量子コンピューティング
量子中心のスーパーコンピューティングの実現
2024-11-29
カテゴリー IBM Research (コンピューティング) | 量子コンピューティング
記事をシェアする:
(特別な工夫のない)愚直な古典計算では扱えないレベルの大規模な問題を解決できる能力を持った 実用規模の量子コンピューターが、ハイパフォーマンス・コンピューティングの未来を変えていきます。

歴史上初めて、コンピューティングは2つの道に別れました。2進数を表現するトランジスタ数の増加をひたすらにたどる1本道だけではなく、根本的に異なる計算アーキテクチャーをも私たちは既に手にしているのです。量子ビットというこの新しいアーキテクチャーは、古典コンピューターでは長い間手が届かなかった問題に速度向上をもたらす可能性を持っています。
一方で、量子コンピューターがどんな問題も古典的なスーパーコンピューターより効率的に解決できるわけではないということも既に判明しています。その代わりに、量子プロセッサー(QPU)はハイパフォーマンス・コンピューター(HPC)のアクセラレーターとして機能し、異種混在計算モデルの一部として、特別に計算困難な一部の問題について CPUと GPUをアシストすることが期待されています。この新しいスーパーコンピューティング・パラダイムを私たちは「量子中心のスーパーコンピューティング」と呼んでいます。
2023年のユーティリティー実験は、現在の量子コンピューターの有用性を示す最初の証拠を示しました。その研究は、100量子ビット以上の実用規模があって量子エラー緩和を使えば、ノイズの影響を受けている量子コンピューターであっても、愚直な古典シミュレーションを超える計算を実行できるということを示しました。
それ以来、私たちは、実用規模の量子コンピューターをHPCリソースと結合して、古典的なHPC計算アーキテクチャーだけでは不可能なレベルのワークロードを実行できるようになると述べてきました。そしてこの未踏の計算領域では実際に、実験道具として量子コンピューターを使って研究者たちが科学探索を加速している例がすでに増え続けています。
