Modelos fundacionales NLP y su aplicación en asistentes virtuales como ChatGPT
Disrupción tecnológica en los modelos de atención


Luis García Reyes
Business Design Specialist
IBM Consulting
¿Qué son los modelos fundacionales NLP? ¿Qué son BERT, GPT-3 y LaMDA? ¿y ChatGPT?
A finales de 2021, la Univerdad de Standford publicó un informe donde se acuñó por primera vez el término Modelo Fundacional NLP, también conocido como Large Language Model (LLM), Massive Language Model (MLM), Transformer Language Model.
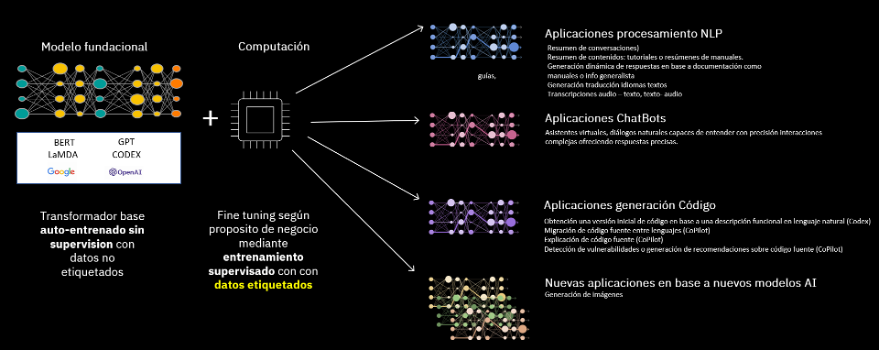
Se trata, básicamente, de algoritmos basados en redes neuronales que se entrenan con inmensos conjuntos de datos sin etiquetar de manera automática.
Existen varios modelos fundacionales populares, como por ejemplo BERT, USE (Universal Sentence Encoder), T5 y RoBERTa desarrollados por grandes empresas como Google y Facebook.
Los dos modelos fundaciones más recientes y en plena ebullición son GPT-3 y BLOOM:
- GPT-3: es un modelo fundacional NLP desarrollado por OpenAI en 2020 (última versión 3.5 en 2023 entrenado con un set de más de 175 billones de variables). Recientemente se ha lanzado un chatbot sobre este modelo fundacional llamado ChatGPT que en estos momentos no permite personalización ni adaptación a un negocio. Ofrece respuestas generalistas (entrenado con información hasta finales de 2021), pero sí está previsto que en próximas versiones pueda ser entrenado..
- GPT-3 es accesible a través de suscripción, bien directamente por consumo de API o bien vía integración sobre Azure Open AI, pues desde julio de 2019 Microsoft Corp. y OpenAI tienen una alianza para extender las capacidades de Microsoft Azure en sistemas IA de gran escala.
- BLOOM: creado por un conjunto de científicos en 2022, se presenta como alternativa a GPT-3 al ser un modelo fundacional NLP gratuito para todos aquellos que quieran construir adaptaciones a partir de él.
¿Cómo se utilizan los modelos fundacionales para las tareas de NLP?
Como hemos explicado anteriormente, un modelo fundacional NLP es básicamente un modelo de lenguaje auto-regresivo que utiliza el contexto de las palabras anteriores para predecir la siguiente palabra en una oración. Básicamente, estos modelos funcionan como predictores de palabras en un texto.
Por ejemplo, para la frase «las universidades españolas son conocidas por su…«, un modelo fundacional NLP podría predecir como próxima palabra «investigación» o «calidad«.
Procesos de ajuste: Fine tunning
Los modelos fundacionales se ajustan para obtener aplicaciones de mercado a través de un proceso conocido como fine tunning o afinación. Se pueden entrenar o adaptar para una tarea NLP específica. Su aplicabilidad es múltiple, desde generación de resúmenes (analizando grandes cantidades de texto para identificar las ideas principales y resumirlas en un formato más conciso y fácil de entender), extracción de entidades, traducción automática, clasificación de texto… o incluso permitiendo establecer conversaciones naturales e inteligentes con sistemas que son capaces de entender 100% una intención y un contexto, ofreciendo respuestas precisas… abriendo un nuevo paradigma en la atención a personas por sistemas automáticos como por ejemplo los asistentes virtuales.
¿Qué diferencia hay entre Watson Assistant y otros chatbots por ejemplo ChatGPT, BARD o Blender Bot?
Cabe destacar que, a día de hoy, son mundos separados con diferentes propósitos, con sus ventajas e inconvenientes en su aplicación a la atención ciudadana.
Aplicaciones conversacionales como ChatGPT (construido sobre GPT), BARD (recientemente anunciado y construído por Google bajo tecnología LaMDA para competir con Microsoft) y Blender Bot de Meta (Facebook) están clasificadas por la comunidad científica como “aplicaciones de dominio abierto”.
Están entrenadas con cantidades masivas de datos y pueden mantener conversaciones sobre casi cualquier tema generalista. Presentan como inconveniente algunas lagunas heredadas de la calidad de la información con la que se ha entrenado (fuentes públicas de internet, redes sociales, Wikipedia….). Pueden llegar a ofrecer respuestas sesgadas, no precisas, al no tener controlada la calidad de la fuente que ingestan. Se han detectado casos donde el modelo deja fuera de sus respuestas, por ejemplo, a personajes históricos femeninos realmente relevantes.
Un ejemplo, en el siguiente caso, ChatGPT deja fuera a Katherine Johnson como persona relevante en la respuesta de quién realizó los cálculos matemáticos para que el Apolo XI llegara a la luna.

Thomas K. Mattingly era astronauta, sirvió de apoyo técnico a los astronautas en la tarea de regreso del Apolo XI. Como puede verse en la corrección que hace, no es la respuesta más precisa, deja fuera de ella a personas realmente relevantes como Katherine Johnson.

A día de hoy, sistemas como ChatGPT presentan en algunos casos ciertas imprecisiones que, sin duda, serán corregidas con nuevos ciclos de ajuste fine tuning. No obstante, es innegable que estamos en un momento de revolución e irrupción de las capacidades cognitivas desarrolladas sobre modelos fundacionales NLP en los modelos de atención.
El futuro más inmediato pasa por la aplicabilidad de este tipo de tecnología en suma con conocimiento experto, asistentes virtuales entrenados con una base de contenido generalista y adaptados para cada negocio con contenidos y entrenamientos realizados por equipos expertos.
IBM Consulting cuenta con múltiples referencias en desarrollo de asistentes virtuales tanto dentro como fuera de España. Disponemos de conocimiento, experiencia y aceleradores propios que nos permiten construir asistentes virtuales orientados a resolver las necesidades del servicio de atención de nuestros clientes.
Estamos viviendo un momento de transformación cognitiva a nivel mundial, el reto es apasionante, sigamos avanzando juntos.