量子コンピューティング
量子中心のスーパーコンピューターに必要なサーキット・カッティングを可能にするダイナミック・サーキット
2024-12-22
カテゴリー IBM Research (コンピューティング) | 量子コンピューティング
記事をシェアする:
Natureに掲載された新しい論文は、一つの量子プロセッサーでは実行不可能なサイズの量子回路を、二つの量子プロセッサーを接続して実行できることを世界で初めて示しました。

今日、世界で最も強力な古典的スーパーコンピューターは、1個の CPUや GPUだけを備えた 1台のデバイスではありません。それはハイ・パフォーマンス・コンピューティング(HPC)クラスターと呼ばれるマシン群で、数百、時には数千ものCPUや GPUが協調動作し、世界で最も困難な問題に対処しています。量子コンピューターの未来はこれによく似た様子になるだろうと私たちは考えており、今回の新しい研究はその未来が思っているよりも近いことを示しています。
IBMは、100量子ビットやさらには 1,000量子ビットの壁を超えて超伝導量子プロセッサー(QPU)の規模拡大をしてきましたが、量子コンピューターに真の価値を発揮させるためには複数の QPUを結合するマルチ QPUアプローチが必要だということが一層明らかになってきました。現在の古典的な HPCクラスターと同様に将来の量子コンピューターでは複数のプロセッサーが協力して、一つの QPUでは実行できないレベルの大規模で複雑な回路を実行するようになると考えられます。最近 Natureに公開した新しい論文で私たちは、この道のりにおける重要なマイルストーンの一つとして、2個の QPUを接続して、1個のプロセッサー単独の規模を超えた回路を実行できることを示しました。
この研究は、量子中心のスーパーコンピューティング (QCSC) のビジョンに向けた重要な進展です。QCSCは、量子と古典の計算リソースを統合して、古典的なコンピューティングのみでは実行できない並列ワークロードを実行するという、これからのハイパフォーマンス・コンピューティング・フレームワークです。数週間前に私たちが公開したブログでは、理研や Cleveland Clinic Foundationといったパートナーが、 既存の古典的な HPCシステム上で QCSCフレームワークを使って 量子・古典のハイブリッド計算ワークロードの実験をしている模様を紹介しました。しかしこれらのプロジェクトは、始まりにすぎません。
QCSCでは、CPU、GPU、QPUがそれぞれ最も得意とするアルゴリズムの部分を解くことができるように、複雑な問題を簡単に分割する高性能ソフトウェアが必要になります。そしてさらに、そのように問題を量子部分と古典部分に分解したとしても、QCSCのワークロードのうち量子部分はなお複雑な回路を含む可能性が高く、複数の QPUを協調動作させる必要があります。これを私たちはモジュール型の量子コンピューティングと呼びます。