最近 SC24会議において、IBMはこれからの量子中心のスーパーコンピューティングのビジョンを示し、HPCユーザーをこの旅にお誘いしました。量子有用性が実証されて以来、開発者たちはIBMの量子システムを使用して実際の科学的研究作業を行っているわけですが、量子技術がますます成熟していくのに加え、IBMは、古典的なHPCと量子のリソースの結合も進めることで、量子が可能にする科学発見の新しい時代にHPCユーザーを引き込んでいます。その結合を担うのは、Slurmといったリソース管理システムです。
量子計算で古典計算を加速
コンピューティングの将来は、量子 vs 古典の単純な対立構図ではありません。新しいアルゴリズムの発見のためには、量子コンピューティングと古典コンピューティングの両方を使用することが必要となります。テンソルと量子回路で表現される線形代数の問題に落とし込める興味深い問題があります。そして、量子コンピューターが古典コンピューターよりも回路の実行に適していることは明らかです。こういったことは、私たちの量子ユーティリティー実験が実際に示したことでした。
したがって、IBM Quantumの目標は、この種の問題でサブルーチンとして使えるような、高速かつ正確な回路を実行可能にすることです。ハードウェアとソフトウェアのパフォーマンスを向上させて、より長い回路をより正確に実行できるようにして、量子リソースと古典的なリソースを同時に必要とする問題で、量子がボトルネックにならないようにする必要があります。
古典計算で量子計算を加速
実際の量子コンピューターで実行される量子回路の結果をさらに正確にする必要がありますが、現在の量子コンピューターは、影響を緩和または訂正しなければならないノイズによって結果がバイアスされています。そして今、フォールト・トレラントな量子コンピューター(fault-tolerant quantum computer)を実現するための手法を用いようとすると、まだどんな量子コンピューターでも実現されていないレベルの大規模な物理的資源がオーバーヘッドとして必要です。
Fe4 S4 硫化鉄分子のモデルを例にとってみましょう。 古典コンピューターでこの系の完全なモデル化が不可能だということは知られています。そして、現代の量子コンピューターでは、ノイズが多く浅い量子回路を最大限に活用するように設計された手法を使ったとしても、この計算に何百万年もかかることが判明しています。将来的に453万個の物理的な量子ビットにアクセスできるフォールト・トレラント量子コンピューターが実現できれば、今と同じ手法を使用してこの問題に対処することができますが、それでもそのシステムには 13日間の実行時間がかかることが推定されています。
