Inteligencia artificial hoy: datos, entrenamiento e infrerencias

En mi último blog, hablé sobre la inteligencia artificial, machine learning y deep learning y de algunos de los términos que se utilizan cuando se habla de ellos. Hoy, me enfocaré en cómo los datos, el entrenamiento y las conclusiones son aspectos principales de esas soluciones.
La gran cantidad de datos que las organizaciones tienen actualmente disponibles hacen posible la utilización de muchos recursos de IA que parecían ciencia-ficción. En la industria de la TI, llevamos años hablando acerca del “big data” y de los desafíos a los que se enfrentan las empresas a la hora de procesar y usar todos sus datos. La mayor parte de ellos, aproximadamente el 80%, no están estructurados, así que los algoritmos tradicionales no son capaces de analizarlos.
Hace algunas décadas, los investigadores crearon las redes neuronales, algoritmos de machine learning que pueden desvelar insights de los datos, a veces algunos insights que nunca pudimos ni imaginar. (Para entender la definición básica del deep learning, lea a mi blog anterior). Si podemos ejecutar esos algoritmos en un marco temporal factible, se pueden utilizar para analizar nuestros datos y para descubrir patrones en ellos, lo que podría ayudar a tomar decisiones empresariales. Estos algoritmos, sin embargo, son intensivos en computación.
Cómo capacitar las redes neuronales
Los algoritmos de deep learning son los que utilizan las redes neuronales para solucionar un problema específico. Una red neuronal es un tipo de algoritmo de IA que toma una entrada, la hace atravesar su red de neuronas, llamadas capas, y proporciona un resultado. Cuantas más capas de neuronas tiene, más profunda es la red. Si el resultado es adecuado, genial. Si el resultado está equivocado, el algoritmo aprende que está equivocado y “adapta” sus conexiones neuronales de una forma que, con suerte, la próxima vez que proporcione esa entrada en particular, dará el resultado adecuado.
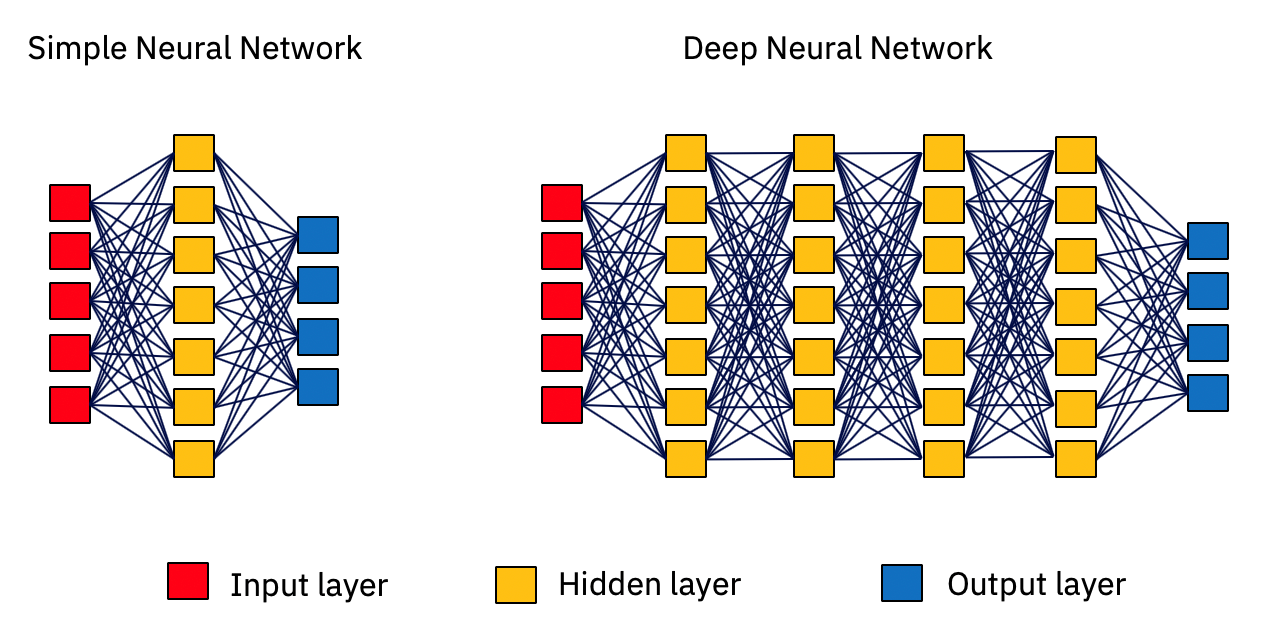
Img 1: Ilustración de redes neuronales computarizadas
Esta capacidad de volver a capacitar una red neuronal hasta que aprenda cómo proporcionar la respuesta adecuada es un aspecto importante de la computación cognitiva. Las redes neuronales aprenden de los datos a los que están expuestas y reorganizan la conexión entre las neuronas.
