2020年07月14日
カテゴリー IBM Data and AI
記事をシェアする:
IBM Integrated Analytics System(以下 IIAS)はDb2 Warehouseをコアエンジンとし、超並列処理アーキテクチャー(MPP)とDb2 BLUインメモリアクセラレーションを備えた高速性と簡易性を備えたDWHアプライアンスです。IIASは、高性能ハードウェア・プラットフォーム上に分析用途のワークロードに最適化されたデータベースエンジンで構成されており、様々なデータ分析処理、BIレポーティング、機械学習機能をサポートします。コアエンジンである、Db2 Warehouseは、アプライアンス、コンテナ、マネージドクラウドサービスの形態を備え、オンプレミスから各種クラウド環境と場所に依存せずハイブリッドに利用でき、Oracle DB、Netezzaからの互換性機能、移行ツールを備えています。今回、株式会社ZOZOテクノロジーズ様は、IBM PureData System for Analyticsから、IIASに移行されました。
下記記事は、株式会社ZOZOテクノロジーズ TECH BLOGに掲載された記事(外部ページ)を転載したものです。
こんにちは! ZOZOテクノロジーズの中坊(e_tyubo (外部ページ))です。
概要
私が所属しているマーケティングオートメーション(以下MA)を担当するチームでは、ユーザ毎にパーソナライズされた情報をメールやアプリのPush通知で配信しています。その際に利用するZOZOTOWNやWEARのデータは我々が管理する専用のデータベースに集約されています。このデータベースには日々のユーザの行動ログが記録されるため、必然的にデータ量は大きいものになります。このような巨大なデータを管理することに特化したデータベースはデータウェアハウス(以下DWH)と呼ばれていて、実績の可視化やマーケティングに活用するための分析等の用途に使われます。
MAチームでは配信内容をユーザ単位で最適化するためにDWHを利用していて、最近まではIBM PureData System for Analytics(以下PureData)を利用していました。しかし、PureDataの保守が終了してしまうため別のデータベースに移行する必要がありました。我々は互換性を考慮し、後継機であるIBM Integrated Analytics System(以下IIAS)へ移行することにしました。
PureDataとIIASはどちらもIBM製品であるため高い互換性がありますが、一部の機能については挙動の違いもあり個別に対応が必要となりました。本記事では新しく導入したIIASの特徴と、移行の際にぶつかった問題とその解決方法について紹介します。
IIASの特徴
最初に、IIASがどのようなデータベースなのかを紹介します。
IIASはデータベースそのものを指すのではなく、サーバ筐体や周辺ツールを含めたパッケージ製品の名称です。公式ドキュメントに書かれている通り、Db2 Warehouseという製品を中核とし、様々な周辺ツールが提供されています。IIASはクラウドサービスではなく、計算機本体を購入し管理する必要がある、いわゆるオンプレミスなデータベースです。よく利用されるBigQueryの様なフルマネージドなDWHとは異なり、サーバ本体を自社で保有する必要があります。
Db2 Warehouse
以前まで利用していたPureDataはPostgreSQLベースでしたが、IIASは先程も述べた通り、Db2 Warehouseという製品を利用しています。Db2はIBMが開発したデータベースで、1983年にリリースされた歴史の長いRDBMSです。元々はWebアプリケーション等の裏側でリアルタイムな処理を主として利用されていたデータベースですが、改良が重ねられ、DWHとしての機能も果たすようになっていきました。
