Analytics
Wat moet u doen om uw AI/ML-modellen in productie te krijgen?
25/03/2020 | Written by: Ronald van der Knaap and Peter Den Haan
Categorized: Analytics
Share this post:
Bedrijven en instellingen die de stap naar het toepassen van kunstmatige intelligentie (AI) en machine learning (ML) maken, kijken vaak onvoldoende naar de technische integratie en de interne afstemming die het gebruik van dit soort functionaliteit vereist, waardoor activiteiten rondom AI / ML niet in productie genomen worden. Met de juiste inzichten en technieken kan deze veelbelovende technologie goed ingezet worden.
Met behulp van ML konden we al inzichten verkrijgen in complexe onderwerpen. Met AI kan dit nog een stap verder gebracht worden. AI kan werknemers ondersteunen tijdens een variëteit aan werkzaamheden. Zeer complexe (AI) modellen die in het verleden onmogelijk binnen een afzienbare tijd uitgevoerd konden worden kunnen nu, met de techniek van vandaag wel worden gebruikt.
Hoe ga je als bedrijf al die nieuwe mogelijkheden benutten en gestalte geven? Ronald van der Knaap, Data & AI Architect bij IBM, heeft daar een antwoord op: “Door de benodigde functionaliteit samen te voegen in één platform, Cloud Pak for Data, krijg je een geïntegreerde beleving van al de verschillende functies die je nodig hebt om AI gestalte te geven en meer met de data te kunnen gaan doen. Dat is in essentie wat we doen.”
Dat beaamt ook Peter den Haan, Technical Sales Manager: “Iedereen heeft het over AI en waarde uit data halen, maar dat is niet zo eenvoudig. Iedereen doet wat, maar het echt systematisch goed opzetten en het integreren in je operationele landschap gebeurt vaak niet.”
Van der Knaap maakt het belang van goede data- en AI-modellen graag duidelijk door te vragen of mensen zich in het ziekenhuis zouden laten behandelen op basis van een computermodel en daar dan vertrouwen in hebben. “Dan moet die data van hoge kwaliteit zijn en je moet die data als gebruiker, de dokter in dit geval, ook vertrouwen.”
IBM heeft in een vision paper ‘Ladder to AI’ samengevat hoe organisaties zich kunnen voorbereiden om de mogelijkheden van AI goed te gebruiken. Dit betekent onder andere dat organisaties data goed moeten kunnen beheren en dat bekend is wat de data exact voorstellen. Ook moet duidelijk zijn hoe gevoelig de data zijn in verband met zaken als privacy.
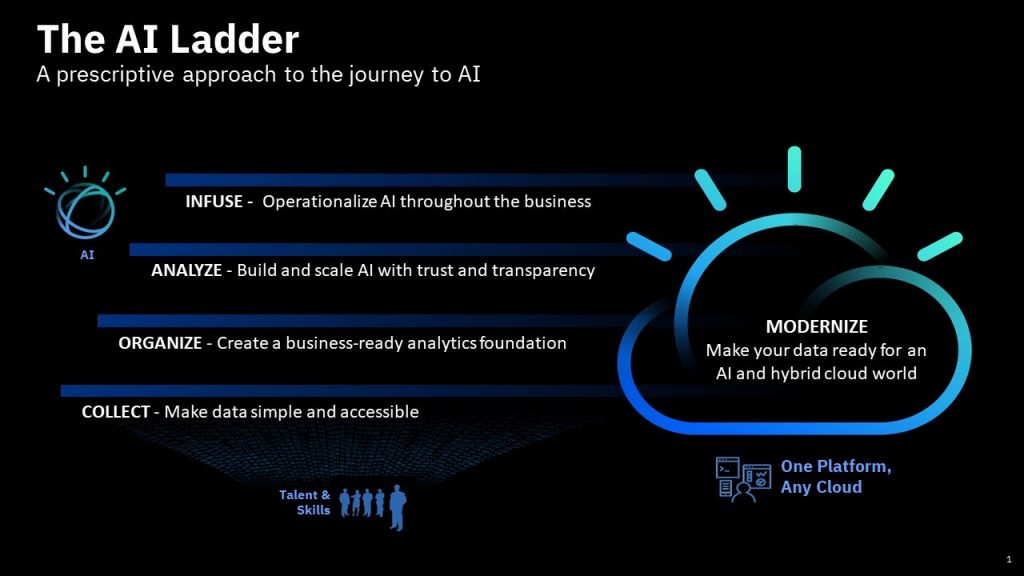
Gestructureerde data, Governance
Hier zit een belangrijk punt, iedereen moet begrijpen wat de data waarmee men werkt inhoudt. Van der Knaap: “Een hardcore data scientist begrijpt hoe de door zijn team geprogrammeerde code in elkaar zit, maar een citizen data scientist, iemand die meer grafische modellen maakt, weet dat vaak niet. Daarom is het zaak om ervoor te zorgen dat er geen fouten gemaakt worden in de interpretatie van de data.
Den Haan: “Het gebruik van visueel programmeren is heel praktisch, je maakt het makkelijker om te bespreken met een eindgebruiker, in dit geval een arts die echt de logische puzzelstukjes wel begrijpt, maar niet zelf kan programmeren. Op deze manier kun je als eindgebruiker en deskundige valideren.”
“De arts weet uiteindelijk wat wel of geen logische aannames zijn, dat vereist samenwerking met de data-scientist”, voegt Van der Knaap toe.
Iets dat veel toegepast wordt en valt onder de vlag van kunstmatige intelligentie is deep learning, een nieuwere techniek om machine learning modellen verder te verbeteren. Echter, Deep Learning zorgt voor nieuwe uitdagingen. Uitkomsten van deep learning modellen zijn namelijk moeilijk uit te leggen, met andere woorden: het is niet meer duidelijk hoe een model tot een uitkomst komt. Van der Knaap legt uit dat IBM daar functionaliteit voor heeft die valideren of een uitkomst inderdaad juist is. “We kunnen via bepaalde parameters terugredeneren of een model geen last heeft van bepaalde verkeerde aannames (biases)” legt hij uit.
Ongestructureerde data
Het analyseren van ongestructureerde data is een grote opgave en daar kan AI heel behulpzaam bij zijn. Van der Knaap zegt dat het voor mensen heel normaal is als we bepaalde verbanden leggen die een computer normaal niet kan leggen. Mensen bouwen veel specifieke domeinkennis op als ze lang werkzaam zijn in een bepaald specialisme. Nieuwe mensen hebben deze kennis nog niet en het duurt lang voordat deze is opgebouwd. Het zou helpen als deze mensen kunnen zoeken in een enorme hoeveelheid documentatie over dat domein en een antwoord snel kunnen vinden. Een voorbeeld: bij meer complexe machines wordt het voor een engineer volstrekt onmogelijk om alles te kunnen overzien en te kennen. Bepaalde processen mogen niet stil komen te liggen, en als er toch iets misgaat, moet een engineer heel snel het probleem kunnen opsporen.
“Het systeem moet snappen wat je vraagt”, zegt Van der Knaap. “Dit noemen we linguistic intelligence, maar in het begin is het systeem nog helemaal onwetend. Je moet die kennis inbrengen alsof je een kind opvoedt. Dan leert zo’n systeem het vocabulair, de afhankelijkheden tussen allerlei componenten, op een heel andere manier dan bij een rechttoe-rechtaan zoeksysteem. Daar gebruiken we IBM Watson voor.”
“De bottom line is dat het gaat om het heel snel door documenten kunnen zoeken en niet alleen op woorden, maar op begrijpen wat er staat. Daarmee is een heel nieuwe functionaliteit toegevoegd aan het onderliggend IBM platform, in dit geval het analyseren van ongestructureerde data uit tekst en taal, samen met een tool om te annoteren, dat kun je allemaal makkelijk aan het IBM platform toevoegen d.m.v. cartridges.”
Als laatste voorbeeld komt een case naar voren over winkellocaties en assortimenten. “Een klant in Londen wilde bijvoorbeeld weten hoe ze meer publiek in de winkel konden krijgen. Daarvoor moest duidelijk worden waar de doelgroep woont, waar ze interesse in hebben en wat moeten we daarvoor in de winkel hebben om te voorkomen dat mensen alleen nog maar online kopen. Met heel veel verschillende datapoints hebben we dat onderzocht. En dat hebben we voor meer projecten in steden over de hele wereld gedaan.” zegt Van der Knaap.
“En dat kun je ook weer gebruiken voor deelfietsen, voor smart bikes, voor bevoorrading, patronen die terugkomen in vele andere projecten”, vult Den Haan aan.
Het aantal vragen dat je kunt onderzoeken door gebruik te maken van machine learning en AI is schier eindeloos. Dat is een constante reis van onderzoek en uitvoering, met incrementele stapjes wordt alles steeds iets slimmer. Zorg er daarbij voor dat de keten van data bron tot en met het maken en gebruiken van AI modellen een platform aanpak hanteert, zodat machine learning en AI de juiste waarde voor jouw organisatie kan opleveren, met goede kwaliteit en effectieve governance.

