量子コンピューティング
IBMのランドマーク的エラー訂正論文がNature誌の表紙に掲載
2024-04-11
カテゴリー IBM Research (コンピューティング) | 量子コンピューティング
記事をシェアする:
IBMは、以前の方法より10倍効率の良い量子エラー訂正符号を開発しました。これは量子コンピューティングの研究におけるマイルストーンです。
先日、その成果の詳細を発表する論文が、ネイチャー誌のカバー・ストーリーとして掲載されました。
昨年、私たちは、量子コンピューターが古典コンピューターよりも量子回路をうまく実行できるという、量子コンピューターのユーティリティー時代に入ったということを実証しました(IBMとカリフォルニア大学バークレー校が、実用的な量子コンピューティングへの道筋を発表した論文はこちら)。今後数年間で、古典コンピューターを凌ぐスピードアップが見られ、これらのシステムからビジネス価値が得られることが期待されます。しかし、最高の古典的手法に対してスピードアップを得られることが数学的に証明されている一方で、数億から数十億ゲートを持つ量子回路のチューニングが必要なアルゴリズムもあります。そのようなアルゴリズムを量子コンピューターのツールキットに含めるには、量子システムが本質的に持つエラーを訂正する方法が必要です。それが量子エラー訂正です。
量子エラー訂正を使うには、量子エラー訂正を使わない場合に比べてより多くの量子ビットで量子情報をエンコードする必要があります。量子エラー訂正をスケーラブルで誤り耐性のある形で実現するには、これまで百万物理量子ビット以上のスケールでの検討が必要でした。最近、私たちが発表した結果は、そのオーバーヘッドを大幅に削減し、量子エラー訂正が手の届くところにあることを示しました。
量子エラー訂正理論の始まりは30年前に遡りますが、これまでの理論的なエラー訂正手法には、意味ある量子回路を実ハードウェア上で実行可能にしようとすると、必要となるシステムの規模などが非現実的に大きくなってしまう問題がありました。私たちの新しい論文はグロス符号と名付けた新しいコードを導入し、この問題を克服しました。
エラー訂正は未だ解決されていない問題ですが、この新しいコードは、超伝導トランズモン量子ビットのハードウェア上で、十億ゲート以上の量子回路を実行する道筋を明確に示しています。
エラー訂正とは?
量子情報は壊れやすく、ノイズの影響を受けやすいものです。環境ノイズ、制御電子機器のノイズ、ハードウェアの欠陥、状態の準備と測定に伴うエラーなどにより変化してしまいます。数百万から十億以上のゲートを持つ量子回路を実行するには、量子エラー訂正が必須です。
エラー訂正は、量子回路に冗長性を持たせることで機能します。すなわち、一つの量子ビットだけだったらエラーやノイズによって失われてしまうかもしれないある量の量子情報を、多数の量子ビットを協力させて守ります。
古典コンピューターでは、冗長性の考え方はいたって単純です。古典的なエラー訂正ではたとえば、同じ情報を複数のビットに記録します。たとえば、1を1、0を0と記録する代わりに、コンピューターは11111や00000として記録します。こうすれば、いくつか少数のビットがエラーによって変化しても、たとえば11001を1、10001を0としてコンピューターは判断することができます。エラー訂正をもっと良くするために、より多くの冗長性を導入するのは簡単です。
量子コンピューターでは問題が複雑になります。量子情報は古典的な情報のように複製することができないので、量子ビットに格納される情報は、古典的なデータよりも扱いが複雑になります。そしてもちろん、量子ビットはすぐにデコーヒレンスを起こし、保存した情報を失ってしまいます。
量子誤り耐性が実現可能であることは研究で示されており、多くのエラー訂正手法が教科書には解説されています。最も一般的なものは、「表面符号(surface code)」と呼ばれるもので、二次元格子上に量子ビットを配置し、その格子の部分部分に情報の一部をエンコードします。