IBMは、複数の QPUを組み込むことができる IBM Quantum System Twoなどの革新的なシステムと、量子回路の操作や分割などを行う高性能ソフトウェアの開発によって、モジュール型の量子コンピューターの基盤を何年もかけて構築してきました。私達の新しい Nature論文は、ダイナミック・サーキット、サーキット・カッティング、そして複数の量子プロセッサー間の古典接続といったツールと手法を組み合わせることで、モジュール型の量子コンピューティングを実証しました。
それと同時にこの研究の持つ示唆は QCSCの長期的展望についてだけではありません。現在利用可能な量子ハードウェアでいま探索できるアプリケーションの範囲も拡大しているのです。本ブログでは、この研究で開発した新しい機能が、現在の量子ハードウェアでシミュレートできる系の規模を大幅に向上させるものであることを説明します。しかしこれらの短期的な見通しを示す前に、まず、将来のモジュール型の量子中心スーパーコンピューター・フレームワークに向けて前進するために、これらの機能をどのように使用し 2個の量子プロセッサーを1個のものとして扱ったのかについて詳しく見てみましょう。
2個のQPUを 1個として動作させる方法
私たちの実験は、2個の 127量子ビット IBM Quantum Eagleプロセッサーを、古典リンクを介しリアルタイムに接続して、単一の QPUとして統合しました。その後、エラー緩和されたダイナミック・サーキットと、サーキット・カッティングと呼ばれる手法を使用して、最大 142量子ビットの量子状態を作成しました。これは1個の Eagle QPUだけでは実現できない規模の量子状態です。私たちの研究は、異なる QPU上に存在する量子ビット間でも 2量子ビット・ゲートを実行できることを実験的に示した初めての例であり、モジュール型の量子計算アーキテクチャーにおいてとても重要な機能となります。
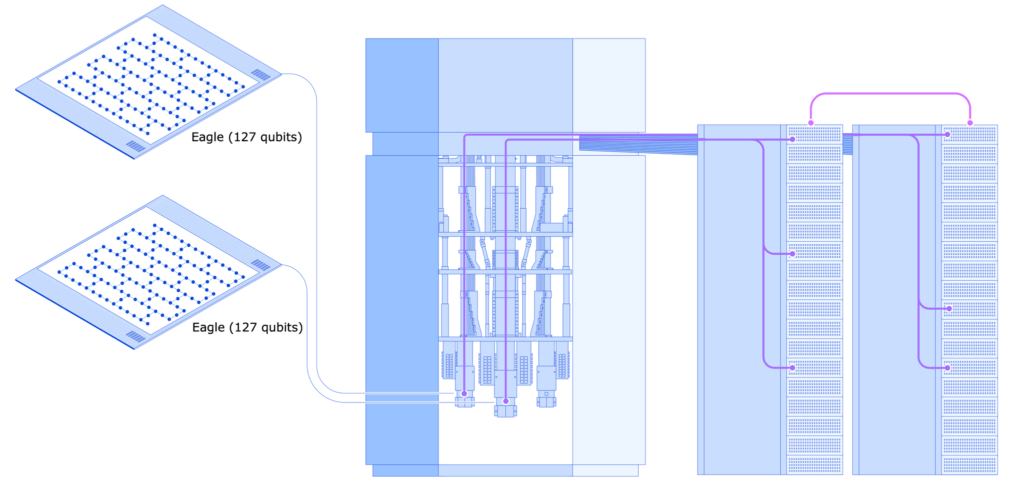
では、どのように機能するのでしょうか。まず、サーキット・カッティングから始めます。 1個の QPUでは実行できないほどの大きな量子回路がある場合、サーキット・カッティングを使用して それを個々の QPUで処理できる小さな部分回路に分解します。そしてその後、古典的な計算を使用して、これらの部分回路の実行結果を取得し、それらを統合し、最終的に、元の回路を 一つのプロセッサーで実行した場合と同等な結果を得ます。
注目して頂きたいのは、これを実現するのに、部分回路を実行する 2個の接続された QPUが実際には必要ではない、ということです。部分回路を 一つずつ順番に 1個の QPUで実行し、その後、古典的な後処理で結果を統合することもできるのです。この Nature論文では、両方のアプローチを探求し、二つの異なるサーキット・カッティング手法を比較しました。すなわち、単一の QPUでのローカル演算(LO)にのみ依存した手法と、2個の接続された QPU間の 古典通信とローカル演算の組み合わせ(LOCC)を用いる手法です。後で詳しく説明します。
