SPSS Modeler ヒモトク
【リレー連載】わたしの推しノード –リレー完結!解説と振り返り
2020年12月16日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
IBMの京田です。
SPSS Modeler 推しノードリレー連載いかがでしたでしょうか? ユーザーイベントをきっかけに2020年2月にリレー連載を開始。秋のオンラインユーザー会でも、内容に触れるなどを経て、12月に私の回でリレー連載は完結いたします。22名のお客様とIBMメンバーが気に入ったノードを、理由やTipsと共に紹介してくださいました。なるほどSPSS Modelerが長くユーザー様に愛されるのは使いやすさだけでなく、奥の深さにもあるのだとあらためて感心しました。私なりにこの1年間の連載を感謝と共に振り返り、解説させていただこうと思います。
推しノードリレー連載タイトルとリンク
以下敬称略
|
連載
|
ノード
|
タイトル(リンク)
|
筆者
|
所属
|
| 1 | (プロローグ) |
SPSS Modelerノード 総選挙結果をヒモトク |
岸代憲一 | IBM |
| 2 | ユーザー入力 |
知られざる名脇役 |
西牧洋一郎 | IBM |
| 3 | データ検査 |
予測の出来を左右するデータ理解の達人 |
神子島隆仁 | 荏原製作所 |
| 4 | 再構成 |
ID付POSやIoT時系列データから |
河田大 | IBM |
| 5 | データ 自動準備 |
お助けロボ参上!? |
木暮大輔 | MAI |
| 6 | CHAID |
絶対エース「CHAIDノード」 |
山下研一 | IBM |
| 7 | フィールド 作成 |
新たなデータの道を切り開く、 |
伴俊広 | 三菱自動車工業 |
| 8 | 異常値検査 |
”いつもと違う”を見逃さない! |
牧野泰江 | IBM |
| 9 | RFM集計 |
顧客データ分析の頼れる助さん&格さん |
畠慎一郎 | SmartAnalytics |
| 10 | SMOTE |
機械学習時代の申し子 |
西澤英子 | IBM |
| 11 | TwoStep |
文系データ分析者の強い味方 |
鳥海淳一 | プラス |
| 12 | グローバルの 設定 |
裏方の魔術師「グローバルの設定」が |
守谷昌久 | IBM |
| 13 | レコード結合 |
ストリーム領域のキーマン |
櫛田弘貴 | スタッツギルド |
| 14 | 時系列 |
過去の山や谷を捉えて幅でトレンドを |
上田延寿 | IBM |
| 15 | 置換 |
フィールドのマエショリスト |
太宰潮 | 福岡大学 |
| 16 | データベース |
SQL魔法使い |
水谷 好伸 | IBM System Engineering |
| 17 | KNN |
似た者探しの名人 |
田口仁 | ADK マーケティング・ ソリューションズ |
| 18 | ベイズ |
隠れた関係を見つける名探偵 |
小林竜己 | IBM |
| 19 | CPLEXの 最適化 |
最強のラスボス |
近澤喜史 | 日本情報通信 |
| 20 | スーパーノード |
ストリームを変幻自在に整頓活用する超人 |
坂本康輔 | IBM |
| 21 | シミュレーション |
リスク博士 |
木田浩理 | 三井住友海上火災 |
| 22 | 拡張ノード |
一流エージェント「拡張ノード」。 |
千代田真吾 | IBM |
| 23 | 自動分類 |
機械学習の多重奏!名指揮者 |
林啓⼀郎 | AIT |
| 24 | (エピローグ) |
SPSS Modelerノード |
京田雅弘 | IBM |
入力で選ばれたふたつの推しノード
私自身、個人的にはSPSS Modelerで天候データの活用を過去に記事にした経緯もあり
*リンクはこちら→ Weather Company Data for Advanced Analytics
「TWCインポートノード」の回があると密かに期待していました。しかし天候データの活用では多地点での運用が前提となり「TWCインポートノード」はIBM社員のデモ以外には役に立たないとあって、当然リレー連載では取り上げられることがありませんでした。The Weather Companyの提供するデータをSPSS Modelerで利用されるお客様は例外なく、「データベースノード」を利用します。
その「データベースノード」は「SQL魔法使い」と称され第16回で解説いただきました。非常に多くのModelerユーザーが利用するこのノードはオンプレやクラウドのデータベースに簡単に接続でき、SQLプッシュバックと呼ばれる機能によって大規模データ利用時に威力を発揮します。
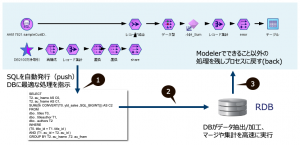