しかし、量子中心のスーパーコンピューティングでは、最先端の古典手法よりも高い精度で推定値を得られる可能性を持った、新しい一連の手法を用いることができます。
例えば、サンプル・ベースの量子対角化(SQD、sample-based quantum diagonalization )は、量子コンピューターを使用して、分子の可能な電子構成の分布を、誤差込みの推定値を計算してビット列の形式で得る化学シミュレーション手法です。 そして、このビット列を正しい電子構成のまとまりにクラスタリングするために、反復的な補正処理を古典コンピューターで実行します。 この手法は、ノイズを持った量子コンピューターでも十分大規模で十分低いエラー率を持っていれば、古典的な近似手法よりも効率的に実行できる可能性があります。
IBMのパートナーである理研と Cleveland Clinic Foundationは、SQDを使用した実験の結果を公開しましたが、これは量子中心のスーパーコンピューティングが、フォールト・トレランスなしでは実行不可能と以前考えられていた新しい応用領域を開けることを示す有望な証拠になっています。
古典計算と量子計算を一つのユーザー体験に統合する
SQDのような量子中心のスーパーコンピューティング手法は、QPUと CPUを単に接続するだけでは実現できません。量子開発者と古典の開発者が期待するポイントを単一のユーザー体験に組み合わせる必要があります。私たちは量子ワークロードに対応できるように HPCワークロード管理システムをアップグレードすることでこれを実現します。
データセンターやスーパーコンピューターの施設は、ワークロード管理システム(WMS)を使用してリソース管理やジョブ・スケジューリングを行っています。 ワークロード管理システムは、どんなリソースがいつ利用できるかを把握し、リソース要件に基づいてタスクを効率的に実行します。有名なリソース管理システムには、Slurm、LSF、PBSなどがあり、これらは一見異なるように見えますが、リソース、ノード、タスク、キューといったような共通した中心的概念を持っています。
