IBM Cloud Blog
分散クラウドとOpenShiftについて
2023年05月30日
カテゴリー IBM Cloud Blog | IBM Cloud News | IBM Partner Ecosystem
記事をシェアする:
こんにちは。IBM Cloud Platform Technical Sales坂田です。
今日は分散クラウドをテーマに話をします。
1.はじめに :分散クラウドとは?
今年のWBC(World Baseball Classic)で活躍した吉田正尚選手の所属するボストンレッドソックスがIBM分散クラウドサービスであるSatelliteの採用を決めたことが社内で話題になりました。
分散クラウドとは例えていうならば、クラウドがベンダーのデータセンターからお客様の拠点(データセンター,本社/支社など)に出張し、サービスを提供するものです。データをパフォーマンス(ネットワーク遅延)、セキュリティ、コンプライアンス等の理由から社外に持ち出せない時でもクラウドの方からお客様先に出向いてくれるサービスです。
ガートナーによれば分散クラウドとは、パブリックククラウドがさまざまな物理的な場所に“分散”され、提供元のパブリッククラウドプロバイダーが、分散されたサービスの所有、運用、ガバナンス、更新、進化に関する責任を引き続き負うものです。
類似ワードとしてハイブリッドクラウド(オンプレミスとパブリッククラウドの両方を活用),マルチクラウド (複数ベンダーのパブリッククラウドの活用)ありますが、これらがその構成形態を表すのに対して、分散クラウドは明確にその運用管理責任をCloudベンダが負うとしています。
したがいオンプレミスにあるにもかかわらず、コスト・効率性(従量課金、資産の切り離し等)、スピード(迅速なサービスの立ち上げ)、イノベーション(オンプレミス側でも、パブリッククラウドと同等スピードでの新技術を導入し利用)、サポート(クラウドベンダー提供)に関して、クラウドが提案する価値ある重要なメリットはそのまま維持されます。
分散クラウドでは、クラウドサービスの機能を必要とするユーザーに物理的に近い地点(データの発生元であり、ビジネス活動の実行場所)でサービスが運用されるので、低遅延のコンピューティング処理が実現します。この遅延問題の解消によってパフォーマンスが大幅に向上するとともに、グローバルネットワークに起因するサービス停止のリスクが軽減され可用性向上や災害対策等のメリットも得られるといわれています。以上まとめると、分散クラウドのメリットは以下のようになります。
1.データの保管場所に関する規制要件等のコンプライアンスの向上
2.ネットワーク障害リスクの軽減。クラウドサービスはローカルに存在し断続的に接続が切れても稼働するため
3.クラウドサービスがホストされる/利用される場所(コンピューティングゾーン)の数が増えることによる可用性向上
4.IOT機器,モバイルデバイスを利用したエッジコンピューティングにおけるアプリケーション/エッジの大量展開/管理を容易にする。
2.分散クラウドのシステム要件
ここからシステムの話をはじめます。
分散クラウドを実現するには何が必要でしょうか?
1.異種環境を隠蔽する共通API
2.運用の互換性
3.単一のコントロール・プレーン
が前提となります。
分散クラウドの各拠点(お客様管理のオンプレミス,自社/他社Cloud)の環境毎の運用発生によるコスト増大を防ぐためには異種環境の違いを吸収する共通API、相互運用性、また1つのPublic Cloud上の単一のコントロール・プレーンから各環境にアクセス/管理できることが重要です。
1の共通APIに関して分散クラウドサービスでは大きく分けて2つのアプローチがあります。
分散クラウドサービスの比較