いずれの場合も、サーキット・カッティングにおける最大の課題は、2量子ビット・ゲート、すなわち、量子ビットのペアを量子もつれ状態にして操作するための論理演算に関連しています。2量子ビット・ゲートは量子回路における計算複雑性の最大の要因の一つになります。複雑な回路をサーキット・カッティングを使って、比較的扱いやすい規模の複数の部分回路に分割した時でも、それら別の部分回路に含まれることになった量子ビット間で2量子ビットゲートを実行する方法が必要です。LOCC方式では、古典的な通信チャネルでのみ接続されている 2個の異なるプロセッサー上の量子ビットの間で量子もつれを、あるいはそれと等価な何かを、実現する手段が必要であるということです。
2個の QPUにまたがって 2量子ビット・ゲートを仮想的に実現するダイナミック・サーキット
もちろん、古典的な情報だけしか伝送できない通信チャネルを通して量子もつれを作ることは難題、というよりも実際は不可能です。
そこで私たちはその代わりに、仮想ゲートと呼ばれる手法を使用し、異なるプロセッサー上の量子ビット間に、もつれ状態の統計的分布を再現しました。具体的には、必要な 2量子ビット・ゲートを作成するために、仮想的な Bellペアを利用するテレポーテーション回路を作成しました。 Bellペアは 2つの量子ビット間の量子もつれの基本的なひとつの形で、仮想 Bellペアもそれに類似しています。 ただし、仮想 Bellペアは2つの量子ビット間に本物の量子もつれを実現するのではなく、複数回の回路実行を通して量子もつれの統計的分布を再現します。
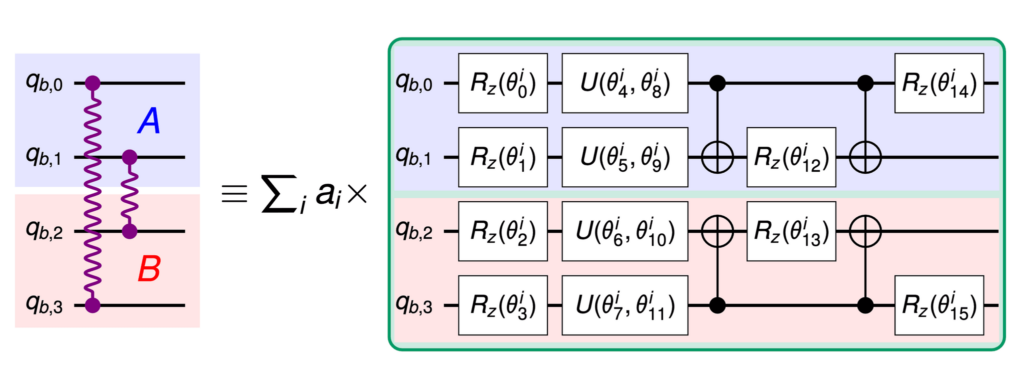
通常、異なるチップ上の量子ビット間で Bellペアを作成するには、それらの 2量子ビット間で長距離のCNOTゲートが必要になります。 CNOTゲートは、Bellペアを作成するために使われる基本的な論理量子演算です。ただし、前述のように、古典的な通信チャネルを通して量子演算を実行することはできません。この制限を回避するために、私たちは量子もつれの統計分布を再現するようにQPD(quasi-probability decomposition、疑似確率分解)をローカル演算で利用し、テレポーテーション回路が利用する、切断 Bellペア(cut Bell pair)を得ます。
2個の QPU間で目的の量子状態を作成するには、一つのテレポーテーション回路内で複数の、切断 Bellペアを利用する必要があります。このテレポーテーション回路は、2個の接続された QPU上の量子回路を密に同期させることによって実行することができました。切断 Bellペアは、下図の緑の箱に表現されている「切断Bellペア・ファクトリー」で生成されます。
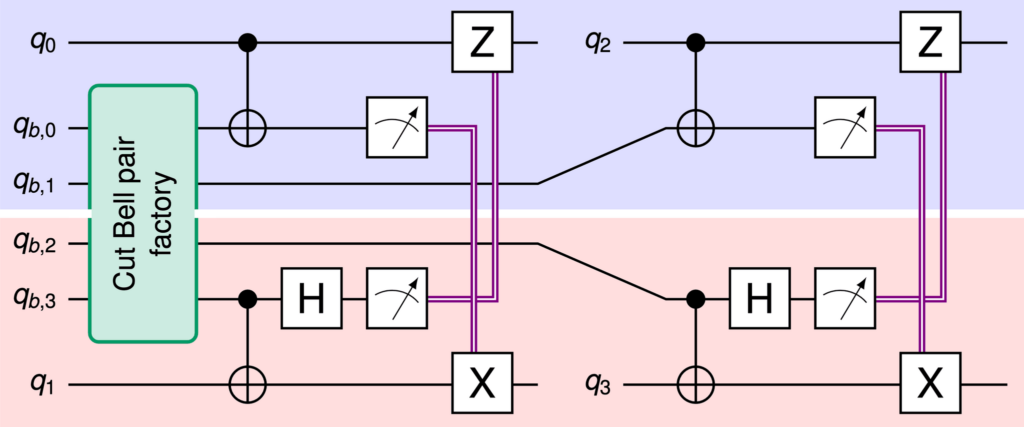
Nature論文の図 1b
Nature論文の図 1c
これらの 2つの図は、別々の QPU上にある量子ビットをもつれさせることができる テレポーテーション・プロトコルを示しています。 それぞれの図で、上部の青色の領域は、1個の QPUで実行される切断 Bellペア・ファクトリー部分を表し、下部の赤い領域は、他の QPUで実行される部分を表します。 これら二つを合わせて、青い領域と赤い領域は、このプロトコルを使用して 図1b上部にある量子ビット 0(q0)と下部にある量子ビット 1(q1)を接続する CNOTゲートを作成する方法を表しています。さらに、量子ビット 2(q2)と量子ビット 3(q3)を接続する 2量子ビット・ゲートについても同様です。