Db2 Warehouseもまた、データベースだけを指す言葉ではなく、データベースエンジンと周辺機能をDocker上で動作させるために必要な機能を提供する製品の名称です。公式ドキュメントの図にも書かれている通り、GUIでデータベースの操作ができるWebコンソールやログインユーザの管理用のLDAPが標準で搭載されており、セットアップ後は様々な機能が利用可能になります。特徴的な点としてDb2 Warehouseの機能はDocker Imageで提供されている点が挙げられます。無料版も存在していて、Docker Hub1か、IBM Cloud Container Registryから入手が可能です。開発用の環境を自前で構築する際には利用が可能ですので、導入前の検討材料や本番で実施しにくいテストの実行環境として活用ができます。
複数のノードで分散処理
IIASには物理サーバが複数台含まれており、それぞれのサーバを使って1つのデータベースを動かします。RDBMSではしばしばシャーディングと呼ばれる方法でデータを分割をして負荷分散させることがありますが、Db2 Warehouseは標準でそのような仕組みを備えています。
また、Db2 Warehouseでは物理的なサーバ単位だけでなく、サーバの中に論理ノードという単位でデータを分けて保持できます。これはあるサーバの中でさらに論理的にデータを分割し、保持する仕組みです。Db2 Warehouseではノード毎に保持しているデータを、ノード毎に処理することで効率的にSQLを実行する仕組みを備えています。この場合CPU、メモリ、ストレージは同一サーバ上のものを共有することになります。しかし、利用可能なCPUのコア数が論理ノード数に対して十分な数がある場合はノード単位で同時に処理をすることで処理効率の改善が期待できます。
下記のようなSELECTステートメントを例に考えてみましょう。
SELECT * FROM SampleTable
SampleTableというテーブルから全てのカラムをSELECTする単純なクエリです。1つのテーブルですが、Db2 Warehouseの仕組み上データは複数サーバに分散されているため、取得経路は下図のようになります。
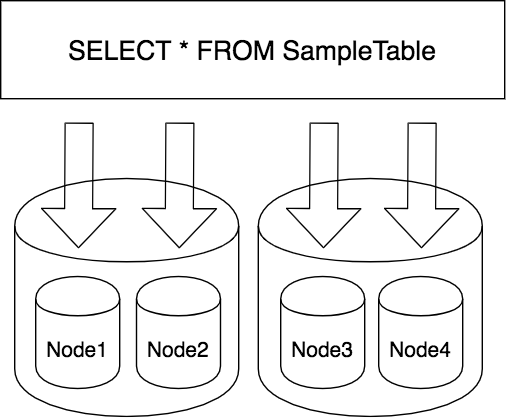
この図は物理サーバが2台あり、その中でさらに論理ノードに分かれているケースを表しています。図のように全ての論理ノードからデータを集めて、全て取得し終わったら要求した全てのデータを返します。このようにDb2 Warehouseはそれぞれのノードで処理を並列実行することでクエリのパフォーマンスを効率化しています。
分散キー
先ほどデータが各ノードに分散配置されると書きましたが、分散させるには分ける基準となる情報が必要です。そのため、Db2 Warehouseには分散キーという属性をカラムに指定できます。
分散の方式にはハッシュ分散とランダム分散の2種類があり、分散キーの作成時にどちらを利用するか指定できます。ランダム分散は適切なキーが存在しない場合にDb2 Warehouseが自動で分散キーを決定する方式ですが、利用するケースがなかったため説明は割愛します。
ハッシュ分散は、カラムの値を用いて分散させる方式です。例えば会員情報を管理するためのMemberというテーブルがあった場合、分散キーは下記のように指定できます。memberIdはユニークな値のみ保持することとします。
CREATE TABLE Member (
memberId INTEGER,
name VARCHAR(50)
)
DISTRIBUTE BY HASH(memberId)
ORGANIZE BY COLUMN
ハッシュ分散は、指定したキーの値と格納先ノードを対応させるマップを作成し、それに沿ってデータを配置します。下記の画像はノードが4つ存在する場合に作成されるマップのイメージ図です。

値の重複がある場合、データは同じノードに格納されるため、均一化のためにはカーディナリティ(値のばらつき具合)が高い列を選択する必要があります。今回のケースではmemberIdがユニークであるため、均一にデータが配置されます。