しかし、この種の手法には問題があります。
第一に、これらの手法は、ハードウェアの誤り率が、方法とノイズ自体の特性に依存して決まる閾値よりも小さい時だけうまく機能するのですが、その閾値を下回ること自体が簡単ではありません。
第二に、これらの方法は効率的にスケールしません。より大きな量子コンピューターを作ろうとすると、エラー訂正に必要な追加量子ビットの数は、コードで保存したい量子ビットの数をはるかに上回って増加してしまいます。
多数のエラーが訂正できるような実用的なコードサイズでは、表面符号は、量子情報に相当する1量子ビットあたりで、数百やそれ以上の数の物理量子ビットを必要とします。そのため、表面符号はエラー訂正についての比較研究には有用ですが、誤り耐性のある量子コンピューターを実現する物語の結末にはなりそうもないのです。
「良い」コードの探求
2022年にモスクワ州立大学の Pavel PanteleevとGlev Kalachevが漸近的に良いコード(asymptotically good codes)が存在することを証明したランドマーク的論文を発表すると、エラー訂正の研究分野は興奮に沸き立ちました。漸近的に良いコードとは、コードの品質が向上するに従い、必要な追加量子ビットの数の増加が横ばいになるコードです。
この研究はエラー訂正の多くの研究に拍車をかけましたが、特に、表面符号が生まれたのと同じ、量子低密度パリティ検査符号(qLDPC符号)と呼ばれる種類のコードの研究が盛んになりました。これらのqLDPC符号は、エラーが起きたか起きていないかをチェックするための演算は少数の量子ビットだけに影響を及ぼし、しかもそれぞれの量子ビットが関わるのは少数回数のチェックのみでよいという量子エラー訂正符号です。
しかしこの研究は、そのような種類のエラー訂正の可能性を証明することに集中した、極めて理論的な研究でした。そのため量子コンピューターを構築する際の現実的な制約を考慮に入れていませんでした。また最も重要なことは、一部のqLDPC符号は、システム内の多くの量子ビットが、非常に多くの他の量子ビットと物理的に接続されていることを必要としました。このことは、実際には、量子プロセッサーがサイケデリックで超次元的な折り紙のように折り畳まれたり、あるいはぐちゃぐちゃのネズミの巣のように極端に複雑なワイヤー結線されていたりすることを要求します。

Bravyi, S., Cross, A., Gambetta, J., et al. High-threshold and low-overhead fault-tolerant quantum memory. Nature (2024). https://doi.org/10.1038/s41586-024-07107-7
私たちのNature論文では、量子ビットのオーバーヘッドが少なく、エラー耐性が高く、大きな符号距離を持つ誤り耐性のある量子メモリーを特に探求しました。
この要求を解剖してみましょう:
- 【誤り耐性】エラーを検出するための回路は、処理中にあまりひどくエラーを拡散せず、エラーが生じるよりも速く訂正を行うことができます。
- 【量子メモリー】この論文では、量子情報を符号化し、保存しているだけです。符号化された量子情報に基づく計算はまだ行っていません。
- 【大きなエラー閾値】閾値が高ければ高いほど、多くのハードウェアエラーを許容して、誤り耐性を実現することができます。私たちは閾値を1%に近づけるべく、物理的なエラー率0.001でも信頼性を持ってメモリーを動作させられるようなコードを求めていました。
- 【大きな符号距離】距離とは、コードの堅牢性、すなわち、どのくらいの数のエラーで値が0から1へ、あるいは1から0へと完全に反転するかの尺度です。例えば、00000と11111の場合、距離は5です。私たちは、3個以上のエラーを修正することができる符号距離の大きいコードを追求しました。大きな距離を持ったコードは、ハードウェアの品質がコードの閾値を少ししか上回っていない時にも、桁のオーダーでノイズを削減することができます。対照的に、小さな距離のコードは、ハードウェアの品質がコードの閾値を大きく上回っていなければ、有用ではありません。