図 1b の q0 と q1 の例を見てみましょう。まず、それぞれの QPU上で、それぞれ量子ビット間のローカル CNOTゲートを作ることから始めます。この場合、q0と qb,0を、また q1と qb,3を接続します。CNOTゲートは常に制御量子ビットと目標量子ビットから構成されますので、 このローカル Bellペアで q1を制御量子ビットとして使うならば、q0は そのローカル Bellペアで目標量子ビットとして使うことになります。
次に、ダイナミック・サーキットを使って、2つの第二量子ビット、すなわち qb,0 と qb,3 について中間回路測定を行います。ダイナミック・サーキットは、1回路の実行時間内に量子ビットを測定し、その結果に応じて量子ビットに論理演算を実行できるパワフルな道具です。
ダイナミック・サーキットを使う際の一つの課題は、古典コンピューターが中間回路測定を行ってその結果に応じた適切な演算を行っている間、システム内の他の量子ビットをアイドル状態にしなければならないことです。アイドル状態の量子ビットは、この遅延時間中に、量子ビット間のクロストークや、量子状態の T1および T2減衰などといった理由によって、エラーを蓄積してしまう傾向があります。この問題は、私たちの実験にとって大きな難題でした。この難題を解決するために、私たちは、zero-noise extrapolation(ZNE)といった確立したエラー対処手法や、ダイナミック・デカップリングと呼ばれる一般的なエラー抑制手法から着想を得た、新しいエラー緩和戦略を開発しました。ZNEは、ノイズを増幅することで、ノイズがゼロの際の出力を外挿する手法です。私たちの新手法では、遅延時間にダイナミック・デカップリングを挿入して、エラーの一部を抑制し、そして遅延時間を何倍かに引き伸ばすことで、遅延時間がゼロの時の状態を外挿で推定します。
この手法は、実装が驚くほど簡単であるとわかりました。しかも、中間回路測定によって起こる遅延時間は短縮される見込みで、将来的に実現される機能でこの手法の効率はさらに改善する可能性があります。私たちは、この研究で検討した以外のさまざまなダイナミック・サーキットの応用においても、この新しいエラー緩和手法が役立つものと考えています。
このような中間回路測定を行う前に、ローカル Bellペア内で目標量子ビットとして機能する第二の量子ビットに対して、アダマール・ゲートを適用します。 その後、2個の第二量子ビットに対して中間回路測定を行い、古典的な出力を取得し、その出力を上図で紫の二重線で描かれたような古典通信リンクによって、他方の QPU上にある第一の量子ビットに伝送します。
これが 一回の回路実行です。そして、このプロセスを複数回繰り返し、異なるパラメーターで回路を実行して、真のBellペアの量子もつれ統計を最終的に再現します。 量子研究者は、このアプローチが理論的に機能するはずであると長い間予想してきましたが、この新しい論文は、これらのパラメーターを同定し、実際の量子ハードウェア上で適切な回路を実行するために必要な擬似確率分解を明示した、最初の実例の一つです。
複数のQPUを接続する必要は本当にあるのか?