次に分散キーの効果的な利用方法について説明します。並列処理を効率的に実行するためには各ノードで検索条件にマッチするデータ量を均一化することが必要です。もし特定ノードにデータが偏っていた場合、そのノードで実行されるデータ取得処理が終わるまで全体の処理を終えることができません。
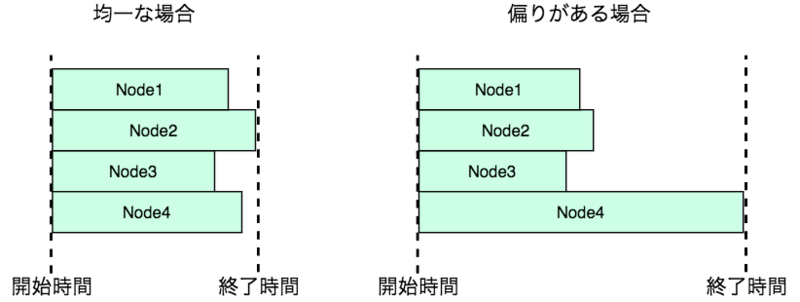
JOINを例に考えてみます。例えば、下記のような会員のお気に入り商品の情報を管理するFavoriteProductテーブルがあるとします。
CREATE TABLE FavoriteProduct (
memberId INTEGER,
productId INTEGER
)
DISTRIBUTE BY HASH(memberId, productId)
ORGANIZE BY COLUMN
下記のクエリでお気に入り情報に紐づく会員情報を取得するケースを考えましょう。
SELECT
productId
,name
FROM
FavoriteProduct
INNER JOIN Member ON Member.memberId = FavoriteProduct.memberId
この場合FavoriteProductが保持しているmemberIdを使ってMemberテーブルを検索するため、分散キーを利用することになります。MemberテーブルのmemberIdはユニークなキーであり、均一に分散されているため十分効率的にSELECTを実行できると考えられます。
このように、検索条件に対していかにデータを均等に分散させるかがパフォーマンスを考慮する上で重要になります。
つまり分散キーを選択する際には、下記の条件を満たしているケースが望ましいです。
必ずしもこの条件を満たす必要は無いですが、分散キーを選択する際の基準として考慮しています。
列指向と行指向
Db2の特徴として列指向と行指向を両方サポートしているという点が挙げられます。行指向はレコード単位でデータを保持し、列指向はカラム毎にデータを保持する方式の事を言います。
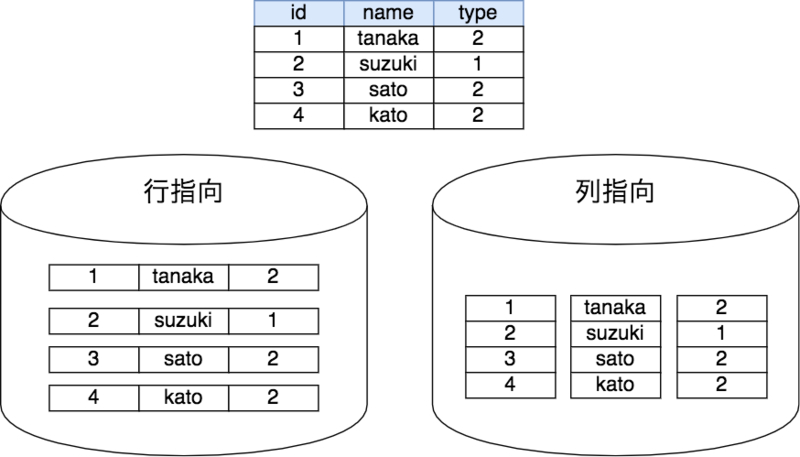
MySQLやPostgreSQL、SQL Server等のRDBMSはテーブルの中から特定のレコードを取得する事に重きを置いているため、行毎にデータを保持しておくことが効果的です。しかし、Db2 WarehouseのようなDWHは大量のデータを保持する事を想定しており、列単位にデータを保持することで大量データの中から特定の列のみを使った処理を効率的に実行できます。
Db2 Warehouseは列単位でデータを保持することにより、特に下記の利点があるようです。
IIASで利用する際にはデフォルトで列指向なテーブルが作成されますが、明示的に行指向テーブルを作成することも可能です。
CREATE TABLE Member (
memberId INTEGER,
name VARCHAR(50)
)
DISTRIBUTE BY HASH(memberId)
ORGANIZE BY ROW
上記のようにORGANIZE BY ROWを指定すると行指向テーブルが作成されます。DWHの用途を考えると列指向なテーブルを使うことの方が多いと思いますが、必要に応じて使い分けることができます。
データスキッピング
一般的なRDBMSでは検索を効率的に実施するためにindexを利用しますが、列指向で保持しているデータについては同じ方式では有効に検索できません。そこでindexではなくデータスキッピングという仕組みを用いてカラムの中のデータ検索を効率化しています。
データスキッピングとは、一定のデータ件数毎に各列が持つデータの最大値と最小値をメタデータとして保持し、レコードが存在する範囲を絞り込みやすくする機能です。
例えばMemberテーブルに登録時刻を保持するregistDtというカラムがある場合を考えます。
CREATE TABLE Member (
memberId INTEGER,
name VARCHAR(50),
