Para la IA empresarial, la potencia cambia todo

Esta publicación de blog está patrocinada por IBM. El autor, Peter Rutten, es Director de Investigación de la Práctica de Infraestructura Empresarial de IDC, enfocándose en infraestructura de alta gama, acelerada y heterogénea y sus casos de uso. La información y las opiniones contenidas en este artículo son suyas, basadas en investigaciones realizadas por IDC.
Una encuesta de IDC que realicé en 2018 (N = 200) muestra lo que las organizaciones requieren más de una plataforma de inteligencia artificial (IA) por encima de todo lo demás es el rendimiento, más que la asequibilidad, un factor de forma específico, el soporte del proveedor o un stack completo de software de IA en la plataforma. En otras palabras, las empresas quieren potencia y la quieren de todos los componentes críticos: los procesadores, los aceleradores, las interconexiones y el sistema de E / S.
De hecho, la potencia se ha centrado en la industria. La mayor parte de la interrupción en el ecosistema de la infraestructura es causada por una búsqueda renovada del rendimiento del procesador y el coprocesador en la era de la IA. Se ha logrado un progreso significativo en los últimos dos años y hay una gran cantidad de potencia disponible para que las organizaciones ejecuten sus cargas de trabajo de IA, incluidas las tareas de capacitación de deep learning. Por otro lado, sin embargo, la barra se establece cada vez más alto. Los algoritmos se están volviendo más complejos, sin mencionar que son más grandes, y los volúmenes de datos en los que se entrenan los algoritmos están creciendo enormemente.
Hay un gráfico interesante de IDC que muestra el porcentaje de unidades de servidores x86 en todo el mundo que alcanzaron cerca del 99 por ciento en 2016 y un aumento repentino simultáneo en las ventas de coprocesadores a partir de ese mismo año. Ese, por supuesto, fue el año en que la IA, más específicamente, el deep learning, entró en escena. Rápidamente se hizo evidente que las CPU de uso general no podían manejar cargas de trabajo de IA que requieren mucha energía.
¿Qué quiero decir con que “requieren mucha energía”? La IA se basa en cálculos matemáticos y estadísticos sofisticados. Tomemos, por ejemplo, análisis de imágenes y videos. Las imágenes se convierten en matrices, con cada píxel representado por un número. Millones de matrices más sus clasificaciones se introducen en una red neuronal para su correlación. Las matrices se multiplican entre sí para encontrar el resultado correcto. Para acelerar este proceso, debe hacerse en paralelo en muchos más núcleos de los que pueden proporcionar las CPU.
Las CPU están diseñadas para el procesamiento en serie y están cerca de alcanzar su máximo potencial debido al tamaño y costo de sus núcleos. Por lo tanto, el aumento de diferentes tipos de CPU, así como aceleradores como GPU y procesadores diseñados a medida (ASIC, FPGA). Estos aceleradores tienen arquitecturas paralelas masivas con cientos o incluso miles de núcleos en un troquel que ofrecen de manera asequible el rendimiento de cómputo paralelo necesario.
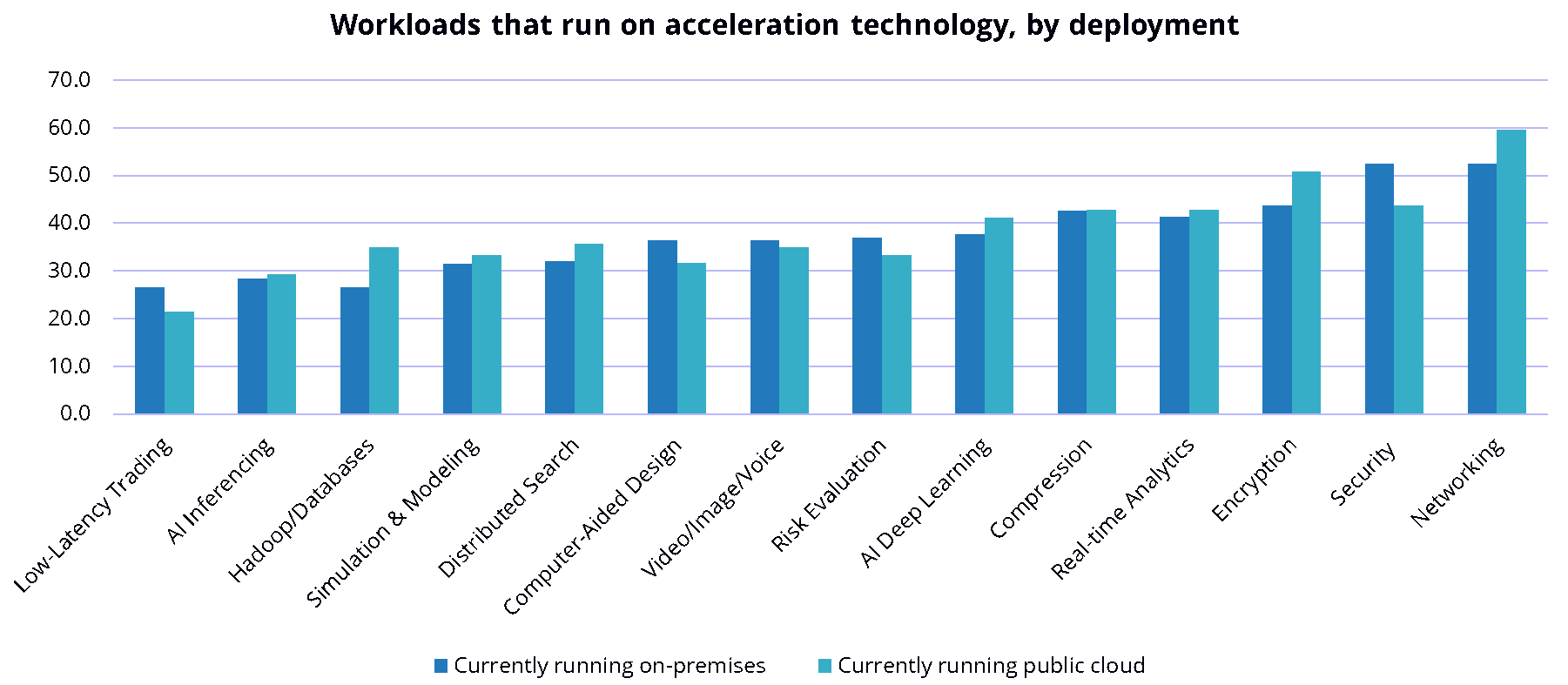
El paradigma de rendimiento de la IA es la computación paralela masiva (MPC). Las cargas de trabajo de IA (pero también el análisis de datos grandes y la simulación y modelado) requieren un rendimiento que solo se puede lograr con nodos de servidor agrupados que albergan múltiples coprocesadores que contienen miles de núcleos, núcleos tensoriales en una GPU, por ejemplo. Los coprocesadores, generalmente GPU, FPGA o ASIC, se están utilizando para mejorar el rendimiento en varias cargas de trabajo. Las cargas de trabajo aceleradas más comunes en la actualidad son las redes, la seguridad, el cifrado, el análisis en tiempo real y la compresión, seguidas de cerca por la capacitación de deep learning de inteligencia artificial.