LOCCを介して 2個の QPUを接続し、それらを 1個の QPUとして操作できたことは、重要な成果です。これは私たちの知る限り、長年にわたって量子研究コミュニティーで議論されてきた基本的な概念を実験的に実現した最初の研究です。しかし、このことはこの研究の成果のうちの 一部にしかすぎません。
上述の通り、私たちは LOのみで構成されるサーキット・カッティング手法も研究しました。 LO方式でも、大きな量子回路を取り扱い、1個の QPUで実行可能な小さな部分回路に分解することは同様です。しかし、2個の接続された QPUを厳密に同期させてこれらの部分回路を実行する代わりに、好きなタイミングや場所で回路を実行することができます。つまり、接続リンクのない別々の QPUで実行することも、1個の QPUの上で回路を一つずつ順番に実行することもできます。
これら両方の手法には、利点と欠点があります。 LOCC方式の実装では、LO方式と比較して、必要なサンプル(つまり回路の実行回数)がはるかに少ないため計算コストが大幅に削減されます。また LOCC方式は、LO方式とは異なり、コンパイルするテンプレート回路が一つだけでよいため、回路のコンパイルの点で実行パイプラインのコストも削減されます。これらの計算コストの削減により、LOCC方式は一般に LO方式よりはるかに高速になります。
一方で LO方式は、LOCC方式よりも高品質な結果を得られる傾向があります。 これは、必要な回路がはるかに単純で、追加のエラー誤差の原因となるダイナミック・サーキットが必要ないためです。そして当然のことながら、古典的な通信も必要ありません。
どちらか一方のアプローチが最終的に他方より優れていると証明されるかどうかはまだ明らかではありません。将来的に量子ハードウェアおよびソフトウェア・スタックのパフォーマンス向上によって、LOCC方式の計算コスト削減が不要になる可能性があります。その一方で、この新しい研究で得られた、ダイナミック・サーキットと量子回路のコンパイルに関する重要な知見によって、LOCC方式の品質が大幅に向上されるかもしれません。また、研究者たちは将来的には、異なる QPU間で量子もつれ状態を非常に容易に共有することができるような、実効的な量子通信リンクが利用可能になることを望んでいます。この方向性については、IBMが 2024年11月の IBM Quantum Developer Conferenceで初めて発表した IBM Quantum Flamingo の l-カプラで既に取り組みが進められています。
QCSCと量子優位性に向けた重要な進歩
LO方式と LOCC方式のどちらがより優れたサーキット・カッティングであるかはまだわかりませんが、いずれの方式についても、画期的な量子計算アプリケーションを実現するのに今日にでも役立つ可能性があることは明白です。
私たちの研究は、将来の量子中心のスーパーコンピューティング・アーキテクチャーへ向かって小さな前進をするだけではありません。現時点での量子技術で探索可能なアプリケーションの規模と応用範囲の拡大という役割も果たしています。この研究で実証された新しい機能は、まさにそのような性質のものです。
