

























IBM Data and AI
「公平かつ信頼できる AI 」で AI 活用を次のフェーズへ
2021年06月03日
カテゴリー IBM Data and AI | データサイエンス
記事をシェアする:
NTT データ 信頼できるAIの実現に向け、IBMと技術検証を実施
現在 AI や IoT、ビッグデータを活用することにより起こる「第四次産業革命」が注目されています。その中でも特に AI 技術の発達は凄まじく、深層学習による様々な未来予測モデルや医療診断プログラムは専門家すら超えるケースが出てきています。今後の AI を活用する上で特に大切なことは、AI が組み込まれた高度なプログラムを正しく評価することです。日本のシステム開発をリードし社会を支えてきた NTT データ様が AI の公平性、信頼性の分野で IBM と共同で検証を実施しました。AI を活用した次世代のシステム開発に対する思いを NTT データ山中様、市原様に聞きます。
昨今、身近な生活や、仕事の中でも AI が活用されていると感じる場面は多いのではないでしょうか。企業内では営業、製造、IT、人事など様々な場面で AI が活用され、社員の業務を助けてくれる存在になっています。一方で AI の社会における活用がすすむとともに従来ブラックボックス化されていた AI に対する倫理や信頼、透明性の担保といった課題が問題視され、企業の AI の取り組みの障壁となっているケースも出てきています。AI を自社の武器として活用をすすめていただくうえで、今後ますます注目の高まる「信頼される AI」に関し、今回、NTT データ、IBM で共同検証を実施いたしました。
――今回 AI の信頼性の分野で検証を開始した背景を教えてください。
AI 技術の発展は著しく、従来技術ではシステム化が難しかった領域にも活用が見込まれています。一方、AI が引き起こすトラブルリスクや判断根拠の不明瞭さなどが原因で、コンセプト検証で終わってしまうケースも多くあります。実際に社会で活用されるためには、AI に高い信頼性が不可欠だと考えています。
AI の信頼性については世界各国で議論されており、日本でも国や各団体による開発ガイドライン等が策定されておりますが、具体的な取組内容については各ベンダーに委ねられており、デファクトスタンダードはいまだありません。そこで弊社では、過去の AI 開発で得られたノウハウや外部有識者のアドバイスをもとに、信頼できる AI の実現に取り組んでおります。本検証もその一環として実施いたしました。
――NTT データ様の「信頼される AI 」への取り組みをお聞かせください。
2019年に AI の開発・利活用に関する取組姿勢をまとめた「NTT データグループ AI 指針」を策定し、以後、AI プロセスや AI 技術の開発を通して AI ガバナンス向上に努めています。
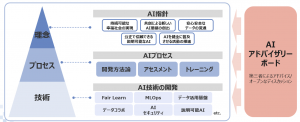
私たちのチームでは「AI の公平性」に関する技術開発を行っています。これは AI の利用により特定のグループに対して不公平を助長することがないよう、AI の挙動を定量的に分析し、適切な改善を実現する技術です。
例えばローン審査や人事採用などの業務に AI を適用する場合、性別や人種によって不適切な扱いがなされていないか確認が必要です。法律や条例・倫理観点などに基づき、有識者がヒューリスティックに確認をしているのですが、確認項目の多さや AI のブラックボックス性の問題で十分に行えていないのが実情です。私たちは誰でも安定して公平な AI を構築できるように、技術の力でこれらの問題の解決を目指しています。
――IBM では、信頼される AI の実践のために、2017年から AI 倫理のガイドラインを策定し、AI 指標の体系化に取り組んできました。お客様にご利用いただけるソリューションとして、IBM Watson OpenScale (以下、OpenScale )を展開しています。今回の検証を IBM と実施するに至った経緯を教えてください
IBM から OpenScale に関する技術紹介を受けたことがきっかけです。AI の信頼性向上を目的としたソフトウェアは研究段階のものがほとんどで、商用レベルに達しているものはあまり見られませんでした。以前から IBM とは音声認識や自然言語処理などの AI 分野で一緒に取り組んでおり、技術的に深い部分についてもサポートいただいておりましたので、こちらから共同で検証させてほしいと申し出ました。
――今回の検証内容についてご説明をお願いします。
今回は OpenScale の公平性モニタリング機能、バイアス緩和機能、説明性機能を用いて、我々が構築した AI モデルについて公平性が担保できるか検証いたしました。
具体的には以下の3点について、OpenScale (+ IBM Cloud の各サービス群)を用いてどのように実現できるか検証を行いました。
- 構築した AI モデルについて公平性評価が行えるか。
- 不公平と判断された AI モデルに対してバイアス緩和が行えるか。
- モデルの出力を説明できるか。
※本取組では、同様の内容について OSS を用いた比較検証も実施いたしました。本記事では OpenScale の検証内容を中心に記載いたします。詳細につきましては本ページ下部の問い合わせ窓口までご連絡ください。
<検証項目と使用したソフトウェア>
| 検証項目 | IBM Cloud を使用した検証 |
OSS を使用した検証 |
| (モデルを構築できるか) | AutoAI | (XGBoostによる実装) |
| モデルについて 公平性評価が行えるか |
Watson OpenScale | Fairlearn |
| 不公平と判断されたモデルを対処できるか | Watson OpenScale | Fairlearn |
| モデルの出力を説明できるか | Watson OpenScale | InterpretML |
検証結果
1. 構築した AI モデルについて公平性評価が行えるか。
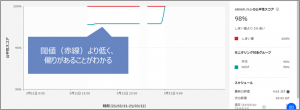
OpenScale の公平性モニター機能にて、公平性スコア(Disparate impact)を継続的に評価することができました。OSS でもこの指標について評価することはできますが、モデル運用時のどの段階で公平性が崩れていたか確認したい場合には複雑なパイプラインの構築が必要になります。その点、OpenScale では自動的に行われるため、優位性があるといえます。
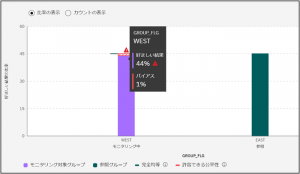
2.不公平と判断されたAIモデルに対してバイアス緩和が行えるか。
個々のバイアス、グループのバイアスが生じているモデルに対し、それらのバイアスを緩和したモデルを生成することができました。この操作は SDK や API からだけでなく、Web UI から簡単に実施することができました。またバイアス緩和されたモデルについては自動的に Web API が作成されるため、公平なモデルへすぐアクセスすることができました。
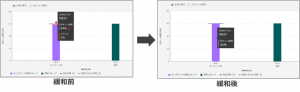
3.モデルの出力を説明できるか。
![]()
LIME によって予測結果にどの特徴量が寄与したか確認することができ、その結果をもとに不公平の原因となるトランザクションを抽出することができました。