試行時にはCSVなどの「可変長ファイルノード」、マスターデータの参照時には「EXCELノード」も利用されますが、SPSS Modelerの強力な魔法を享受するためにもデータベース連携をお勧めします。記事の中にあるようにSQLエンジニアがコードを加筆するとその性能がさらに活かされる点も、強調させていただきます。
「ユーザー入力ノード」が第2回で知られざる名脇役として紹介されました。なんと自分で組み合わせテーブルが作れるため、私たちがデモ用にサンプルデータを作るのには便利なのですが「ユーザー様が使う余地があるのか?」と疑問視する声も。しかし、記事のようにシミュレーション用のテーブル作成や、間欠商品の需要予測時に実績のない日付データを補完するなど、意外な用途で役に立ちます。総選挙では圏外の地味ノードから連載が始まって心配された方も多いと思うのですが、ぜひ触れてみてください。
データ加工の定番推しノード
なんと例外なく全てのユーザーが利用する「レコード集計ノード」は単独推しとして舞台に上がりませんでした。シンプルすぎてフォーカスされないこのノードの名誉のためにもお伝えしたいのですが総選挙では2位!連載中にもあちこちで静かに主役を盛り上げていました。
レコード集計を特定の用途にカスタムしたものが「助さん」と喩えられた第9回 「RFM集計ノード」です。顧客行動を捉えるのには来店後の経過日数(R)購入金額(M)、を集計するのが定石。それをこのノードひとつで計算し、後続の相棒格さん「RFM分析ノード」に繋げてセグメント化してゆきます。
RFMで顧客価値を得ると、今度は顧客の質について特徴量を作りたくなります。そこで活躍するのが総選挙6位の 第4回「再構成ノード」です。例えば60あるカテゴリのどれを、何円購入したのかID付きPOSデータからSQLやコードで加工すると骨が折れます。60のカテゴリを一瞬で横持ちできるこのノードをスゴ技職人と呼ぶことにどなたも異論は無いはずです。
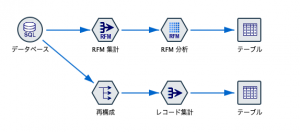
顧客がどのカテゴリで何円購入したかをフィールド(列)で準備し、顧客毎にレコード集計すると、SOW(顧客内お財布シェア)と呼ばれる特徴量が出来上がります。その時用心したいのが該当カテゴリを購入していない顧客には実態のないNullを与えてしまう点です。後続の演算を考慮してNullをゼロに置き換える前処理をするのが第15回フィールドのマエショリスト「置換ノード」です。「おきかえ」ではなく「ちかん」と呼ぶ人も多く、「置換したいけどうまくできない」という表現に周囲が騒つく「あるある」も有名です。
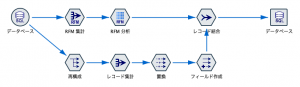
そして新規フィールドで60のSOWを単独かつ素早く作成できるのが 第7回フィールドの俊足「フィールド作成ノード」です(総選挙5位)。先の「置換ノード」と「フィールド作成ノード」は「@関数」を覚えると、とても有効な特徴量を作れることでも知られており、中でもIoTデータの時系列差分の加工には定評があります。
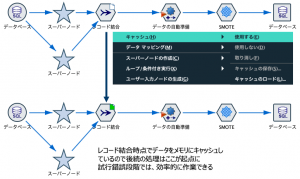
ここまでお伝えした、顧客価値集計と、SOWを顧客IDで結合するのが総選挙4位の第13回 でキーマンと謳われた「レコード結合ノード」です。SPSS Modelerは一度別々のプロセスで加工してきた処理を再び結合でき、Phytonなどのコーディング処理と比較して、とても便利で共有しやすいと言われます。作成する中間データを都度あちこちに格納して結合し続けると処理が煩雑になりますが、Modelerのストリームは思考が途切れず直感的で秀逸と褒めていただきます。このノードが総選挙4位である理由もそのためだと解釈しています。
データ加工の困りごとを解決する推しノード
例えばここまでのストリームだけでもノードの数が9つになり、キャンバスが散らかってきました。第20回整理整頓の超人「スーパーノード」の手にかかると以下のように星型に収納してくれます。
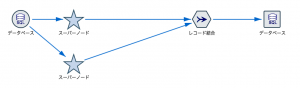
記事の中ではパラメーターを使った神業と、Collaboration and Deployment Services(CADS)への業務展開が紹介されました。CADSはリアルタイムスコアリングと自動化が主な役割。しかし、ここ最近、シンプルかつ意外な利用方法が脚光を浴びています。
それはModelerを保有していない業務担当者のWebポータル画面から欲しい条件を選ぶと、必要なデータをテキストデータで届けるというものです。非定型オンラインバッチによる大規模データの効果的でセキュアな配布方法としてデータ活用を普及させたい組織が好んで利用します。
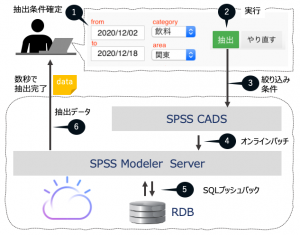
* demo動画→ModelerのないユーザーへのCADSを用いた便利なデータ抽出の仕組みはこちらから
