Data Science and AI
IBM、クラウドネイティブ AI スーパーコンピューターを強化
2023年12月26日
カテゴリー Data Science and AI | IBM Cloud Blog | IBM Data and AI | IBM クラウド・ビジョン
記事をシェアする:

AIにおいて大きな進歩が遂げられ、数百億ものパラメーターを持つAIモデルなど新技術が実際のユース・ケースで一般的に使われるようになって1年になりました。その一年の間にIBMではwatsonx を立ち上げました。これは、IBM Researchコミュニティーから生まれた多くのイノベーションを活用し、先進的なAI機能をさまざまな業界のお客様に利用可能とする企業向けAIとデータのプラットフォームです。
AI ライフサイクルのさまざまな段階を効率的に実行するために、適切な計算能力を備えたシステムを設計する必要性が高まっています。このことが、IBMが昨年IBM Cloud 内のAIスーパーコンピューターであるVelaを構築することに決めた理由の一つです。Velaでは、データの前処理、モデルの学習とチューニングから、導入、さらには新しい製品のインキュベーションに至るまで、すべてのAIワークフローをIBM Cloud内で効率的に実行することができます。
Velaは柔軟性と拡張性を備えており、今日の大規模な生成AIモデルを学習することができるだけでなく、将来生じるかもしれない新しいニーズに適応できるように設計されています。また、世界のどこにでも効率的にインフラを展開して管理できるように設計されています。過去1 年間にわたり、世界中のIBMにいるAI技術者がVela上でAI技術を学習したり試験運用してきたりしましたが、その中には、7 月に一般利用可能 になった次世代AIスタジオ watsonx.aiが含まれます。watsonx.aiのようなプラットフォームをこれほど早く世界中でオンライン利用可能にすることは、Velaのクラウド・ファースト・デザインなしでは不可能だったものと思われます。
この一年でIBMは将来に向けてVelaを拡張してきました。このブログでは、この一年にVela に対して行ったいくつかの大きなアップグレードを共有します。そこには、システム能力の約倍増と、ネットワーク速度の劇的向上が含まれます。どんな新機能があり、どのように実現したかを見てみましょう。
Velaの高速化