registDt DATETIME
)
DISTRIBUTE BY HASH(memberId)
ORGANIZE BY COLUMN
下記のWHERE句を用いて2020年4月に登録した会員をSELECTします。
WHERE registDt >= '2020-04-01 00:00:00' AND registDt < '2020-05-01 00:00:00'
この時データスキッピングの機能により、対象レコードを効果的に絞り込むことが可能です。
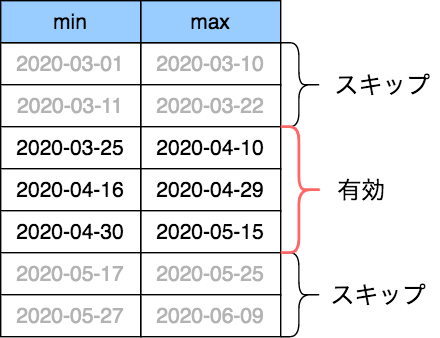
上図のように、メタデータを使って2020年4月1日より古いデータと2020年5月1日より新しいデータが存在する範囲を不要だと判断できるため、処理が効率化されます。
Webコンソール
IIASをセットアップすると、Db2 Warehouse専用のWebコンソールが利用可能になります。様々な機能が利用可能ですが、特に頻繁に利用する機能は下記の通りです。
Mac用に標準ツールが提供されていないこともあり、Webコンソールからクエリを実行することが多いです。
FPureDataからIIASに移行する際の注意点
次はPureDataからIIASへ移行する際に課題となったポイントをまとめます。
冒頭でも述べた通り、PureDataとDb2 Warehouseは高い互換性がありますが、一部挙動に相違が見られます。ここでは移行に当たって書き換えや、対応が必要となった機能の一部を紹介します。
FROM句は必須
PureDataで現在時刻を取得する時は、FROM句を指定せず下記のクエリで実現可能です。
しかし、Db2 Warehouseでは明示的に指定が必須です。
SELECT CURRENT_DATE FROM SYSIBM.SYSDUMMY1
そのため単純に値の中身を確認するような場合には、上記のように、SYSIBMスキーマに用意されたダミーテーブルを利用します。
もしくは、VALUESを使うことでも同様の結果が得られます。
VALUES(CURRENT_DATE)
LENGTHとCHARACTER_LENGTH
PureDataでは文字列に対してLENGTH関数を使うと文字数が返ってきましたが、Db2 Warehouseでは挙動が異なります。Db2 Warehouse内で扱う文字列の文字コードがUTF-8となっている前提で考えます。
SELECT LENGTH('Hello') FROM SYSIBM.SYSDUMMY1
SELECT LENGTH('こんにちは') FROM SYSIBM.SYSDUMMY1
どちらも文字数で見ると5ですが、結果は下記の通りです。
これはDb2 WarehouseがLENGTHによって文字数ではなく、文字列の合計バイト数を返していることが原因です。UTF-8の文字列ではアルファベットは1バイト、ひらがなは3バイトで表現されます。
単純な文字数をカウントしたい時は、CHARACTER_LENGTHを使って書くことで期待した結果を得ることができます。
SELECT CHARACTER_LENGTH('Hello') FROM SYSIBM.SYSDUMMY1
SELECT CHARACTER_LENGTH('こんにちは') FROM SYSIBM.SYSDUMMY1
ウィンドウ関数の中でrandomが使えない
我々のチームで管理しているクエリの中にはウィンドウ関数を利用しているものが多数ありますが、Db2 Warehouseにはその中でrandom関数を利用できないという制約があります。例えば、Memberテーブルが住んでいる都道府県のidを保持しているとしましょう。
CREATE TABLE Member (
memberId INTEGER,
prefectureId INTEGER,
name VARCHAR(50)
)
DISTRIBUTE BY HASH(memberId)
ORGANIZE BY COLUMN
この時、下記のように都道府県ごとにランダムな値を割り振るクエリは利用できません。
