Entrene un modelo de IA una vez que sus datos están listos

Hace poco escribí sobre lo importante que es la en el ciclo de vida de un proyecto de IA. Proporcionar buenos datos al modelo de IA es clave para que tenga éxito. Pero entrenarlo también juega un papel importante y puede presentar algunos desafíos.
Un modelo de IA aprende por repetición. Si no entrena el modelo lo suficiente, no puede ajustar adecuadamente los pesos de su red neural. (Lea mi visión general de las etapas de IA para ver un anticipo sobre entrenamiento e inferencia). La forma en que lo entrene también impacta en su utilidad y precisión cuando intenta dar una respuesta a una entrada de datos reales. Entrenar un modelo de IA de forma efectiva se compara en parte con enseñar a un niño en la escuela por medio de instrucciones, ejercicios y pruebas.
Analicemos cómo funciona esto. Cuando usted entrena un modelo de IA, primero necesita alimentarlo con datos. El propio modelo intentará aprender y después hacer una prueba. En cada prueba se puntúa al modelo contra la respuesta esperada para determinar la precisión del modelo. Idealmente, queremos una precisión los más cercana posible al 100% Cuando el modelo de IA empieza a aprender de los datos de entrenamiento, retorna baja precisión, lo que significa que aún no entiende lo que usted está queriendo que logre. Así, para mejorar la precisión, se la expone repetidamente a ruedas de entrenamiento. Cada rueda se llama epoch (iteración), y el modelo vuelve a ser evaluado al final. Un niño en la escuela, de forma similar, podría no tener buenos resultados en las primeras pruebas, pero por medio del aprendizaje repetitivo puede mejorar hasta que alcance un puntaje deseable.
La Figura 1 muestra el entrenamiento de un modelo. Fíjese cómo mejora la precisión con el número de epochs. La precisión final de este modelo, sin embargo, aún está alrededor de un 60 por ciento.
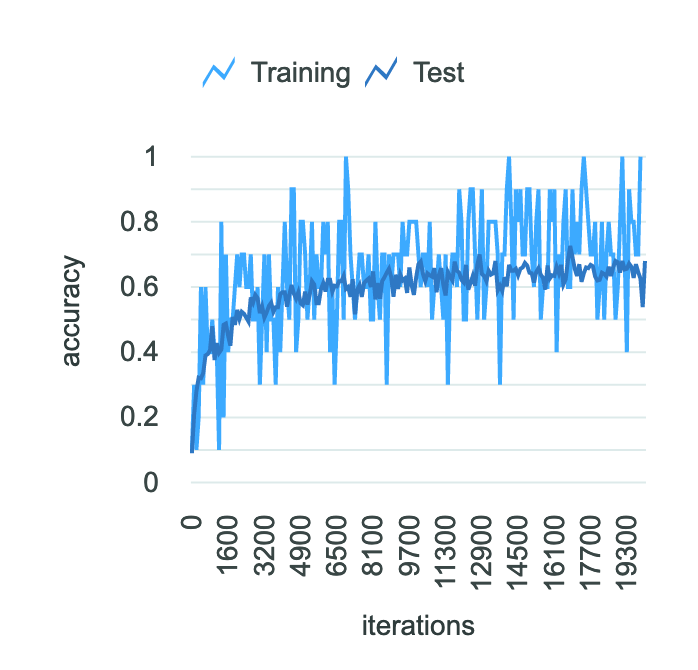
Figura 1: Precisión del modelo para 20 mil epoch [Fuente: Ej.: IBM Watson Machine Learning Accelerator]
Desafíos de entrenar un modelo de IA
Tal como sucede en la escuela, pueden surgir algunos problemas con un modelo de IA. Suponga que un alumno pasa por una serie de ejercicios, luego, al final usted le aplica una prueba que tiene algunos ejercicios exactamente iguales a los que usó para estudiar. Esa sería una prueba fácil pues el niño ya vio las respuestas antes. Eso puede pasar también con un modelo, si lo evalúa usando los mismos datos que usó para entrenarlo. Por lo tanto, es necesario evaluar la precisión del modelo usando datos diferentes de los usados para entrenarlo. Un científico de datos debe ser muy cuidadoso y prepararse para eso durante el entrenamiento.