今のAIブームの一つの特徴は、モデルの学習や展開に必要となるインフラストラクチャーへの依存性です。より大きなモデル、より大きなデータ・セット、そしてより高速化の実現へとAIを進歩させることは、ひとつのジョブにより多くのGPUを使用することを意味します。より多くのGPU計算を並列して行うには、GPU間通信が計算処理のボトルネックにならないように、ネットワーク・パフォーマンスを相応に向上させる必要があります。今年、Velaのネットワークに大規模なアップグレードを行いました。これにより、個々の学習ワークロードをジョブごとに数千のGPUに効率的に拡張することができます。この目的のためにIBMがVela に導入した核となる技術は、RoCE(RDMA over Converged Ethernet)と GDR(GPU-direct RDMA)でした。
リモート・ダイレクト・メモリー・アクセス (RDMA) を使用すると、1つのプロセッサーが別のプロセッサーのメモリーにアクセスでき、その際にどちらのコンピューターのOS(オペレーティング・システム)も関与する必要がありません。これにより、関与するプロセスが極力減らされ、プロセッサー間の通信が大幅に高速化されます。 GPU-direct RDMAは、ネットワーク・カード(下図参照)を利用してイーサネット・ネットワークを経由し、あるシステム上のGPUが別のシステム内のGPUのメモリーにアクセスすることを可能にします。Velaのイーサネット・ネットワーク上で GPU-direct RDMAを実現したことで、ネットワーク・スループットを2倍から 4倍向上させ、ネットワーク待ち時間を6倍から10倍短縮しました。
また、以前よりもはるかに大規模なモデルにほぼ線形的にワークロードをスケールアウトすることもできます。watsonx Code Assistant for Zサービスの重要な構成要素として最近発表した200億パラメーターのGraniteモデルの学習がその例です。RoCEとGDR のアップグレードは、数年間の研究の成果です。これには、システム・ファームウェアからホストOS、仮想化、アンダーレイ・ネットワークおよびオーバーレイ・ネットワークに至るまで、クラウド・スタックのほぼすべての部分を同時に変更し、機能拡張する必要がありました。
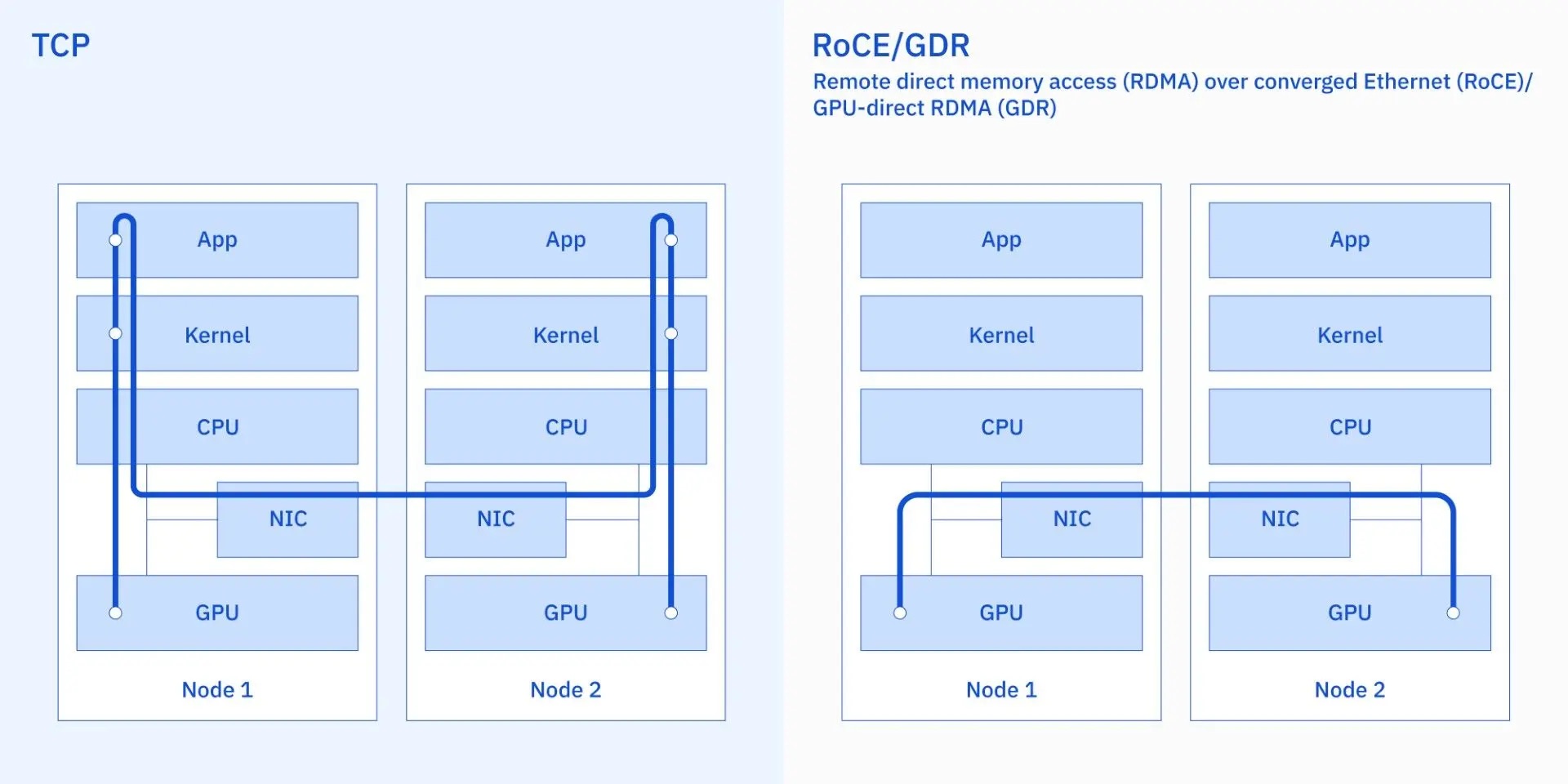
RoCE + GDR の導入前と導入後の通信パスの違いを示す図
キャパシティーの拡張
Vela は拡張可能であるように設計されていましたが、単にGPUをVelaに追加するだけではなく、それをスペースとリソースについて効率的なやり方で実現したいとチームは考えていました。特に、サーバー・ラックの密度を2倍にする方法、すなわち、必要なスペースやネットワーク機器を増やさずにキャパシティーを約2倍にする方法を模索しました。
