IBM Power Systems: soluciones de alta disponibilidad (HA) y recuperación de desastres (DR)

La alta disponibilidad de un centro de datos es una de las características más críticas e importantes para la infraestructura de TI, principalmente en un mundo conectado 24/7. Y esa disponibilidad puede verse afectada no sólo por un error humano, pero incluso por situaciones previsibles, tales como desastres naturales o incluso actos terroristas.
Por lo tanto, un buen plan de alta disponibilidad y recuperación de desastres puede ser un punto clave para reducir los riesgos de continuación de su negocio. Aprenda en este artículo cómo los entornos IBM Power Systems ofrecen soluciones de alta disponibilidad y recuperación de desastres.
1 – Soluciones de Alta Disponibilidad (High Availability – HA)
Un sistema de alta disponibilidad es un sistema resistente a fallas de hardware, software y energía, cuyo objetivo es mantener los servicios disponibles el mayor tiempo posible.
- Cluster
Las soluciones de cluster son plataformas específicas que proporcionan acompañamiento detallado de monitoreo de software y de hardware en el cual automáticamente le proporciona alta disponibilidad en caso haya algún problema (failover), aunque requieran un esfuerzo considerable para implementar y mantener.
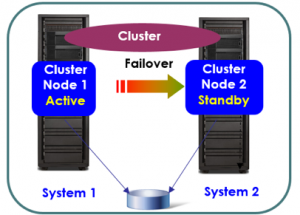
En ambientes IBM Power Systems, esta solución está disponible para AIX y IBMi por PowerHA Standard Edition, un producto robusto que está en el mercado desde hace más de 15 años y con varias implementaciones realizadas con éxito en el mundo. En ambientes Linux, está disponible por el software de terceros, tal como TSA (IBM Tivoli System Automation). En la versión PowerHA Standard también es posible, por medio de mirroring vía AIX LVM, la configuración del clúster entre dos sites, en cuanto la replicación esté sincronizada por el AIX LVM.
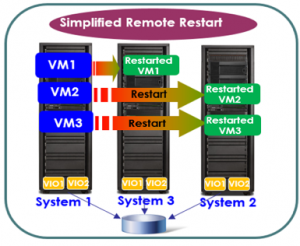
- VM (Virtual Machines) Restart
VM Restart es una plataforma capaz de reiniciar manualmente las VMs, entre otros servidores con los recursos disponibles en el momento exacto en el que ocurre un problema en un servidor (Frame). En el ambiente IBM Power Systems, esta función está disponible para Simplified Remote Restart. Esta herramienta ya está incluida en los modelos Power 8, cuando son adquiridas con PowerVM Enterprise Edition, sin la necesidad de costo de licencia adicional.
2 – Soluciones de recuperación de desastres (Disaster Recovery DR)
La recuperación de desastres consiste en un conjunto de políticas y procedimientos para permitir la recuperación o continuación de la infraestructura de la tecnología y los sistemas críticos de negocio después de un desastre natural o provocado por el hombre.
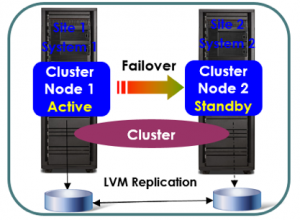
- Cluster
En ambientes Power Systems, esta solución está disponible para AIX e IBMi por PowerHA Enterprise Edition, actuando integrado con storage, gerenciando también sus actividades y la replicación para organizar la actividad de DR en algún momento de falla.
Los PowerHA IBM Storage Systems DS8880, SAN Volume Controller (SVC) V7000 y XIV con replicación IBM TotalStorage Global Mirror o Metro Mirror (sincronizada o no), permite automáticamente el movimiento entre sites. La versión Enterprise Edition también soporta la replicación multi-site para storages EMC y Hitachi para AIX.
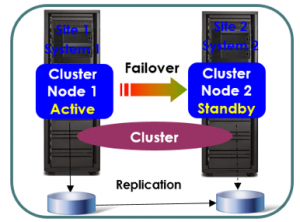
- Geographically Dispersed Resiliency
Los ambientes IBM Power Systems ahora ofrecen una solución de DR basada en restart de VM. El Geographically Dispersed Resiliency GDR se integra perfectamente con los ambientes PowerVM (HMC, VIOS) para proporcionar una reinicialización de máquinas virtuales en sites usando imágenes de las VMs replicadas através de almacenamiento. La solución GDR Disaster Recovery es fácil de implementar y gestionar. El GDR puede gestionar una recuperación de centenas de VMs automáticamente entre sites. Está disponible para VMs AIX y Linux.
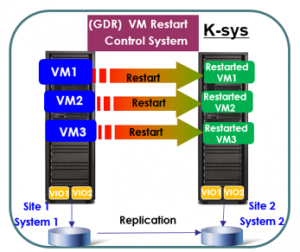
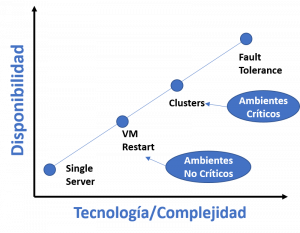
3 – Comparación de las soluciones (Grupo X VM Restart)
Las soluciones de HA-DR basados en cluster son las mejores para proteger cargas de trabajo críticas. Por ejemplo, los ambientes SAP. El HA basado en clúster sería el mejor método para monitorear y actuar sobre varios componentes (software y hardware). Para otras cargas de trabajo, un modelo basado en la reinicialización VM puede ser suficiente protección para HA y DR. La siguiente figura capta el nivel de HA/protección vs. la complejidad de la implementación para estas tecnologías.
| Solución | Cluster | VM Restart |
| Implementación | Implementación en cada VM (complejo) | Implementación fuera de VM (simple) |
| Workload Failover Time | Rápido | Reiniciar la VM y las aplicaciones |
4 – Herramientas PowerVC para alta disponibilidad
El PowerVC ofrece virtualización y gestión de Cloud en ambientes Power Systems y aprovecha OpenStack para hacerlo. El PowerVC introdujo las funciones de gestión de alta disponibilidad en sus últimas versiones. A continuación se muestra un resumen de estos recursos:
- One-click system evacuation:
Durante los periodos de mantenimiento planificados, este recurso permite a los administradores evacuar un servidor (Frame), activando el Live Partition Mobility (LPM). El PowerVC organiza el LPM de todas las máquinas virtuales activas para otros servidores disponibles en el ambiente (o un Frame de su elección), permitiendo que el mantenimiento, como firmware o actualizaciones VIOS, sean realizadas sin interrumpir las cargas de trabajo. Mientras que el Frame está en modo de mantenimiento, el PowerVC no colocará nuevas VMs en este host. Una vez que se realiza el mantenimiento, las VMs pueden ser colocadas en el Frame nuevamente y el funcionamiento normal se puede reanudar.
- Automated remote restart
El Automated remote restart monitora los Frames en caso de falla usando el servicio HA de PRS (Platform Resource Scheduler). Si un Frame fallara, el PowerVC reinicia automáticamente las máquinas virtuales del Frame con falla para otro Frame dentro de un grupo de hosts.
5 – Servicios de LAB Services
El equipo de LAB Services cuenta con un equipo altamente cualificado de consultores que pueden ayudar a evaluar la alta disponibilidad de su ambiente de IBM Power Systems, así como ayudar a implementar la mejor solución de DR. Para obtener más información, visite el site.