話をデータ加工に戻します。特徴量を作りながら精度の高い予測モデルを作るにあたって難題があります。ひとつは入力データが多い場合に、欠損や異常値の処理を含めて個別に手間がかかるという問題です。第5回では「データの自動準備ノード」をお助けロボと命名して、データ加工の自動化について触れられました。効率化だけでなく、精度が向上している様子を見てトライしようと思われた読者も多いはずです。
また、予測対象が極端に偏っている問題も分析者の頭を悩ませます。故障率が0.1%の、アンバランスなデータで学習させると、どんな場合でも「故障なし」と予測して見かけ上の精度を99.9%にしてしまう「無意味なモデル」を作ります。これまでModelerユーザーはこの問題を回避するべく「バランスノード」を使ってきました。しかし、ここ数年は単純なバランシングではなく第10回の機械学習の申し子ともいうべき「SMOTEノード」が脚光を浴び、実効性の高いオーバーサンプリングを選ぶユーザー様が増えました。
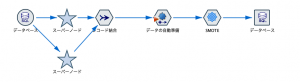
実は「SMOTEノード」はModelerに搭載されているのですが、Pythonのライブラリをちゃっかり呼び出して使っているのです。Modelerに存在しなくてもPythonやRのライブラリを自由に呼び出せるノードが存在します。第22回で、必要なタレントを外部から連れてくるエージェントになぞらえられた「拡張ノード」です。記事では自然言語処理のPythonライブラリJanomeをModeler上で実装する例が示され、トライした方もいらっしゃると思います。
外部の機能を利用する点では、最適化ソルバーCPELXも忘れてはいけません。比較的古くから搭載されながら、ベールに包まれていた「CPLEXの最適化ノード」を第19回 で、ラスボス扱いで取り上げていただきました。個別に最適な予測モデルを作りながらも、全体として最も利益が高くなるように制約を考慮しながら最適化したい。そういう願いはデータ活用を高度化した最終局面で訪れます。IBMがSPSSより先に買収したCPLEXは、大規模な問題を高速に解くことができる優れものですが、一定の制限範囲であればライセンスを準備しなくてもModelerのノードからトライ可能です。ぜひ試していただきたいです。

モデルを自動作成する推しノード
昨今の事情から日々報道で数字の増減や予測を目にすることが多くなりました。過去のトレンドから将来を予測する第14回 「時系列ノード」はリスクを幅で想定する真の勝負師だと言えます。データに最も当てはまる時系列モデルを自動選択する利便性に浮き足立つことなく需要予測の留意点にも目を向けるべきだと筆者は触れています。業務でコントロールできる範囲を先に洗い出し、どの程度の予測誤差ならモデルの利用価値があるのかを予め検証するべきという主張です。これに力強く同意された読者は少なくないはずです。
データを入れると自動で最適な予測モデルが得られるのは、時系列ノードだけではありません。総選挙7位で第23回 の「自動分類ノード」は17種類の判別予測モデルを同時に実行し評価してくれます。その上、出来の良い複数モデルのアンサンブル(重奏)もするとくれば、このノードを名指揮者と例えるのも自然です。IBMではAutoAIやDriverlessAIの2つのAI自動化ツールを提供しています。これらは、個別モデルのパラメータ最適化(HPO)も自動で行うため、それにはかないませんがHPOで得られるゲインが限られる場合には「自動分類ノード」で充分なのではないかとも思います。
モデルをビジネスの現場で説明できる推しノード モデル作成で精度以上に重視しなくてはならないもの、それは現場です。どんなに精度の高いモデルでもビジネスの現場で利用されなければ価値は生み出せません。また現場で利用されるには担当者がモデルを納得する必要があります。なぜ、このようにモデルは予測したのか。根拠とメカニズムが現場感覚と乖離すると担当者は不信感をもち、結果モデルの採用は見送られることになります。
このモデルの説明責任を果たすのが映えある初代総選挙1位「CHAIDノード」第6回 絶対エースです。決定木分析はロジスティック回帰と並んで、説明のし易いモデルと言われています。その決定木の中でもCHAIDは多分岐による要因構造が直観的であることから統計用語を最小限に説明できると大評判です。また多少精度は犠牲にしてでも分岐をカスタマイズして現場の肌感覚にロジックをあえて寄せる芸当もユーザー様が手放せない理由と言えます。
また説明変数間にもそもそも因果関係がある場合、そのメカニズムを含めて見抜いてくれるのが、名探偵 第18回「ベイズノード」です。決定木はモデルを樹形図で構造を提示しますが、「ベイズノード」は変数間の関係を矢印の向きで表現する「グラフ構造」で表します。因果関係を解きほぐしながらより、確かなモデリングを探索するアプローチは人に説明することを前提としています。精度至上主義からの反動で説明可能なAIの必要性が叫ばれる中、あらためて研究に値するノードと言えます。
