


























牧野 泰江
日本アイ・ビー・エム株式会社
東京ソフトウェア&システム開発研究所
データサイエンス&AIサービス
2020年05月28日
カテゴリー Data Science and AI | IBM Data and AI | SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:

今回は、IBM ソフトウェアサービスの牧野が担当させていただきます。私の推しノードをご紹介する前に言わせてください。推しを1つに絞るのはなかなか難しいです。SPSS Modelerはバージョンアップの度に魅力的なノードが追加されます。SPSS Modelerの前身であるClementineから成長を見続けている身としては、目移りせずにはいられないですね。ついつい推し変なんてこともあります。そんな私の今の推しは「異常値検査ノード」です。
異常値検査ノードは、教師なし機械学習の一種であるクラスタ分析を活用し、データ全体から見た相対的な異常度が算出されます。また、その異常度の算出過程において、寄与度の高い特徴量をそのスコアと共に表示してくれます。今回は、このノードの活用例を2例紹介します。
一つ目は、アンケート集計の場面をイメージし、データの集合から相対的に異常なデータを抽出し、正常なデータセットを作成する事例を紹介します。
二つ目は、センサーデータの分析の場面をイメージし、膨大な稼働データから特異なデータを抽出する事例を紹介します。
大量のアンケート結果を集計する際には、外れ値に注意する必要があります。外れ値の確認には、ヒストグラム等を作成しデータ全体の状況を確認することが一般的です。この異常値検査ノードも外れ値を確認する方法の一つとして活用が可能です。
ストリームの全体図を示します。入力データはアンケートの結果をイメージしています。
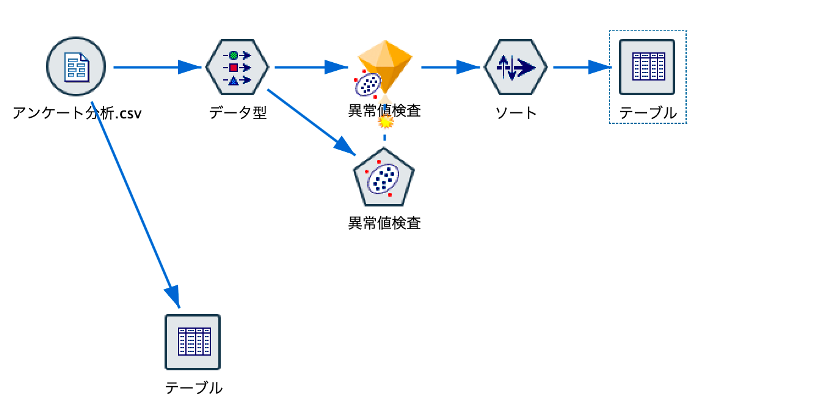
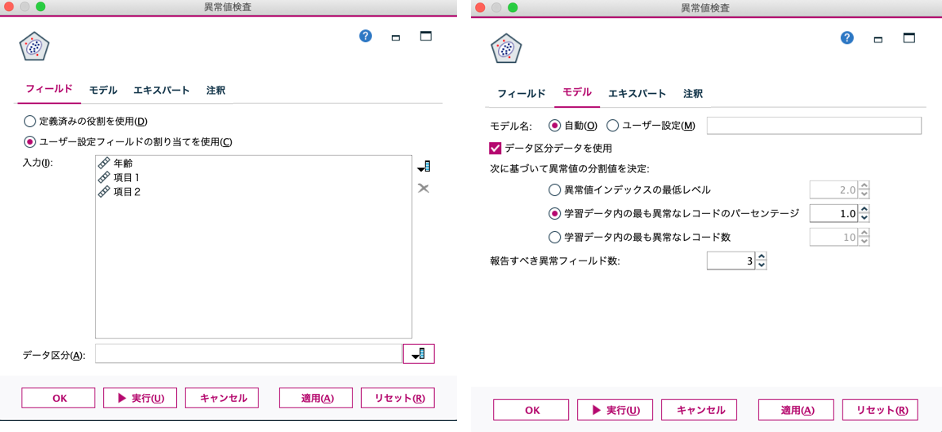
モデルの設定は、エキスパートタブで詳細に設定できますが、今回はフィールドの定義のみで実行します。