La lucha para compensar el rendimiento limitado del procesador host no es exclusiva de IA
La supercomputadora más rápida del mundo en 2019, Summit, se construyó con miles de nodos, cada uno con 2 procesadores IBM POWER9 y 4 GPU NVIDIA V100. Cada año, el Supercomputer Top 500 enumera más sistemas que aprovechan dichos coprocesadores en lugar de depender únicamente de las CPU.
La misma encuesta a la que se hizo referencia anteriormente muestra que las empresas logran entre un 58 y un 73 por ciento de mejoras de rendimiento gracias a la aceleración con coprocesadores. Lo hacen a expensas de un aumento de CAPEX (si está en las instalaciones) u OPEX (si usa un CSP) entre 26-33 por ciento.
Esas son estadísticas decentes, pero hay una preocupación fundamental que se ha introducido en la discusión: ¿es realmente suficiente? Kunle Olukotun, profesor de ingeniería eléctrica y ciencias de la computación en la Universidad de Stanford y cofundador de la empresa emergente de hardware de inteligencia artificial Samba Nova ha declarado: “Las organizaciones se están conformando actualmente con soluciones temporales costosas que se están combinando para ejecutar aplicaciones de inteligencia artificial. Se necesita una arquitectura radicalmente nueva”.
Hay muchas nuevas empresas en la categoría de infraestructura de inteligencia artificial especialmente diseñada, y espero que una o más de ellas tengan un impacto significativo en el futuro cercano.
Sin embargo, los grandes titulares de procesadores (IBM, Intel, AMD, Xilinx, Google, AWS y NVIDIA) han estado innovando agresivamente para resolver la brecha de rendimiento.
¿Cuál será el resultado de toda esta innovación? Ante todo, más potencia para la IA. ¡Mucho más! Pero también, algo de caos competitivo en el mercado de infraestructura de IA. Las startups de procesadores deberán continuar sus esfuerzos de financiación (las startups de procesadores no son baratas) mientras crean ecosistemas de software y asociaciones OEM y CSP de servidores. Los incumbentes del procesador compiten para obtener la aceptación de los OEM y CSP del servidor, la única excepción es IBM, que construye sus propios servidores optimizados para IA con sus propios procesadores, tanto para Power Systems como para IBM Z. TI tendrá que evaluar qué procesador la plataforma garantiza invertir. Mi consejo para TI sería:
- Los problemas de rendimiento con IA son generalmente el resultado de una paralelización insuficiente de la infraestructura en la que se ejecuta la carga de trabajo de IA. La infraestructura de IA se basa cada vez más en MPC, lo que significa grupos de nodos de servidores acelerados con interconexiones rápidas.
- Realizar un seguimiento de las nuevas tecnologías de procesador de IA. Si bien algunos todavía no se esperan durante varios años, otros están disponibles hoy, especialmente los de los grandes titulares. Solicite información al proveedor de su servidor cuál es su postura con respecto a los requisitos de rendimiento emergentes en términos de nuevos procesadores, coprocesadores, interconexiones o combinaciones de estos.
- No tenga miedo de construir una infraestructura de computación de IA heterogénea, incluso si eso significa un poco más de complejidad que con un entorno 100% homogéneo: la IA lo requiere. Recuerde que la infraestructura heterogénea ya no es complicada como solía ser gracias a las capas de código abierto que se abstraen del hardware (piense: Linux, contenedores, Kubernetes, etc.)
En resumen: para lograr la potencia que necesita para la IA, aproveche la diversidad. Hable con sus científicos de datos y desarrolladores de IA sobre la paralelización de la infraestructura. Luego, investigue las plataformas que quizás no haya tenido antes en el centro de datos, plataformas con diferentes procesadores, coprocesadores e interconexiones para una mejor paralelización. Su rendimiento de IA dependerá de ello.
Para obtener más información sobre la infraestructura para la IA, puede leer mi documento IDC, Rethinking Your Infrastructure for Enterprise AI.