――今回のご検証の結果、製品へのご要望がありましたらお聞かせください。
AI の公平性を評価するために必要な機能が一通りそろって、またそれらを手軽に利用できるソリューションだと感じました。AI 活用においては運用面が特に課題となることが多いのですが、OpenScale では自動的にモデルの入出力を監視し、公平性や精度について手間なく確認できるため、非常に良いと感じました。また、AI モデルの構築からサービング、運用に至るまで Web UI で実施できる点も魅力的です。
誰でも簡単に使えるようになっている一方、より詳細にカスタマイズしたいと感じる部分もいくつかございました。例えば OpenScale では公正性スコアは1種類だけですが、お客様の要望に合わせて他の指標を選択したいケースも考えられます。そういった場合にも対応ができると活用幅がさらに広がると感じました。
――OpenScale は AI の信頼性を担保するだけでなく、それによって本番環境でAI運用の自動化を実現するためのソリューションでもあります。“OpenScale with any model, anywhere” という理念のもと、以下の観点で拡張を続けています。
- オープン・プラットフォームにより AI ライフサイクルのオペレーションの自動化を促進
- 他ベンダーのクラウドを含む AI モデルのデプロイ環境の充実
- 機械学習、深層学習のモデルの健全性に対する洞察を提供するフレームワークや統合開発環境、ホスティング・エンジンの拡張
――NTT データ様の今後の取り組みについてお聞かせください。
本検証を通して「公平かつ信頼できる AI」の実現に不可欠な、公平性の担保・評価手法について確認することができました。今後は検証結果をもとに開発プロセスをアップデートし、実際のプロジェクト現場で活用できるよう具体化を進めます。
NTT データでは、人間とAI(人工知能)が共生する「より豊かで調和のとれた社会」の実現に貢献するため、これからもAI ガバナンスに関する取り組みを拡大・継続してまいります。IBM とは今回の検証のように、双方の強みを活かして、国内外の AI 品質の向上に貢献していきたいと考えています。
――AI 活用をするうえで課題となるのが、その AI の判断が「公平かつ信頼できる」のかという問題です。今回の NTT データ様におかれます IBM OpenScale 検証結果を活用し、両社のノウハウを活かすことで共に社会に価値を提供していければ、と考えます。






関連リンク

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む
データ分析者達の教訓 #21- 異常検知には異常を識別する「データと対象への理解」が必要
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの宮園です。IBM Data&AIでデータサイエンスTech Salesをしています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、デー ...続きを読む

【予約開始】「SPSS秋のユーザーイベント2024」が11月27日にオンサイト開催
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
本年6月800名を超える方々にオンライン参加いただいたSPSS春のユーザーイベントに続き、『秋のSPSSユーザーイベント』を11月27日に雅叙園東京ホテルにて現地開催する運びとなりました。 このイベントは ...続きを読む