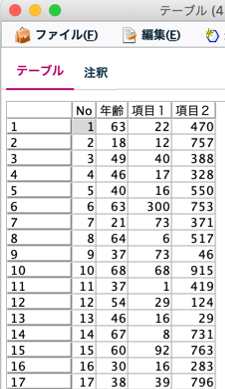
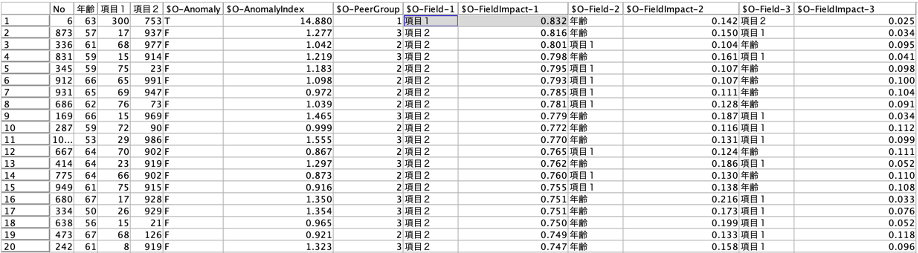
ストリームには、ソートノードが入っていますが、先に結果のテーブルを説明します。「$O-Anomalyindex」は、レコードの異常度の計算結果、「$O-Field-1」には異常度の算出過程において最も異常度が高かった項目名、「$O-Fieldimpact-1」にはその異常度が出力されています。
今回は、ソートノードにて「$O-Fieldimpact-1」を降順に並び替えています。よって、このストリームでは各項目において、相対的に異常度の高いアンケートの項目を順番に表示する事となります。
出力結果から、最も異常度の高いアンケートは、No.6で項目1が特異という事が分かります。入力データは作為的に作成しており、項目1については0〜100の範囲でランダムに作成し、No.6のみ300という範囲外の値が入力されています。このレベルであればヒストグラムで見つけることも可能ですが、異常値検査ノードは標準的に装備されているノードですので、一度実行し、異常度算出結果を確認してみると違った発見があるかもしれません。
大量のセンサーデータから異常な状況を発見する方法は、様々ありますが、その動作特性によっては、異常値検査ノードにより発見が可能です。具体的には、ある特定の条件で正常時には時系列的に同じ動きをするデータ、例えば、家庭用扇風機の羽の回転をイメージして下さい。電源を入れると、徐々に回転が早くなって、一定の回転数に落ち着きます。この回転数の上昇の仕方は、同機種であれば基本的に同じですが、モータの調子が悪くなると回転数の上がり方は変化することが想像できます。ただ、どのように変化するかを予測することは難しい様に思えます。そこで、この回転数の上がり方自体をデータセットとして、異常値検査ノードに取り込むことで、異常な個体の抽出を目指します。
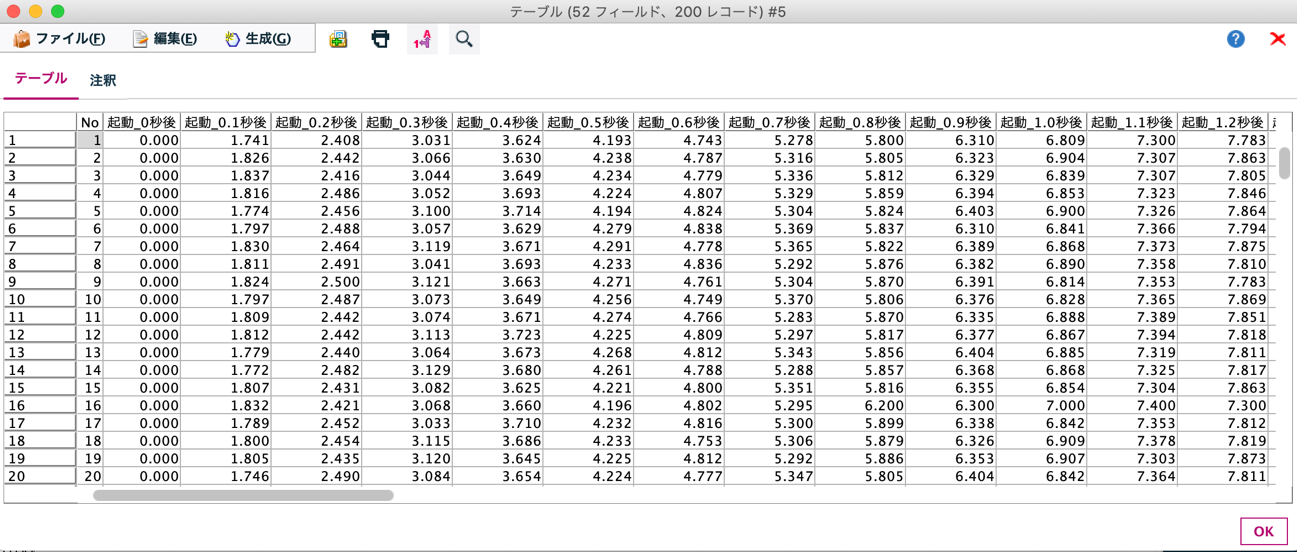