似ている(いない)ケースを探すモデルの推しノード
現場での説得に使われるモデルといえばクラスタリングです。分析者によって類型化するクラスタの数も出来栄えもガラリと変わる教師なし型学習は、現場力が要求されます。第11回 「TwoStepノード」を筆者は文系分析者の強い味方と解説します。クラスタの数kを自動選択するのも理由の一つですが、ビジネスの文脈にあったクラスタ特徴のストーリーテリングが現場の共感を得やすく、施策適用に誘導しやすいからだそうです。数字が全てと思われがちなデータサイエンスの世界で、感性もまた重要なのだと勉強になりました。
クラスタは行動や質の近いグループ毎に作戦を練り、グループ毎に施策を展開します。いっぽうで過去に類似する個体に目をつけて、競合対策やリスク回避をする個別対応を目指す手段も存在します。似たもの探しの名人、第17回 の「KNNノード」はその代表です。クラス分類だけでなく回帰でも使えるこのノードは、似た顧客を見つけて、その顧客が購入した商品をレコメンドしたり、似たセンサーデータ情報から後のインシデントに備えるなどを示唆してくれます。
これまでと似た行動パターンや、似たセンサー挙動があれば良いのですが、ほとんど類似ケースが見当たらない、、という場合があります。その特異度は詐欺や経験のない故障を察知するのに用いられ、異常検知と総称されます。Modelerでは第8回「異常値検査ノード」が該当します。捜査官とタイトルで比喩された通り、見覚えのない手口や設備監視ログから不自然さをスコアする凄腕が今後ますます世の中の役に立つと思うとワクワクします。
出力タブの意外な大物ノード
総選挙3位の大物がまだ出力パレットに残っています。第3回 「データ検査ノード」です。このデータ理解の達人は筆者曰く、理解するだけではなく欠損や異常値の処理も自動的に行ってくれるため、データの自動準備と合わせて、初期のクレンジングで大活躍します。流行りのアルゴリズムも良いのですが、きちんとデータを俯瞰して方針をイメージしてから、丁寧にデータの不備を整える姿勢は、有名なデータサイエンティストほどお持ちだと認識しています。この3位が意外だと思う方は是非使ってみてください。
SPSS Modelerで賭博の有名な、あのモンテカルロシミュレーションができると、連載で知ったユーザー様も多かったようです。データの量が限られていても不確定要素も織り込んだ意思決定に迫られた時、役に立つのが第21回 リスク博士「シミュレーションノード」です。本題から外れていて恐縮ですが、筆者がチョコ菓子のキャラシール集めにこの技術を使ったくだりは大変面白く、声を出して笑ってしまいました。私も賭博以外の日常生活で応用してみたいと思いました。
最後に触れるのはベテラン推し!第12回 裏方の魔術師「グローバルノード」です。「Modelerにこんな機能が欲しい」とリクエストされ、もう搭載済み「あるある」が存在します。「GUIループ」「モデル自動分割」に並んで「統計量のキャッシュ」もそのひとつ。1度計算させた、合計や平均などの統計量をセッション中に呼び出し再計算させるという機能です。顧客ランク別の累積購入金額比率を求めるといった集計に重宝します。

この統計量のキャッシュも、加工中のデータキャッシュも、1999年のSPSS Modeler日本語版リリース当時から存在するのですが「あるなら早く教えてよ!」と未だにユーザーから真顔で突っ込まれます。
推しノード達よ永遠(とわ)に
Modeler18.2.2の標準ノード数はなんと141。今回は、登場しなかった逸材(Jr.)もまだまだあり、みなさんだけが強烈に推しているノードもあると思います。また「あのノードのこれが好き」談義をブログ以外の場でも良いのでできると嬉しいです。
リレー連載は一旦終了しますが、今後も正解なき課題と向き合うユーザー様のために、推しノードが、SPSS Modelerが紐解く世界を共有できれば幸いです。
日本のユーザー様と共に、SPSS Modelerは成長をしてきました。その歴史は、他のツールでは決して真似の出来ない機能としてノード一つ一つに反映がされています。これからも日本からの要望を製品に取り入れるべく、みなさまと一緒に歩んでゆきたいと思います。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら

京田 雅弘
日本アイ・ビー・エム株式会社
クラウド& コグニティブ・ソフトウェア事業本部Data and AI事業部
Data Science & AI テクニカルセールス部長

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む