AIワークロード・パターンを分析した結果、ワークロード・パフォーマンスに影響を与えることなく、既存の電源および冷却リソース内でキャパシティーの拡張を進めることができると判断しました。その後、パートナーと協力して、高度に最適化されたパワーキャッピング・ソリューションを開発しました。これによってVelaはラックで使用可能な電力量を本質的な意味で「オーバーコミット」することができるようになりました。そして、Vela上で効率的に稼動する必要があるシステムやワークロードに悪影響を与えることなく、キャパシティー拡張後も関連要素すべてが安全に機能することを確認するためのテスト・フレームワークを開発しました。 その結果、Velaは現在、アップグレード前の約2倍のGPUで構成されています。
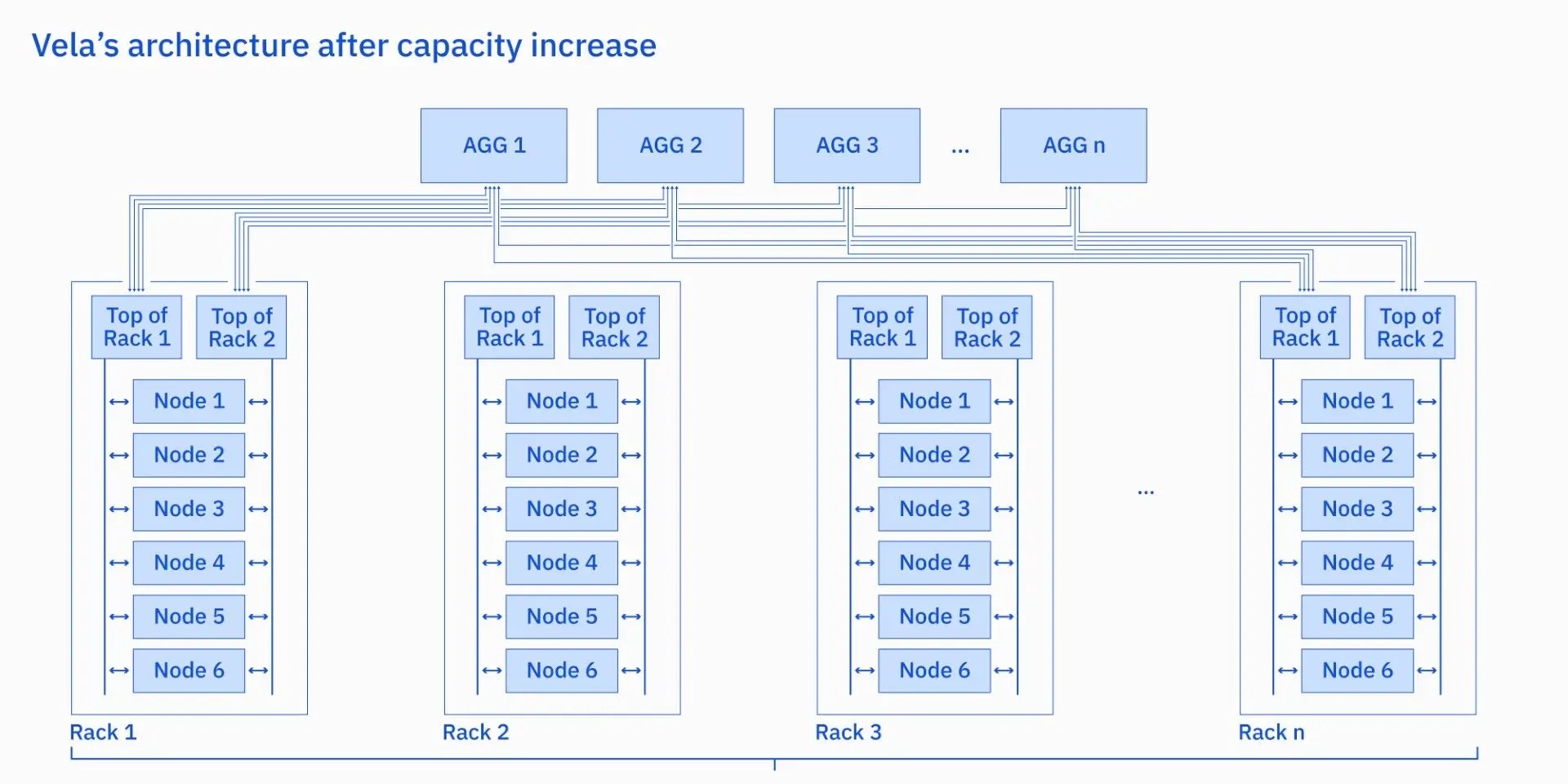
キャパシティー拡張後のVelaアーキテクチャー
オペレーションと診断の改善
また、Velaのチームは、システムをより効率的に実行する方法についても検討していました。 AIサーバーは、その複雑さのため、多くの従来型クラウド・システムよりも高い障害率を持つのが一般的です。そして、予期しないような(場合によっては発見も難しい)形で障害を起こします。しかもノードで障害が発生したり性能が低下したりすると(時には個々のGPUでの問題すらも)、数百または数千のGPUで実行されているトレーニング・ジョブ全体のパフォーマンスに影響を与えることがあります。このような種類の問題を検出して発見し、可能な限り迅速にアラートを発行できるような自動化は、環境の生産性を維持するために重要です。
今年、IBMのチームはIBM Cloudでの自動化を強化し、Velaのこのようなハードウェア障害や機能低下を発見して理解するのにかかる時間を半分に短縮しました。これで、サーバーを以前よりもはるかに迅速に実動フリートに戻すことができるようになりました。このように複雑な環境を管理することで得られた教訓は、IBM Cloudの他の仮想プライベート・クラウド(VPC)環境全体の運用を改善するために、より幅広く展開されています。
これから
これらのアップグレードの前からVela は既に、世界中でwatsonx.aiの立ち上げと展開、そしてその基礎となるコア・プラットフォームであるOpenShift AI の開発を加速した強力なプラットフォームでした。IBMは、それに加えた上述のようなVelaの最新のインフラストラクチャー拡張を活用し、お客様が直面している最も差し迫ったビジネス上の問題の解決に役立つ、ますます強力なAIモデルを学習しています。