- リソースとは、CPU、GPU、メモリー、および QPUなど、計算インフラストラクチャーの単位です。
- ノードとは、計算リソースのセットを 1つのエンティティーにまとめた抽象化です。
- タスクとは、関連するリソース要件を持った一つの計算単位やプログラムです。
- キューとは、タスク実行管理のメカニズムです。
ワークロード管理システムを利用する HPC開発者をペルソナとして想定すると、彼らは以下の図のように計算をタスクのグラフとして記述するかもしれません。
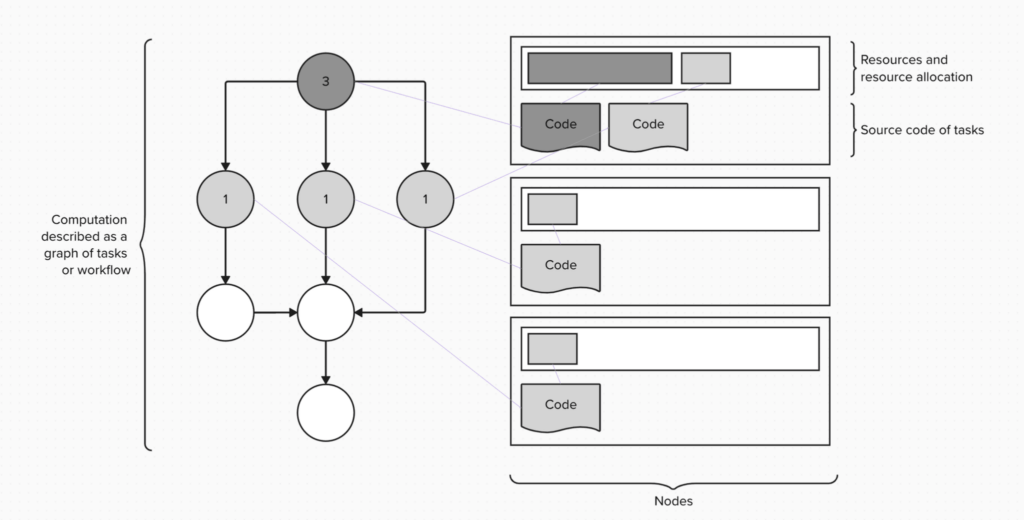
現在、量子コンピューターのプログラミングは、Qiskitソフトウェア・スタックを基礎とした、古典とは異なるプログラミング・ワークフローを必要としています。量子計算科学者は、Qiskitプリミティブを使用して量子コンピューターとやりとりします。 Qiskitプリミティブとは、回路の形式をした量子計算から出力を取り出すための、計算処理の抽象化です。Qiskitプリミティブには2種類があります。Samplerは、量子回路から得られる出力の分布からサンプリングを行います。Estimatorは、回路から得られる結果の期待値や重み付け平均値を計算します。
2つのコンピューティング・パラダイムを組み合わせるということは、計算のうちの量子部分の実行を行うために、全体的な計算ワークフローのタスク内で Qiskitプリミティブを呼び出すことになります。そして WLMは、計算の割り当てに新しいタイプのリソースである、量子プロセッサー(QPU)を使用します。
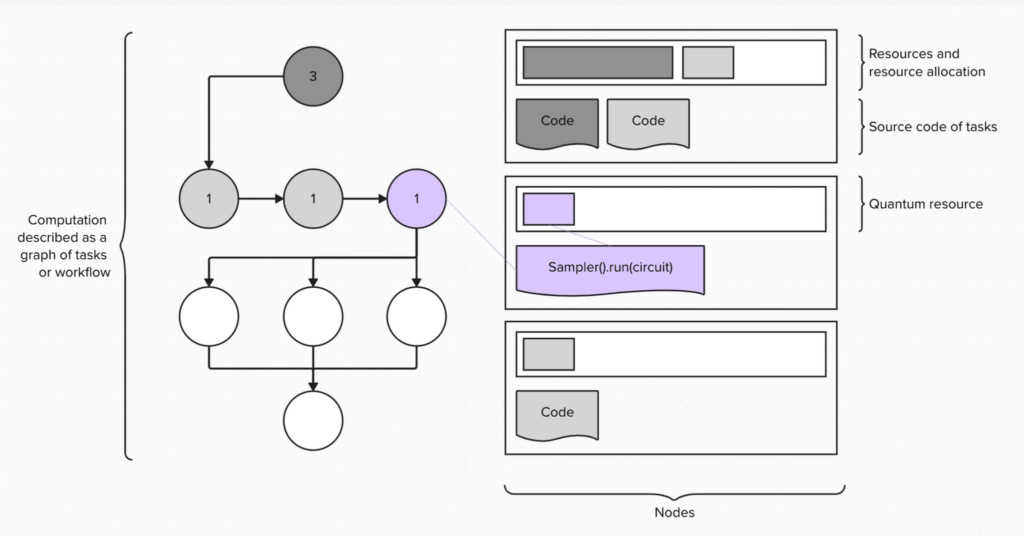
QCSCアーキテクチャーの設計
量子・古典のハイブリッドな計算フローを処理するには、適切なアーキテクチャーが必要です。ここでは、例として複数のアーキテクチャーを示し、それらの利点と欠点を検討し、次に QCSCアーキテクチャーで SQDワークフローを実装して、Slurmで実行する方法をご紹介します。
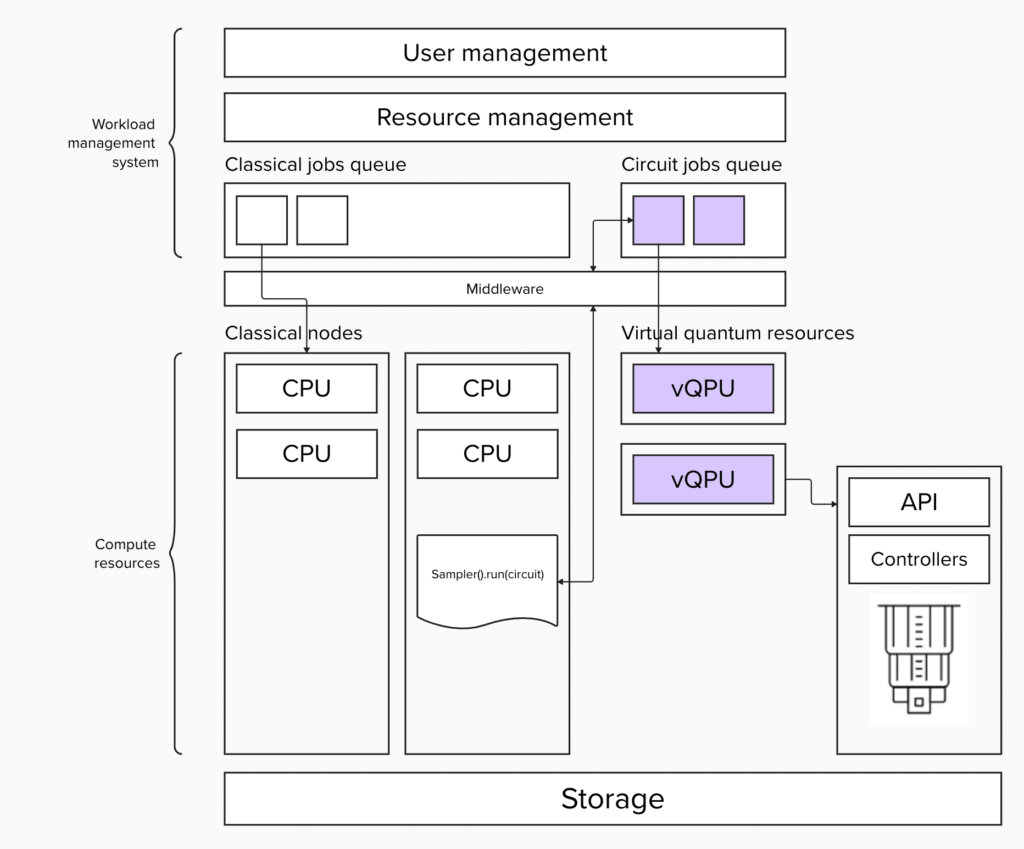