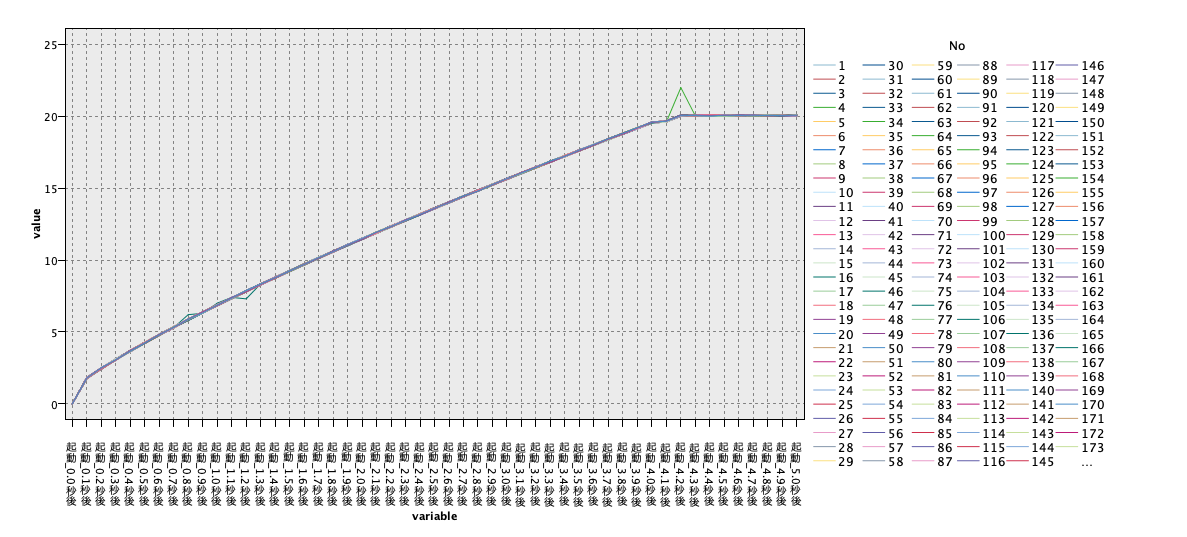
ストリームの全体と入力データを示します。入力データは200個の扇風機の起動0秒時点から5秒間の回転数の時系列データ(横持ち)をイメージしています。モデルやソートの設定は先と同じですので省略します。
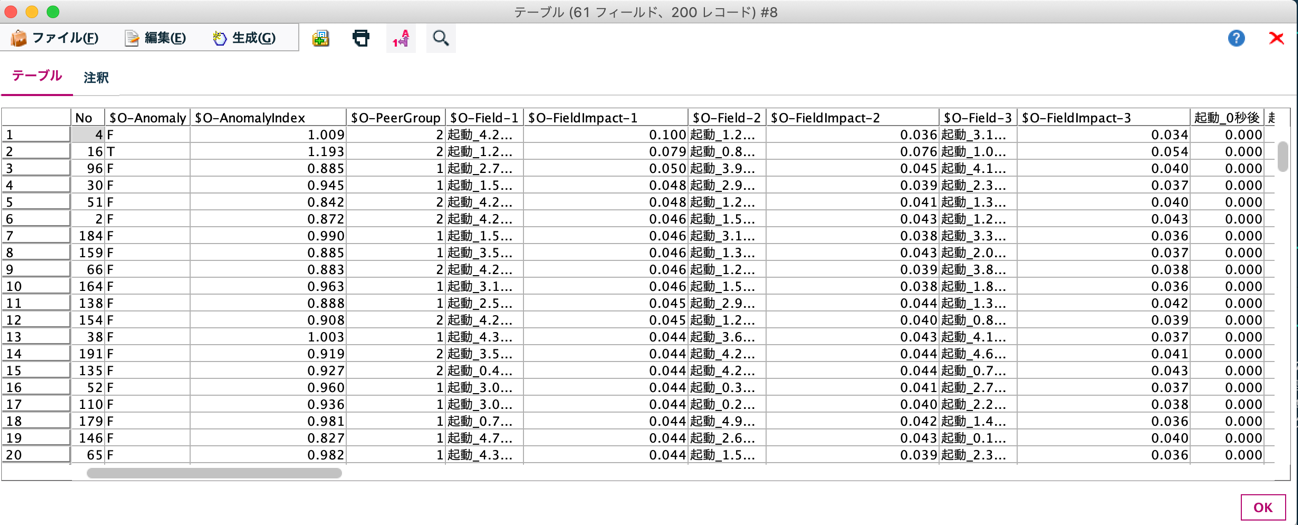
結果を見ると、No.4の扇風機は起動4.2秒後の値、No.16の扇風機は起動1.2秒後の値が特異である事を示しています。これは、時系列グラフを描くことでも発見できますが、異常値検査ノードでもその時点が、特異な値であることを示しており上手く異常データが抽出されています。この程度のデータであればグラフから異常データを特定することは可能ですが、扇風機が何万個もあり毎日稼働している様な状況下ではグラフを描き、人の目で異常データを抽出することは非効率であり、現実的ではありません。その点異常値検査ノードは、今回のように個体ごとの切り口で活用することもできれば、特徴量ごとの切り口で起動x.x秒後に特異が多いなど両方の観点から結果を有効に活用できます。
異常値検査ノードは教師なし学習の1つで、利用の目的は主に2つです。1つは、データ整備のために異常値を見つること、そしてもう1つは、異常検知のために異常値を見つけて理由を推測することです。
異常値検査ノードのアルゴリズムのステップは、1.モデリング、2.スコアリング、3.リーゾニング(理由付け)です。
1.モデリングでは、ケースの類似性に基づきクラスタグループを作成します。2.スコアリングでは、1.で作成したクラスタグループにケースを割り振り、すべてのケースの異常度を測定します。3.リーゾニングでは、2.の測定結果からケースが異常と特定された理由を異常指数の高い特徴量から推測します。
いかがでしょうか、もしかするとこれまで見逃していた異常値もしくは、もっと手間暇かけて探していた異常値が異常値検査ノードを利用することで効率よく発見できるかもしれません。
ぜひ、これからのデータ分析でお試しください。