Las conexiones entre las neuronas es otro aspecto importante, y la fuerza de la conexión entre las neuronas puede variar (es decir, su vínculo puede ser fuerte, débil o cualquier cosa entre medias). Así que, cuando una red neuronal se adapta a sí misma, realmente está ajustando la fuerza de las conexiones que existen entre sus neuronas, para que la próxima vez pueda proporcionar una respuesta más precisa. Para que una red neuronal proporcione una respuesta buena a un problema, hay que ajustar estas conexiones ejercitando repetidamente una capacitación exhaustiva de la red, es decir, exponiéndola a los datos. P Puede haber miles de millones de neuronas involucradas, y ajustar sus conexiones es un procedimiento matemático basado en una matriz intensivo en cómputo.
Necesitamos datos y potencia de computación
Como ya dijimos, actualmente, la mayoría de las organizaciones tienen multitud de datos que pueden utilizar para capacitar estas redes neuronales. Pero todavía existe el problema de todas las matemáticas masivas e intensivas que se necesitan para calcular las conexiones de las neuronas durante la capacitación. Con toda la potencia que tienen actualmente los procesadores, solo pueden realizar un número de operaciones matemáticas por segundo. Una red neuronal con un billón de neuronas entrenadas en miles de iteraciones de entrenamiento aún requerirá un billón de operaciones para ser calculadas. ¿Y ahora que?
Gracias a los avances en la industria (y personalmente me gusta pensar que la industria del juego jugó un papel importante aquí), hay una pieza de hardware que es excelente para manejar operaciones basadas en matriz llamada Unidad de procesamiento de gráficos (GPU). Las GPU pueden calcular prácticamente miles de millones de píxeles en operaciones tipo matriz para mostrar gráficos de alta calidad en una pantalla. Y, como resultado, la GPU puede funcionar en operaciones matemáticas de redes neuronales de la misma manera.
Permítame presentarle al mejor estudiante de matemáticas de la clase: ¡la GPU!

Img. 2: Un módulo GPU NVIDIA SMX2
Una GPU es un hardware que es capaz de realizar operaciones matemáticas sobre una gran cantidad de datos al mismo tiempo. No es tan rápida como una unidad de procesamiento central (CPU), pero si se le proporcionan muchos datos para que los procese, lo hace de forma masiva en paralelo y, aunque cada operación se ejecuta de forma más lenta, el paralelismo de aplicar las operaciones matemáticas a más datos al mismo tiempo supera por mucho el rendimiento de la CPU, lo que permite obtener las respuestas más rápidamente.
El big data y la GPU han proporcionado los avances vanguardistas que necesitábamos para utilizar correctamente las redes neuronales. Y esto nos lleva a donde estamos actualmente con la IA. Las organizaciones ahora pueden aplicar esta combinación en sus empresas y descubrir insights de su enorme universo de datos mediante la capacitación de una red neuronal para ello.
Para aplicar correctamente la IA a su empresa, el primer paso que tiene que dar es asegurarse de que tiene muchos datos. El rendimiento de las redes neuronales es malo si se capacitan con pocos datos o con datos inadecuados. El segundo paso es preparar los datos. Si usted está creando un modelo que sea capaz de detectar aislantes que funcionan mal en los cables eléctricos, debe proporcionarle datos acerca de los que funcionan y de todos los tipos de los que funcionan mal. El tercer paso es capacitar una red neuronal, lo que requiere mucha potencia de computación. Luego, después de que capacite una red neuronal y vea que tiene un rendimiento satisfactorio, puede ponerla en producción para que saque conclusiones.
Inferencia
Inferencia es el término que describe el acto de usar una red neuronal para proporcionar insights después de que ha sido entrenada. Piense en ello como alguien que está estudiando algo (está siendo capacitado) y, después, va a trabajar en el mundo real (inferencia). Hacen falta años de estudio para convertirse en doctor, al igual que hace falta mucha potencia de procesamiento para capacitar las redes neuronales. Pero a los doctores no les hace falta años para operar a un paciente, y, de igual manera, a las redes neuronales le hacen falta tiempos inferiores a un segundo para proporcionar una respuesta a datos dados sobre el mundo real. Esto ocurre porque la fase de sacar conclusiones de una solución basada en redes neuronales no necesita de mucha potencia de procesamiento. Solo necesita una fracción de la potencia de procesamiento que se necesita para el entrenamiento. Como consecuencia, no hace falta tener un hardware potente para poner en producción una red neuronal entrenada, sino que se puede utilizar un servidor más modesto, llamado “inference server”, cuyo único propósito es ejecutar un modelo de IA entrenado.
Cuál es la apariencia del ciclo de vida de la IA:
Los proyectos de deep learning tienen un ciclo de vida peculiar por la forma en la que funciona el proceso de capacitación.
