公開されており、誰でも利用可能です。2021年7月時点でも活発に更新が行われており、今後の進化にも期待したいOSSです。
まとめ
当記事ではMLOpsのキホンとして全体像を解説し、Python/RのOSSライブラリやIBM製品・サービスにも組み込まれているMLOps機能を紹介しました。MLOpsで最も重要なポイントは、モニタリングです。つまり本番運用しているモデルが今のデータに対して適切な状態であるかどうかを継続的に監視していく仕組みが重要で、多くのケースにおいてはモデル運用者の判断というワークフローも伴います。一見賢いことをするAIも、ちゃんと監視していかないとある日から突拍子もない動きをし始める可能性があることを十分肝に銘じておく必要があります。
[参考文献]
[1] MLflow, https://mlflow.org/
[2] DVC, https://dvc.org/
[3] IBM: IBM Cloud Pak for Data 3.5.0, https://www.ibm.com/docs/ja/cloud-paks/cp-data/3.5.0
[4] Yair Schiff : Automating the AI Lifecycle with IBM Watson Studio Orchestration, https://medium.com/ibm-data-ai/automating-the-ai-lifecycle-with-ibm-watson-studio-orchestration-flow-4450f1d725d6
[5] GitHub : Elyra, https://github.com/elyra-ai/elyra
[6] Elyra Documentation, https://elyra.readthedocs.io/en/latest/index.html
IBM ProVISION なぜMLOpsが必要なのか,
https://community.ibm.com/community/user/japan/blogs/provision-ibm1/2021/08/17/vol97-0014-ai

日本アイ・ビー・エム株式会社
テクノロジー事業本部 ガレージテクノロジー本部
データサイエンティスト
都竹 高広
Takahiro Tsuzuku

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティ」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む

データ分析者達の教訓 #17- データ分析はチーム戦。個々がミス最小化の責任を持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。山下研一です。IBM Data&AIでデータサイエンスTech Salesをしています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活 ...続きを読む
データ分析者達の教訓 #16- ステークホルダーの高い期待を使命感と創意工夫で乗り越えろ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む