- 【少ない量子ビット・オーバーヘッド】オーバーヘッドとは、エラーを訂正するのに必要な追加量子ビットの数です。私たちはエラー訂正に必要となる量子ビットの数を、同じ品質や同じ符号距離を持つ表面符号よりもはるかに少なくしたいと考えています。
私たちのチームが数学的分析を行った結果、大変素晴らしいことに、全ての必要な条件を満たす具体的なqLDPC符号の例をいくつか見つけることができました。これらは、「Bivariate Bicycle(BB)」符号と呼ばれるカテゴリーのコードに属します。これらは、今後私たちの研究の方向だけでなく、私たちの物理的な量子システムの設計にも影響を与えるものと思われます。
グロス符号
多くのqLDPC符号は、エラー訂正理論を進める上で大きな可能性を示していますが、それらは必ずしも実世界応用の上で実用的とは限りません。それに対し、私たちの新しいコードは、各量子ビットが他の量子ビット6つに接続するだけで済み、それらの接続は2層で配線できるという点で、実用的な実装に適しています。
量子ビットがどのように接続されているかの感覚をつかむには、それらがマス目を持った方眼紙に乗っているところをイメージしてください。その方眼紙を丸めて筒にして、端と端をつないでドーナツを作ります。このドーナツ上でそれぞれの量子ビットは、隣接する4量子ビットおよび一個先の2量子ビットと、ドーナツの表面上で接続されています。それ以外の接続は必要ありません。
幸いなことに、このコードを使うのに量子ビットを実際にドーナツの上に埋め込む必要はありません。表面を折り曲げ、数本の長距離接続を追加すれば、このコードの数学的要求を満たすことはできます。これは工学的チャレンジではありますが、 超次元的な形状よりもずっと実現可能性が高いものです。
私たちは、この構造を持ついくつかのコードを調査し、特に [[144,12,12]]コードに焦点をあて、このコードをグロス符号と名づけました。それは、144が1グロス(=12ダース=12*12個)だからです。このコードはデータを保存するのに144量子ビットを必要とします。ただし私たち固有の実装では、エラー検出にさらに加えて144量子ビットを使用しますので、この特定のコードでは288量子ビットを使用します。これにより12論理量子ビットを保存し、12個までのエラーを検出することができます。このため[[144,12,12]]と表記します。
グロス符号を使えば、288量子ビットを使っておよそ100万サイクルのエラーチェックの間、12個の論理量子ビットを保護することができます。およそ同じことを表面符号でやろうとすると、約3,000量子ビットが必要になります。
これは大きなマイルストーンです。私たちはまだ、もっと効率の良いアーキテクチャーを持つqLDPC符号を探しており、これらの符号を用いてエラー訂正計算を行う研究は進行中です。しかし、この論文の発表により、将来のエラー訂正は明るいものとなりました。

図1 | 表面符号とBB符号のタナーグラフ。(a) 表面符号のタナーグラフ(比較のため)。(b) トーラスに埋め込まれた、パラメーター[[144,12,12]]を持つBB符号のタナーグラフ。タナーグラフのエッジはいずれもデータ量子ビットとチェック量子ビットを接続しています。レジスタq(L)とq(R)に関連づけられたデータ量子ビットは青とオレンジの丸の頂点で、チェック量子ビットはピンクと緑の四角の頂点で表示されています。各頂点は、4つの近接エッジ(北、南、東、西)と2つの長距離エッジを含む6つのインシデント・エッジを持っています。見やすくするために、この図に長距離エッジは少数だけ表示しています。破線と実線は、タナーグラフにわたる2つの平面サブグラフを表しています。(c) Z と X を計測するため、表面符号に追加されたタナーグラフ拡張のスケッチ。 X 計測に対応するアンシラは、表面符号に接続されて、量子テレポーテーションといくつかの論理的なユニタリ操作によって全ての論理量子ビットについてロード/ストア操作を可能にすることができます。この拡張タナーグラフにはAエッジとBエッジを経由する厚さ2のアーキテクチャーでの実装があります。