SELECT
memberId
,RANDOM() OVER(PARTITION BY prefectureId)
FROM
Member
random関数を利用する場合はウィンドウ関数の中での利用を回避する必要があります。
下記のようにサブクエリで割り振ったランダムな値を基準にROW_NUMBERを振り直すことで、無作為に選ばれた連番をSELECTすることが可能です。
SELECT
memberId
,ROW_NUMBER() OVER(PARTITION BY prefectureId ORDER BY randomNum) AS randomRowNum
FROM
(
SELECT
memberId
,prefectureId
,RANDOM() AS randomNum
FROM
Member
) AS A
NULLの順序が異なる
NULLを含むカラムを並び替える際に、NULLが先頭に来るか末尾に来るかはデータベースによって異なります。PureDataとIIASの並び順は表の通りです。
例えば何かしらの値でスコアリングして、大きい順に並べた結果を先頭から特定件数を抽出するようなクエリでNULLがヒットするようになってしまう可能性があります。ORDER BY ASCのケースで対応が必要な箇所はありませんでしたが、上記のようなケースが存在する場合はORDER BY DESCを利用している箇所で修正が必要です。
この件の対処法をサポートに問い合わせたところ、システム全体でNULLの並び順を指定する設定はないとのことでした。そのため、ORDER BY DESCを使っている箇所で NULLS LAST を指定することで対処しました。
上記のように指定することで対処が可能です。対応としてはクエリ自体をNULLを利用しない方式に組み替えることも考えられますが、影響範囲と改修コストの兼ね合いで一括置換できる方式を選択しました。
SORTHEAP
DWHは巨大なデータを扱うため、メモリの利用量も多くなります。特にSORTHEAPと呼ばれるメモリは、Db2 Warehouseがクエリを実行する際にJOINやソートの時に一時的にデータを格納するために使われており、パフォーマンスに大きく関わります。PostgreSQLで言う所のwork_memのようなものです。
この値を超えるデータ量を扱うと、メモリに収まらないためディスク書き込みによるパフォーマンス低下を招く可能性があります。また、オプティマイザがメモリ消費の少ない実行計画を選択することで実行時間が長くなる可能性もあります。処理に十分なメモリが割り当てられていないとパフォーマンスが顕著に低下することがあるためSORTHEAPの設定値は調整を検討する価値があります。
ただし、SORTHEAPの値はあくまで1つのステートメント単位で利用できるメモリ量であり、同時接続数が増えれば増えるほど全体として利用するメモリの量は増えてしまいます。そのためDb2 Warehouseではシステム全体でSORTHEAPとして利用できるメモリの総量をSHEAPTHRES_SHRによって規定しています。全ての実行中クエリがSORTHEAPを最大まで利用している場合、理論的に同時接続できる最大数はSHEAPTHRES_SHR/SORTHEAPによって決まります。SHEAPTHRES_SHRを超えてメモリを利用することはできないため、SORTHEAPに割り当てるメモリの量には注意が必要です。
まとめ
本記事ではIIASの特徴とPureDataからIIASへ移行する際に考慮すべきポイントをまとめました。
MAチームではMA基盤上のアプリケーションの開発・運用だけでなく、データ連携の仕組みの開発・運用も行なっており、ビッグデータを活用したデータ基盤の改善に取り組んでいます。目立たない分野ですが非常にサービスへの影響は大きく、挑戦のしがいがあるチームです。
この記事は、株式会社ZOZOテクノロジーズ TECH BLOGに掲載された記事(外部ページ)を転載したものです。




