Architect Data & AI, IBM Cloud
Technical Sales Manager Data & AI, IBM

Datagedreven asset management met IBM Maximo Application Suite en Cloud Pak for Data
IBM heeft zijn Enterprise Asset Management-platform IBM Maximo Application Suite (MAS) voorzien van IBM Cloud Pak for Data: een ondersteunend platform met een raamwerk om allerlei data uit verschillende organisatieonderdelen te combineren. Hoe helpt IBM Cloud Pak for Data organisaties om aanvullende asset management-inzichten uit beschikbare data te verkrijgen? Het aantal intelligente stand-alone en edge […]

IBM SPSS Statistics Versie 27: Wat is er bijgekomen?
IBM SPSS Statistics, het bestaat al een tijdje, maar het is nog steeds going strong! Op 16 juni is de nieuwe versie van IBM SPSS Statistics, V27, beschikbaar gekomen met weer nieuwe mogelijkheden, variërend van verbetering in de gebruiksvriendelijkheid tot extra functionaliteit, zoals Power Analysis. Deze blog geeft een korte beschrijving van de vernieuwingen, […]

Naar intelligente bedrijfsautomatisering met Business Rules en Machine Learning
Veel bedrijven denken dat ze al lang geleden de grote stap hebben gezet in de richting van bedrijfsautomatisering. Technisch gezien klopt dat, lang geleden. De volgende stap in de bedrijfsautomatisering is de daadwerkelijke automatisering van het bedrijf en dat is waar IBM Digital Business Automation voor zorgt door gebruik te maken van technieken als […]