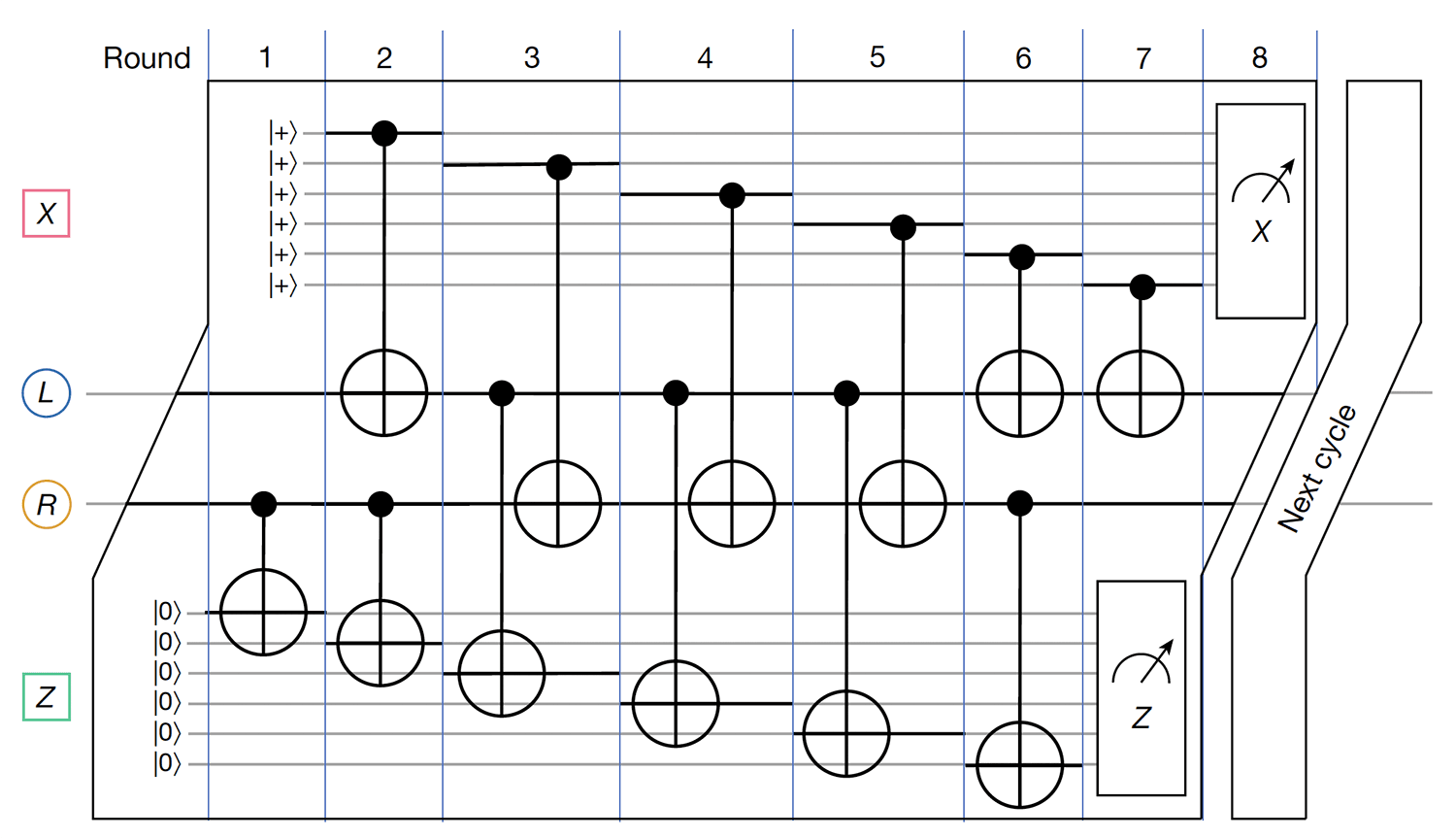
図2|シンドローム測定回路。7層のCNOTゲートを用いたシンドローム測定のフルサイクル。q(L)とq(R)の各レジスタから1データ量子ビットのみを含む回路一部の様子を示しています。回路はタナーグラフの垂直シフトと水平シフトに関して対称です。各データ量子ビットは、CNOTゲートを介して3つのXチェック量子ビットおよび3つのZチェック量子ビットと連携されています。
なぜエラー訂正が重要か
このコードは、実用的な量子コンピューティングを世界に届けるための私たちの全体的な戦略の一部です。
オブザーバブルを計算する際にノイズの影響を減らす、あるいは排除する方法である新しいエラー緩和技術は、ハードウェアレベルでのエラー抑制技術とともに、私たちのユーザーにすでに提供されています。この技術が量子ユーティリティーの時代をもたらしました。世界中のIBMの研究者とパートナーは、既存の量子システムと今日の量子コンピューティングを活用して実用的なアプリケーションを探求しています。エラー緩和は、ユーザーが量子ハードウェア実機上で量子優位性を追求し始めるのを可能にしています。
しかし、エラー緩和にはオーバーヘッドが伴います。すなわち、古典コンピューターで統計的方法を用いて正確な結果を計算するために、同じプログラムを何度も繰り返し実行する必要があります。これは実行できるプログラムの規模を制限するので、その規模を拡大するためには、エラー緩和を超えた道具、たとえばエラー訂正が必要になります。
昨年、私たちは、今後10年間で量子コンピューターを改善し続ける新しいロードマップを発表しました。今回の新しい論文は、私たちがハードウェア上で実行できる量子回路の複雑さ(ゲート数)を継続的に増加させる計画の重要な一例です。この論文により私たちは実行する回路の規模を15,000ゲートから、1億ゲートあるいは10億ゲートといった次の段階の規模へと移行できるようになるでしょう。
参考文献
- Bravyi, S., Cross, A.W., Gambetta, J.M. et al. High-threshold and low-overhead fault-tolerant quantum memory. Nature 627, 778–782 (2024). https://doi.org/10.1038/s41586-024-07107-7
この記事は英語版IBM Researchブログ「Landmark IBM error correction paper published on the cover of Nature」(2024年3月27日公開)を翻訳し一部更新したものです。

IBM Quantum Learningのコース刷新および新登場したラーニング・パスウェイ
IBM®は、IBM QuantumTM Learningで新しい教材をリリースします。量子学習コンテンツの選択に役立つ「ラーニング・パスウェイ」も利用可能になります。 量子計算の学習を始めるのに時期を待つ必 […]
Qiskit Code Assistantのプレビュー公開
IBM QuantumTM プレミアム・ユーザーの皆様向けに、量子コードのコーディングを助けるアシスタントがプレビューとして利用可能になりました。 有用な量子計算を世界にもたらすためにIBMは、世界で最も高 […]

ヨーロッパ初のIBM Quantumデータセンターがオープン
2024年10月1日、ドイツ連邦首相 Olaf Scholz氏とヨーロッパ地域のパートナーの代表者に出席して頂いて、IBMはヨーロッパ初の量子データセンター(Quantum Data Center)のテープカットを行いま […]