まずは従来からあるIaaS(インフラ)レイヤー抽象化のアプローチです。
古くはDeltaCloud ,Libcloud ,jclouds等(添付資料参照)のインフラリソース(サーバー、ストレージ,ネットワーク等)を操作管理する共通APIを提供するものです。
AWS, Azure(Stack)のアプローチでプロプラエタリーな互換APIがベースです。
ただし、互換APIはサポートする各環境APIの更新の度に対応が必要なため制約が多くなるのは否めません。インフラはハードウエア・アプライアンスベースか、もしくは前提条件が非常に多くなります。
これに対してPaaS(プラットホーム)レイヤー抽象化からのアプローチがあります。Google, IBMのアプローチで業界標準のKubernetes APIがベースとなります。主要なクラウドベンダーが賛同する業界団体CNCFでもパブリック/プライベイト/ハイブリッドにおいて一貫性のある開発/運用ポリシーのもと動的オーケストレーションのためのオープンソースであるKubernetes等を利用した共通のクラウドネイティブ環境を構築することを唄っています。Kubernetesにより様々なインフラ環境の違いを吸収することで共通のアプリ運用が可能です。ここではアプリケーションの可搬性も担保できます。
IBM分散クラウドSatelliteではRedHat OpenShiftを利用しています。
RedHat OpenShiftはCNCFの適合性プログラムに準拠しており,エンタープライズ想定のKubernetes の商用ディストリビューションです。OpenShift APIは拡張APIとしてKubernetes APIと互換性があります。OpenShiftが提供するCluster ServiceやDeveloper Service(Kubernetes拡張部分)等のPaaS機能や運用管理機能含めて、特定の環境に依存せずプラットホーム全体の可搬性を確保できます。
OpenShiftを利用することで他社分散クラウドのハードウエア・アプライアンスのようにインフラが特定されることなく、コンテナ対応したアプリケーションの稼働が可能になります。IBMでは提供するソフトウエア/サービスともにはやくからコンテナ対応をすすめてきて現在では大概完了しております。他社に比べて多くのソフトウエア及びマネージド・サービス (PaaS)の分散クラウドへの移植がスムーズ・容易におこなえます、RedHat Open Shift、Databases、Object Storage、Watson等のマネージド・サービスがSatellite上で稼働します。
一方で異種インフラの共通操作/一元管理が必要なときはマルチクラウドにも対応してオープンソースでもあるTerraformを利用するのがいいでしょう。
ただし分散クラウドはOpenShiftだけあれば実現できるわけではありません、
下記の考慮も必要です。
1.サービスへの通信/アクセス経路の制御について
分散クラウドの各拠点は各々のIPアドレス空間をもちます。拠点のサービスへは、その入り口にあたるエンドポイント経由でアクセスされ、他クラウドサービスや拠点外のサーバーと通信する場合は適切なトラフィック制御が必要になります。またセキュリティ確保のため必要Clientのみアクセス制御をかけたり通信の暗号化や透過性・監査性を担保するためのログ機能等も求められます。
2.複数クラスタの構成・リソース管理について
分散クラウドではお客様環境が複数拠点にまたがり、クラスタが複数たつケースも多いです。OpenShiftはそのControl Pointとしての管理コンソールから単一のクラスタを対象として管理機能やコンテナオーケストレーションを提供し、複数の異なるクラスタに対してコンテナをデプロイしたり状態を管理することはできません。
複数のOpenShiftクラスタがあった場合は、どのクラスタにアプリケーション
を配置すべきかを別途決める必要あります。また、セキュリティポリシーが変更になり複数クラスタのリソースに一括して適用したい場合でも、個々のクラスタにアクセスして適用も可能ですが、クラスタ数が多くなると、大変手間がかかります、いわゆる複数クラスタを対象としたアプリケーションの配置・管理、リソースの適用、状態監視等の領域です。
これ以外にも分散クラウドの要件として可用性向上や災害対策等を含めるのであればアプリケーション/データのポータビリティ/同期等の検討も必要です。
3.IBM 分散クラウド Satelliteについて
IBMの分散クラウドのSatelliteの全体アーキテクチャー図になります。