最初のアーキテクチャーでは、古典ジョブと量子ジョブを分離します。 量子ジョブは、Qiskitプリミティブである Sampler または Estimator単体の実行です。リソースの種類ごとにキューを分離することで、キューは常に特定種類のプリミティブ・ジョブで飽和するため、量子デバイスの使用率を向上させることができます。
ただし、並列キューを利用する結果として、投入されたジョブの順序が保たれない可能性があります。 先に開始した他の Qiskitプリミティブ・ジョブで QPUが占有されている可能性があるため、古典ジョブの開始時刻が早くても必要な時にQPUがタイムリーに使用できることは保証できません。 したがって、QPUの使用率の方が古典的なリソースよりも高い優先度を持ちます。これは量子リソースの方が希少だからです。
次の可能性として、ハイブリッド・モデルも考えられます。これは量子リソースを他のリソースと同様に扱い、統合システムのすべてのジョブをハイブリッド・ジョブであるとみなします。 そして実行する時になって各ジョブに実際に必要なリソースの種類に基づいてリソースを割り当てます。その際には、vQPUリソース(仮想化されたQPUリソース)も定義します。 この vQPUリソースを持つノードだけが、量子コンピューターのAPIにアクセスできます。
このアプローチでは、ひとつの量子・古典ハイブリッド・ジョブが実行を始めると、このジョブに必要なすべてのリソースがジョブの実行期間全体にわたってブロックされます。これは、古典と量子リソース間の緊密なループを必要とするアルゴリズムには有用です。しかしこのアプローチの欠点は、ジョブの実行期間全体にわたって量子リソースがブロックされるため、量子システムの使用率が低下することです。
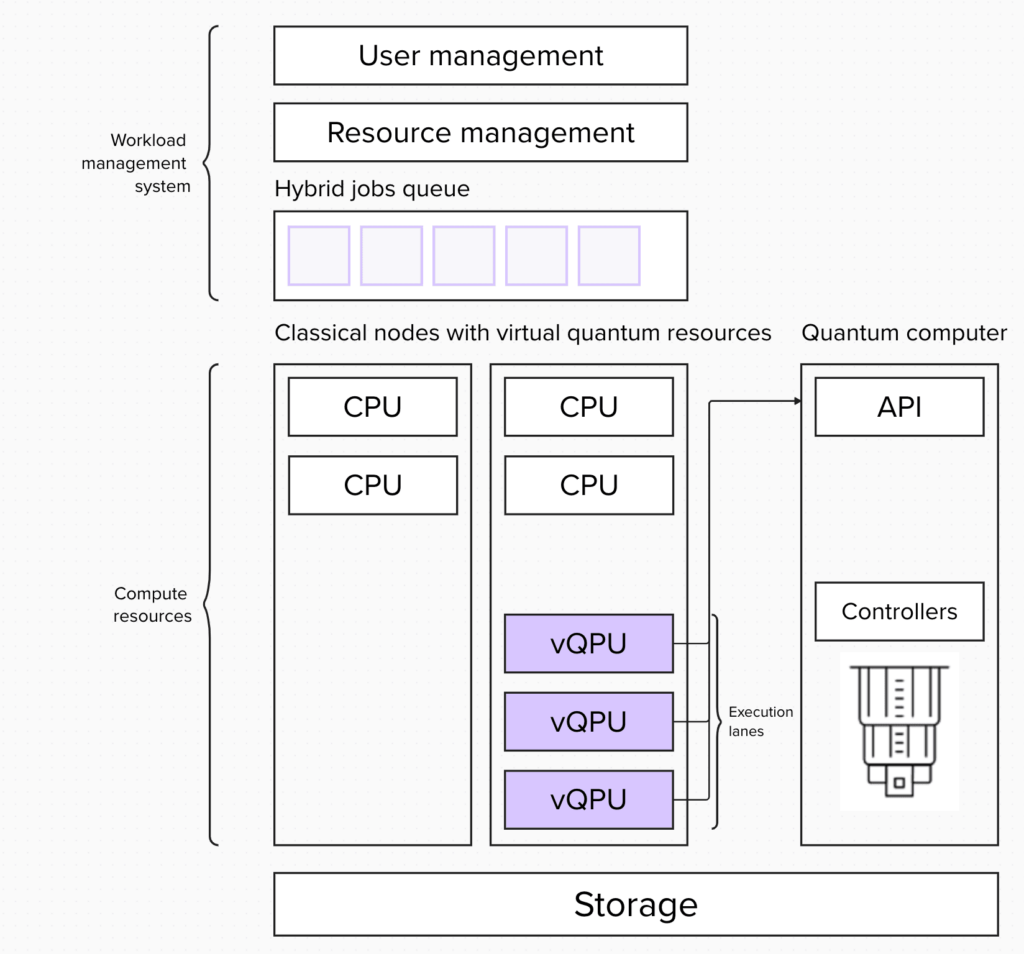
最後に、混合モデルを考えてみましょう。これは構成によって欠点を緩和しながら、上記の2つの戦略の利点を組み合わせます。この種類のアーキテクチャーは、より複雑な構成と開発が必要になりますが、ハイブリッド・キューと古典キューへのジョブ投入を切り替えることによって、必要な時に古典と量子との間の緊密な統合が可能になります。