今がまだこのAIブームの始まりであるのとほぼ同じように、IBMのAIインフラストラクチャーのイノベーション・ジャーニーはまだ始まったばかりです。 今年の初めに、IBM は IBM Cloud 上の追加の GPU オファリングを発表し、エンタープライズ・ワークロードのための基盤モデルを学習/チューニング/推論するために設計された革新的なGPUインフラストラクチャーを利用可能にしました。IBM AIUチップなど、さらに新しいAIインフラストラクチャー技術の開発が進んでいます。今後数年間でさらに多くのことが実現するのをご期待ください。
この記事は英語版IBM Researchブログ「Supercharging IBM’s cloud-native AI supercomputer」(2023年12月13日公開)を翻訳し一部更新したものです。

ジェネレートするAI。クリエートする人類 。 | Think Lab Tokyo 宇宙の旅(THE TRIP)
IBM Data and AI, IBM Partner Ecosystem, IBM Sustainability Software
その日、船長ジェフ・ミルズと副船長COSMIC LAB(コズミック・ラブ)は、新宿・歌舞伎町にいた。「THE TRIP -Enter The Black Hole-」(以下、「THE TRIP」)と名付けられた13度目の ...続きを読む

IBM Cloud『医療機関向けクラウドサービス対応セキュリティリファレンス (2024年度)』公開のお知らせ
IBM Cloud Blog, IBM Cloud News
このたびIBM Cloudでは総務省ならびに経済産業省が提唱する医療業界におけるクラウドサービスの利活用に関するガイドラインに対応していることを確認し、整理したリファレンス『医療機関向けクラウドサービス対応セキュリティリ ...続きを読む

イノベーションを起こす方法をイノベーションしなければならない(From IBVレポート「エコシステムとオープン・イノベーション」より)
Client Engineering, IBM Data and AI, IBM Partner Ecosystem
不確実性が増し、変化が絶え間なく続く時代には「イノベーション疲れ」に陥るリスクがある。誰もがイノベーションを起こしていると主張するならば、結局、誰もイノベーション(革新的なこと)を起こしてなどいないことになるだろう 当記 ...続きを読む