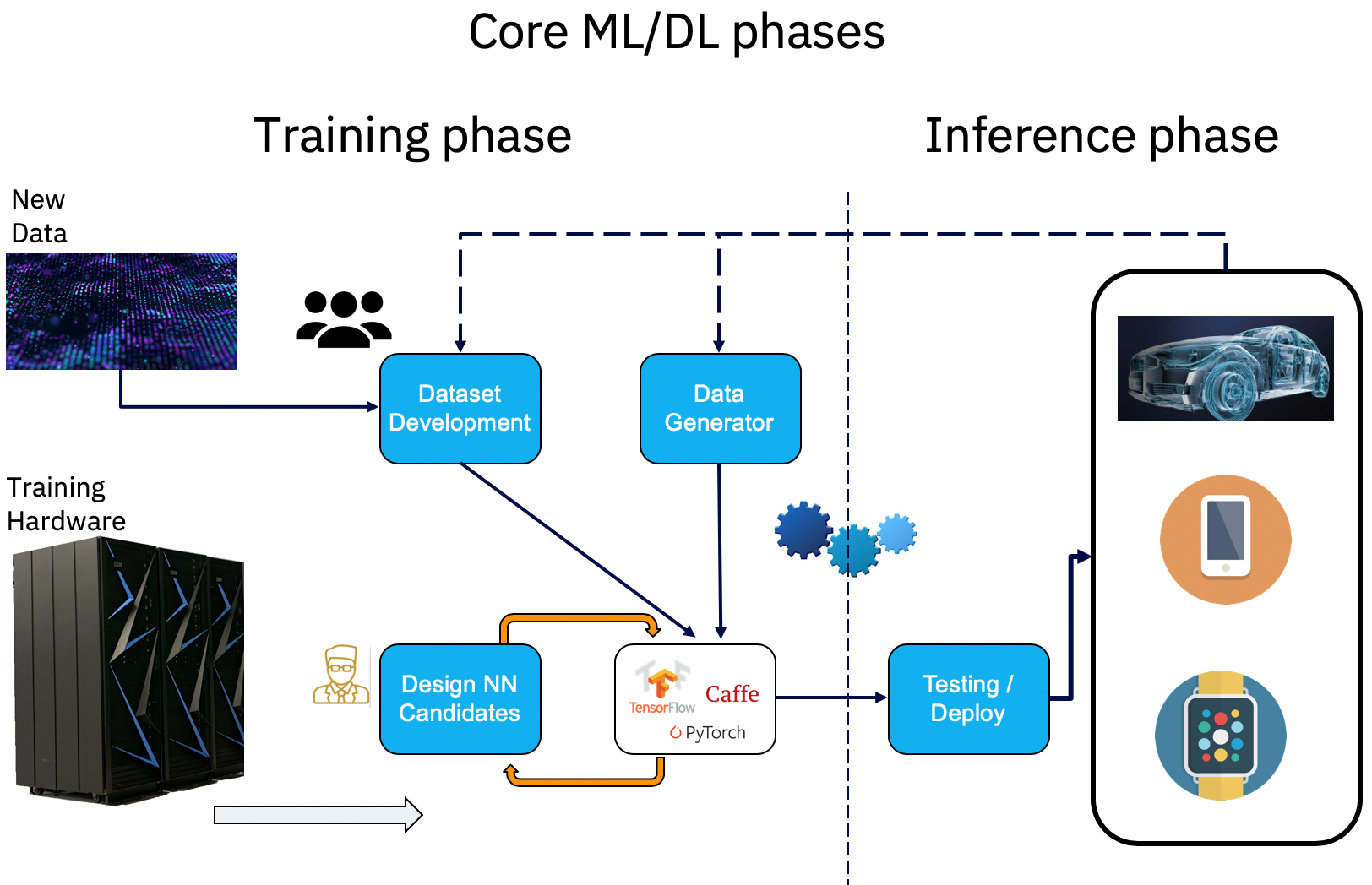
Img 3: Ciclo de vida de un proyecto de deep learning
Actualmente, las organizaciones se están enfrentando al desafío de cómo aplicar deep learning para analizar sus datos y obtener insights de ellos. Tienen que tener suficientes datos para entrenar un modelo de redes neuronales. Esos datos tienen que ser representativos para el problema que están intentando solucionar; en caso contrario, los resultados no serán precisos. Y necesitan una infraestructura de TI robusta creada con clústeres con muchas GPU en la que capacitar sus modelos de IA. La fase de entrenamiento puede continuar durante varias iteraciones y hasta que los resultados sean satisfactorios y precisos. Una vez que eso sucede, la red neuronal entrenada se pone en producción en hardware mucho menos potente. Los datos procesados durante la fase de inferencia pueden retroalimentar el modelo de red neuronal para corregirlo o mejorarlo de acuerdo con las últimas tendencias que se crean en los datos recién adquiridos. Por lo tanto, este proceso de entrenamiento y reentrenamiento ocurre de forma iterativa a lo largo del tiempo. Una red neuronal que nunca se vuelve a entrenar envejecerá con el tiempo y potencialmente se volverá inexacta con nuevos datos.
Esta publicación ofrece una visión de alto nivel de cómo los datos, el entrenamiento y la inferencia son aspectos clave de las soluciones de deep learning. Hay mucho más que decir sobre el hardware, el software y los servicios que pueden ayudar a las empresas a lograr implementaciones exitosas de IA, y en los próximos artículos profundizaré en cada área. Dondequiera que se encuentre en el viaje de IA con IBM Power Systems, IBM Systems Lab Services cuenta con consultores experimentados que pueden ayudarlo. Póngase en contacto con nosotros.