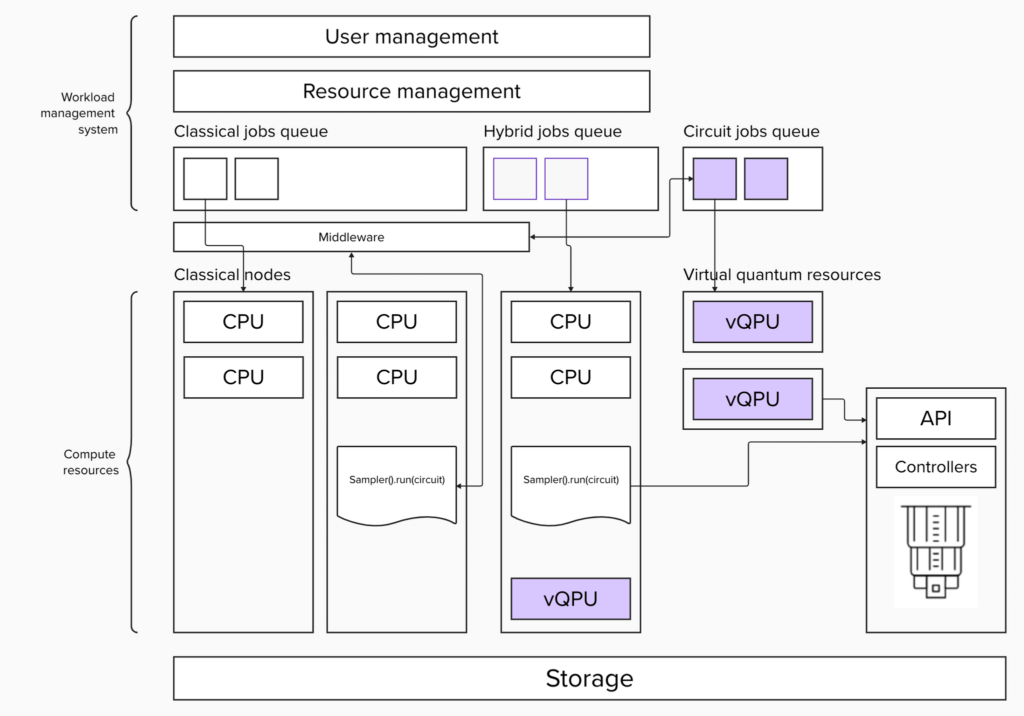
上述のようなアーキテクチャーは既存のワークロード管理システムで実現することができます。そのうちの並列キュー・アーキテクチャーを取り上げて、Slurmに適用してみましょう。 単純な実装では、3つのコンポーネントが必要になります。プリミティブを実装するクライアント、クライアント・コールを処理するミドルウェア、そして量子システムの APIと通信するプリミティブ・ジョブ・ロジックです。
これらはいずれも比較的簡単に実装できます。クライアントについては、Qiskitプリミティブの基本クラスを拡張する必要があります。ミドルウェアは、Slurm rest または central daemonコマンドのプロキシーのように機能するマイクロサービスを作成する必要があります。ジョブは、量子システム APIへの呼び出しです。
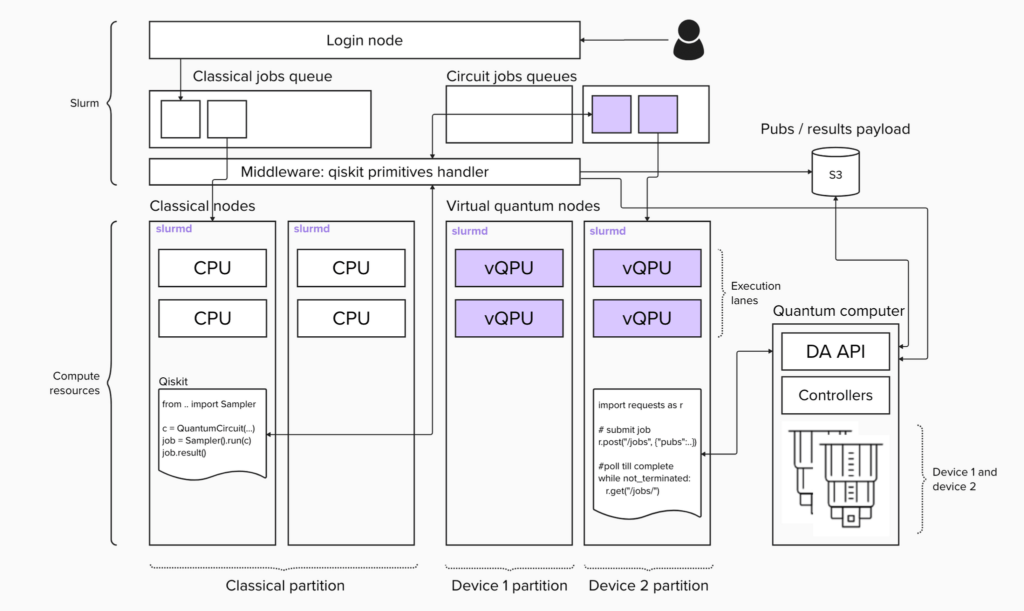
さて、それではSQD手法をベースにして 量子・古典ハイブリッド・プログラムを作成し、この統合環境で実行してみましょう。どんな量子計算でもそうであるように、問題の量子回路への落とし込み、最適化、実行、後処理の4ステップを踏む必要があります。
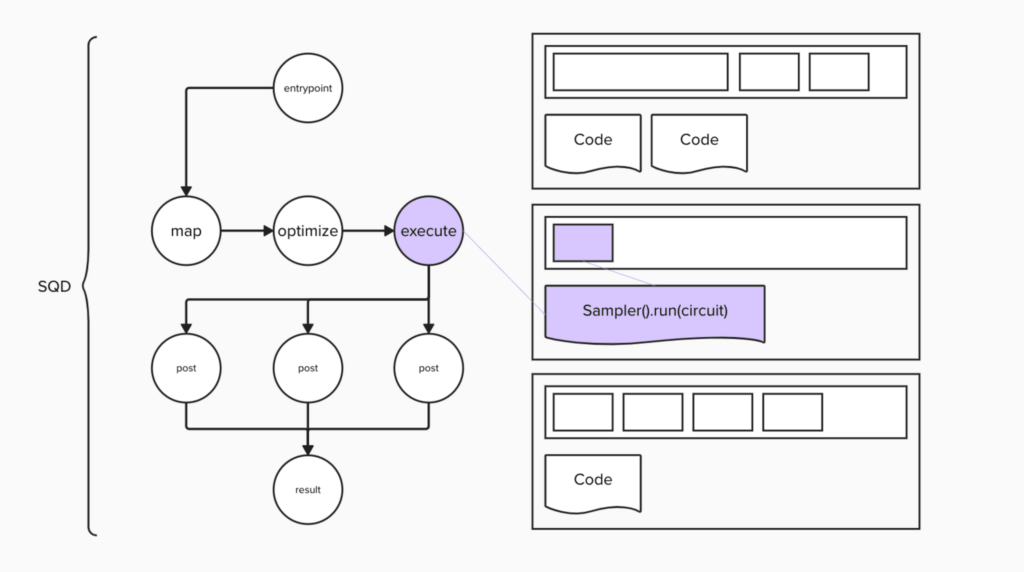
このプロセスの各ステップについて、ジョブ・スクリプトと Slurmへの投入スクリプトを作成します。 まず、分子の完全な配置間相互作用を回路に落とし込みます。
map.py
from … import LUCJCircuit
lucj_circuit = LUCJCircuit.from_fci(“n2_fci.txt”, …)
with open(“lucj_circuit.json”, “w”) as f:
map.sh
#SBATCH –job-name=map
srun python3 map.py
最適化ステップでは、回路を目標バックエンド用に最適化された ISA回路に変換します。ここで、実装済みのクライアントを使用して、使用可能なバックエンドの仕様を取得します。
optimize.py
from … import SlurmServicebackend = SlurmService().get_backend(“heron_1”)
pass_manager = generate_preset_pass_manager(
backend=backend,
initial_layout=initial_layout
)
with open(“lucj_circuit.json”) as f:
with open(“isa_circuit.json”, “w”) as isa_f:
optimize.sh
#SBATCH –job-name=optimizes
run python3 optimize.py
実行ステップでは、Samplerを利用するクライアントを再び使って、バックエンドに対して ISA回路を実行します。
execute.py
from … import SlurmService, Sampler
backend = SlurmService().get_backend(“heron_1”)
sampler = Sampler(mode=backend)
with open(“isa_circuit.json”) as f:
job = sampler.run([isa_circuit], shots=10_000)
primitive_result = job.result()
pub_result = primitive_result[0]
counts = pub_result.data.meas.get_counts()
with open(“counts.json”, “w”) as counts_f:
execute.sh
#SBATCH –job-name=execute
srun python3 execute.py
後処理ステップでは、エネルギーを回復するために並列計算を利用して SQD手続きを使用します。
postprocessing.py
from mpi4py import MPI
comm = MPI.COMM_WORLD
size = comm.Get_size()
rank = comm.Get_rank()
…
with open(“counts.json”) as f:
print(f“Starting configuration recovery.”)