私たちの研究では、LO方式 と LOCC方式の両方を使用して、127量子ビットしか持たない Eagleプロセッサー上に、142量子ビットに周期境界条件を持つ 134ノードの量子グラフ状態を構築しました。Eagleプロセッサー上の平面的な 2次元ヘビー・ヘックス構造に対して サーキット・カッティングを使って、3次元円柱構造を形成することができたということです。これはサーキット・カッティングがなくては不可能なことです。
以下の図に示すように、このシステムでは各点が量子ビットを表し、線分が隣接する量子ビット間の相互作用を表しています。 下の紫色の線は、サーキット・カッティングが 2次元のシステムを使用してこの 3次元形状をシミュレートできるようにする周期境界条件を表しています。
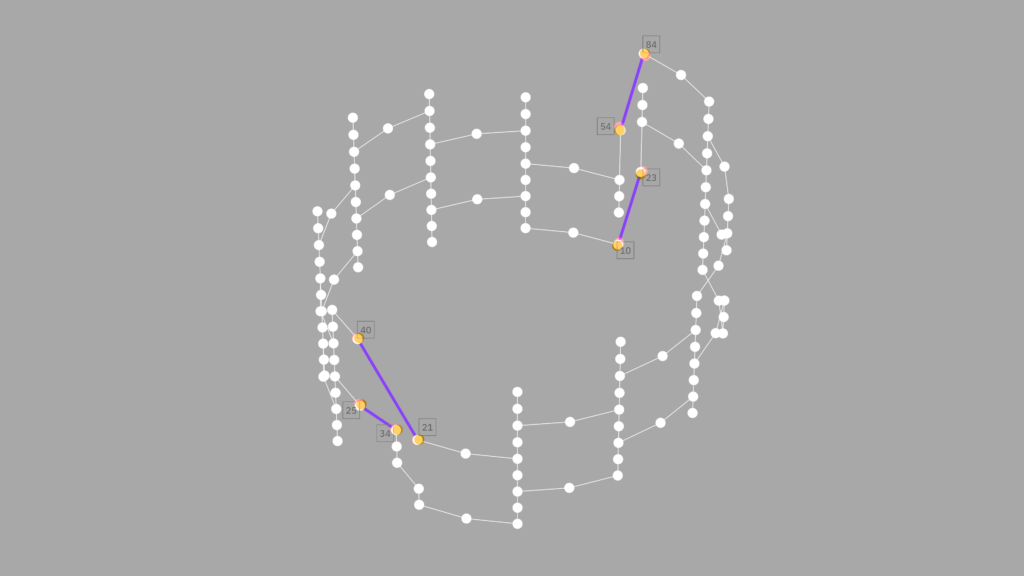
周期境界条件を持ったグラフ状態
この図のような周期境界条件は、自然現象のシミュレーションで頻繁に見られます。研究者たちは、このような境界条件を使用して、大規模、あるいは実質的に無限の量子系の条件を近似し、量子情報が無限にループで伝搬できる格子を作成します。これは原子系の励起が、無限の真空空間を伝搬し続けるのと同じ様子です。私たちの研究は、このパラダイムでシミュレートできる自然系の規模を大幅に拡大していきますが、さらにこれらの機能は量子エラー訂正など、自然系のシミュレーション以外のアプリケーションにも応用できる可能性があります。
これは、量子ハードウェア上で量子状態を構築する能力の画期的な前進であり、今日の 100量子ビット以上を扱う QPUが、個々のプロセッサーの量子ビット数という制限を超えるシミュレーションを構築できることも示しています。量子コミュニティーの他の量子研究者たちにも、この論文で私たちが示した機能を使って、これまで量子計算では手が届かなかった系を調査して頂けることを期待しています。
私たちの研究について詳しくは、 Natureの論文をお読みください。
この記事は英語版IBM Researchブログ「Dynamic circuits enable essential circuit cutting methods for quantum-centric supercomputing」(2024年12月11日公開)を翻訳し一部更新したものです。



Qiskit SDK v1.3がリリースされました!
主な新機能や改善点、非推奨となった機能を含めて Qiskit SDK v1.3のリリースの技術的要点をご紹介します。 2024年12月4日に Qiskit SDK v1.3のリリースを発表しました! この最新リリースは、 […]

フォト・レポート:SEMICON Japan 2023 IBMブース
SEMICON Japan 2023に、IBMが出展しました。 本記事は、フォト・レポートとして、IBMブースで撮影した写真を掲載します。 IBMブースの外観 NorthPole(超省電力のエッジ向けデジタルAIチップ) […]