El futuro de los negocios con soluciones de infraestructura para IA de IBM
Hay otros desafíos habituales que pueden presentarse durante el entrenamiento. Uno de ellos es el sobreajuste (overfitting), que se da cuando el modelo levanta demasiados detalles de los datos de entrenamiento al punto de entender el ruido como parte de los atributos que debe aprender. Hace buen uso de los parámetros de entrenamiento, pero falla en el mundo real. Lo opuesto al sobreajuste es el subajuste (underfitting), una situación en la que el modelo no puede siquiera comprender los datos de entrenamiento y muestra baja precisión incluso en la fase de entrenamiento. Cuando hay un subajuste, suele ser una señal de que deben hacerse cambios en el propio modelo. Hay muchos otros problemas que pueden suceder en la fase de entrenamiento, como explosión de gradiente, sobreflujo, saturación o divergencia. Si bien no voy a mencionar específicamente cada uno, están ampliamente explicados aquí.
Hiperparámetros
Ahora que sabe que hay desafíos en el entrenamiento, supongamos por un momento que pudiera evitarlos a todos y que usted elige un algoritmo específico con el que entrenar su modelo. Incluso en ese escenario, usted se vería frente al dilema de elegir algunos parámetros que ese algoritmo usa para controlar el aprendizaje de la red neural. Son los llamados hiperparámetros. Se los elige antes de empezar el entrenamiento y se los mantiene en el mismo valor a lo largo del mismo. Entonces, ¿cómo hace para elegir los mejores hiperparámetros para obtener los mejores resultados? Esta es una pregunta difícil de responder, y por lo general se hace por prueba y error o realizando una búsqueda de hiperparámetros en la que se hacen rondas de entrenamiento reducidas con diferentes valores para los parámetros, y el de mejor rendimiento es elegido como el conjunto de parámetros con la mejor precisión general.
El hardware marca diferencia
El entrenamiento puede ser una tarea ardua por sí solo, y muchas veces es un paso que se repite hasta estar satisfechos con la calidad de la red neural resultante. Mientras más rápido pueda usted realizar el entrenamiento, y aprender de sus errores para intentarlo de nuevo. No digo esto para desalentar a nadie, sino para decir que utilizar hardware de punta para entrenar estos modelos de IA marca una gran diferencia. El IBM Power System AC922 soporta hasta seis GPU NVIDIA V100 interconectados con tecnología NVLink y presentando slots PCIe Gen4, lo que es de una tremenda ayuda para acelerar y refinar sus modelos de entrenamiento.

Figura 2: IBM AC922, 6x V100 GPUs, NVLink, PCIe Gen4, modelo refrigerado con agua [Fuente: https://www.redbooks.ibm.com/redpapers/pdfs/redp5472.pdf]
La detección temprana de errores también puede ahorrarle tiempo. Soluciones como IBM Watson Machine Learning Accelerator con Deep Learning Impact (DLI) tiene características interesantes para detectar problemas de entrenamiento como el sobreajuste, subajuste, explosión de gradiente, sobreflujo, saturación y divergencia durante el entrenamiento. Así que no necesita esperar horas hasta que se complete el entrenamiento. Si alguna de estas situaciones fuera detectada, la herramienta simplemente se lo advertirá y usted puede detener el entrenamiento, hacer algunos ajustes y volver a empezar. Finalmente, DLI también hace búsquedas de hiperparámetros y le proporciona un conjunto de mejores valores para usar. A todos los científicos de datos: Ustedes pueden controlar la búsqueda con cuatro tipos de algoritmos (aleatorio, Tree-based Parzen Estimator, Bayesian y Hyperband), seleccione el universo para búsqueda (rango de parámetro) y el límite de tiempo para la buscar la mejor respuesta.
Espero que esta publicación del blog le haya servido de introducción a lo que sucede durante la fase de entrenamiento de un proyecto de IA. En mi próxima publicación hablaré de lo que pasa después de que se declara listo el modelo para el mundo real: ¡inferencia!
Vea las sesiones de Think Digital on demand
Mientras tanto, si necesita soporte para un proyecto de IA en IBM Power Systems, no dude en contactar a nuestros especialistas aquí.