batches = None
if rank == 0:
batches = comm.scatter(batches, root=0)
energy_sci = solve(batches, …)
energies = comm.gather(energy_sci, root=0)
if rank == 0:
postprocessing.sh
#SBATCH –job-name=postprocessing
#SBATCH –ntasks=10
srun python3 postprocessing.py
これで、このワークフローを実行するために必要なものがすべて揃いました。単純化するためにジョブをチェーンにしますが、実行グラフを構築するのにワークフロー管理ツールはどれでも使用できます。
OPTIMIZE_JOB=$(sbatch –parsable –dependency=afterok:$MAPPING_JOB optimize.sh)
EXECUTE_JOB=$(sbatch –parsable –dependency=afterok:$OPTIMIZE_JOB execute.sh)
POSTPROCESSING_JOB=$(sbatch –parsable –dependency=afterok:$EXECUTE_JOB postprocessing.sh)
Slurmキューを調べて、ジョブとプリミティブの実行状況を確認できます。
# JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
# 12 heron_1 21ebc89f root R 0:01 1 q3
# 11 main execute root R 0:12 1 c1
このアーキテクチャー概要は、ユーザーの既存利用パターンを妨げることなく、HPCインフラストラクチャーに量子を取り込むためのシンプルな統合計画を提供します。この統合環境を使用するユーザーの学習曲線はゼロに近いですが、これは元の構成への依存関係を維持し、既に多くのユーザーが利用している仕組みを再利用しているからです。
IBMは、量子中心のスーパー・コンピューティングの探索を開始するために必要なハードウェアとソフトウェアのツールをすでに提供しています。2024年11月に、IBMは、量子コンピューターが正確な古典的なシミュレーションを超えた領域である 5,000ゲートを含んだ回路を実行できることを示しました。
また、IBMはユーザーに量子を使いやすくする一連の機能についてもデモを行いました。これには、SQDなどの最先端手法の実装パッケージである Qiskitアドオンと、IBMとサード・パーティーが提供する量子アプリケーション開発を最適化するためのホステッド・サービスである Qiskit Functionsがあります。
読者の皆さんも、有用な量子コンピューティングを実現するために、量子中心のスーパー・コンピューティングの探索を始めてみてください。
この記事は英語版IBM Researchブログ「Demonstrating a true realization of quantum-centric supercomputing」(2024年11月20日公開)を翻訳し一部更新したものです。

IBM Quantum, シニア・テクニカル・スタッフ・メンバー, QCSC Softwareマネージャー
Qiskit-Aerの開発、量子コンパイラーの高性能化を担当後、量子中心型のスーパーコンピューティングにおけるソフトウェア開発を担当。


2年前に設定したチャレンジを達成した IBM Quantum
今回が初回となる IBM Quantum Developer Conferenceで、IBMはアルゴリズム探索を容易にする高性能な量子コンピューターと使いやすい量子ソフトウェアを発表しました。 IBM®は 2年前に、量子 […]
実用規模のワークロードで量子回路の深さを削減するフラクショナル・ゲート
フラクショナル・ゲートは、実用規模の実験の効率を向上するのに役立つ新しいタイプの量子論理ゲートです。 IBM® は、IBM Quantum Heron™ QPUに新しい種類の量子論理ゲートを導 […]

量子スピン鎖の大規模シミュレーションを行う量子アルゴリズム
Stony Brook大学の研究者は、計算能力の限界を押し進めて実用規模のスピン鎖シミュレーションを可能にするために、さまざまな量子シミュレーション手法を組み合わせて改良しています。 量子計算の起こりがいつ […]