次回推しノード#09はスマート・アナリティクスの畠様が「RFM集計ノード」について紹介してくださいます。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら
牧野 泰江
日本アイ・ビー・エム株式会社
東京ソフトウェア&システム開発研究所
データサイエンス&AIサービス

目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む

生成AIによるビジネス革新は、オープンなデータストア、フォーマット、エンジン、製品指向のデータファブリック、データ消費を根本的に改善するためのあらゆるレベルでのAIの導入によって促進されます。 2023 オープン・フォー ...続きを読む
IBM web domains
ibm.com, ibm.org, ibm-zcouncil.com, insights-on-business.com, jazz.net, mobilebusinessinsights.com, promontory.com, proveit.com, ptech.org, s81c.com, securityintelligence.com, skillsbuild.org, softlayer.com, storagecommunity.org, think-exchange.com, thoughtsoncloud.com, alphaevents.webcasts.com, ibm-cloud.github.io, ibmbigdatahub.com, bluemix.net, mybluemix.net, ibm.net, ibmcloud.com, galasa.dev, blueworkslive.com, swiss-quantum.ch, blueworkslive.com, cloudant.com, ibm.ie, ibm.fr, ibm.com.br, ibm.co, ibm.ca, community.watsonanalytics.com, datapower.com, skills.yourlearning.ibm.com, bluewolf.com, carbondesignsystem.com