IBM Cloudからお客様拠点にあるOpenShiftのクラスタをリモート管理します。お客様拠点にあるインフラはオンプレミスサーバー機器,AWS, Azure等の他社Public Cloudなんでも構いません。Satelliteで稼働するサービスにはROKS (Red Hat OpenShift on IBM Cloud), PostgreSQL, Redis 等のICD(IBM Cloud Databases) 、IBM Cloud Object Storageがある他、Watson Serviceもサポートが予定されてます。
下記がSatelliteのコンポーネント図です。
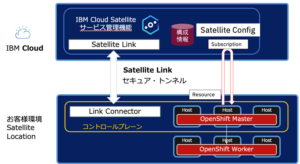
1. Satellite Link(図中左)
前章で紹介した”サービスへのアクセス経路の制御・管理”をするものです。Satellite Linkは、Satelliteロケーション(お客様環境)にIBM Cloudを安全に接続します。 ロケーションとの間の通信は、リンク・トンネル・サーバー(図1参照)によってプロキシー処理され、この接続上のネットワーク・トラフィックをモニターおよび監査することができます。
下記機能を包含します。
-サービス管理の通信を含むトラフィック経路の制御
-透過性と監査性を提供するための記録の保持
-複数の伝送経路のサポート (専用線接続)
2. Satellite Config(図中右)
同様に前章の” 複数クラスタの構成・リソース管理”をするのがSatellite Configです。
稼働中のKubernetesリソースおよび構成情報を一括管理して、ルールに基づきKubernetesアプリや構成をデプロイする機能をもちます。IBM社内で1万以上のKubernetesクラスタを25人以下のスタッフで運用してきた経験にもとづいて開発しオープンソース化した継続的デリバリツール 「Razee」をベースにしています。
Kubernetes リソース YAML ファイルをGit リポジトリーあるいは直接アップロードして、クラスターにデプロイします。Satellite Subscriptionは、どの Kubernetes リソースを どのクラスター・グループ(Satellite 構成に含まれるクラスターのセット)にデプロイするのかを指定します。 Subscriptionを作成すると、 Satellite Config は、指定した Kubernetes リソースを自動的にダウンロードし、クラスター・グループに属するすべてのクラスターに適用を開始します。
4. サンプル事例
IOTのエッジ環境でAI(人工知能)を利用する事例を紹介します。
複数の医療施設内の安全基準の遵守のため防護服/装備のチェックをAIにより実施します。画像データのWatson AIによるリアルタイム分析・チェックに関してデータをCloud データセンターにアップロードしてから実施するのでは時間を要するので、データ発生元であるエッジ環境(施設内)で実行する必要ありIBM分散クラウドのSatelliteを活用します。
全体アーキテクチャーは以下の通りです。
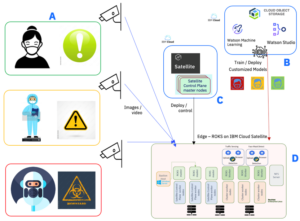
A) 病院の保護エリアと安全保護基準について
通常エリア:マスクと手袋のみの着用
保護エリア:マスク、フェイスシールド、PPE (personal protective equipment ) 着用
完全保護エリア:完全な危険防止ユニフォームの着用
B) 機会学習モデルの作成/トレーニング
機械学習モデルの開発及びトレーニング自体は大量のComputingリソースを使い一括して行う必要ありCloud上で実施します。作成したモデルをリモートのすべての病院や診療所に送付して使用することが可能になります
C) エッジ環境(施設内)にあるすべてのSatellite/OpenShiftクラスタの集中管理
D) ローカルサイトにデプロイされたモデルの実行によりリアルタイムの分析・違反の自動検出、警告、およびレポート
システム準備作業に関する全体ステップは以下の通りです。
1.機械学習モデルの開発・トレーニング。
トレーニング用の大量の画像データ(人の服装/装備の撮影データ)を IBM Cloud Object Storage にアップロードします。
Watson Studio 上でTensorFlow、 Keras、SciKit-Learn等の機械学習ライブラリィを使用してモデルを開発します。IBM Cloud Object Storageからデータを読み込み、Watson Machine Learning を使用して、テスト・トレーニングします。トレーニングされたモデルは、全ての施設で利用することが可能です。
2. エッジ環境でのSatellite/OpenShiftのセットアップ
エッジ・インフラストラクチャー(医療施設内のServer)に Satellite ロケーションを作成します。Satellite ロケーションに Red Hat OpenShift クラスターを作成しOperatorを使用して、 Red Hat OpenShift Serverless (OpenShiftのサーバーレス ソフトウエア)をインストールします。その後上記でトレーニングされたモデルをKnative 準拠のコンテナー・イメージとして、このRed Hat OpenShift Serverless プロセッサーにデプロイし稼働させます。
5. おわりに
冒頭の話に戻りますが、野球にAIを活用する取り組みとして、バッターやピッチャーのフォームを動画撮影してフォームチェツク/解析/修正に役立てるというものがあります。現在では動画データをクラウドベンダーのデータセンターのストレージにアップロードしてからAIサービスを利用しており時間、手間暇ともかかるものです。Satelliteを使うことによりリアルタイムのフォームチェック/解析が可能になることで、USメジャーでの日本人選手の一層の活躍に貢献できることを期待するばかりです。
®︎参考資料/文献
分散クラウド vs. ハイブリッド・クラウド vs.マルチクラウド vs エッジ・コンピューティング (Part 1)
分散クラウドのアーキテクチャーを理解する : ベンダーの違い・特徴編
The CIO’s Guide to Distributed Cloud
本書に記載されている商品名、サービス名、会社名、団体名、およびそれらのロゴマークは、一般に各社または各団体の商標または登録商標です。本文中では®︎ マーク等の表示は省略させていただきました。
坂田 直紀
日本アイ・ビー・エム株式会社
クラウド事業本部
テクニカル・セールス

ジェネレートするAI。クリエートする人類 。 | Think Lab Tokyo 宇宙の旅(THE TRIP)
IBM Data and AI, IBM Partner Ecosystem, IBM Sustainability Software
その日、船長ジェフ・ミルズと副船長COSMIC LAB(コズミック・ラブ)は、新宿・歌舞伎町にいた。「THE TRIP -Enter The Black Hole-」(以下、「THE TRIP」)と名付けられた13度目の ...続きを読む

OEC新オフィス「未来の杜 Play Field」から広がるつながりとウェルビーイングな社会
IBM Partner Ecosystem
コンピューター商用化の創成期から現在まで、大分を拠点に先端テクノロジーを駆使する総合情報処理サービス企業として業界をリードしてきた株式会社オーイーシー(OEC)が、先日大分市のソフトパークに本社新社屋を新設。同時に旧社屋 ...続きを読む

バリュー・ディストリビューターのご紹介『エヌアイシー・パートナーズ株式会社』
IBM Partner Ecosystem
エヌアイシー・パートナーズ株式会社は 2002年4月にディストリビューター事業を開始した日本情報通信株式会社 パートナー事業部を起点とし、日本情報通信グループの広範なソリューションに対する理解と高度な技術力を提供する I ...続きを読む