
神子島 隆仁 氏
株式会社荏原製作所
技術・研究開発統括部
基盤技術研究部
データ科学研究課
2020年03月16日
カテゴリー Data Science and AI | IBM Data and AI | SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:
荏原製作所の神子島です。
「水と空気と環境の分野で優れた技術と最良のサービスを提供することにより、広く社会に貢献する」との企業理念のもと、当社では、機械や設備のメンテナンスコストを削減するための、故障予知技術の開発等に取り組んでいます。
日頃から私が研究開発に用いているSPSS Modelerの推しノード「データ検査」(総選挙3位!)の素晴らしさを、公開データ「自動車スペック」を使用してお伝えしたいと思います。
データマイニングの標準的なプロセスであるCRISP-DM (Cross-Industry Standard Process for Data Mining) は、「ビジネスの理解」、「データの理解」、「データの準備」、「モデルの作成」、「評価」、「展開」の各フェーズから構成されます。このうち、通常最も時間がかかるのは「データの準備」であり、その直前である「データの理解」において、分析対象のデータを十分に調べておくことが非常に重要です。
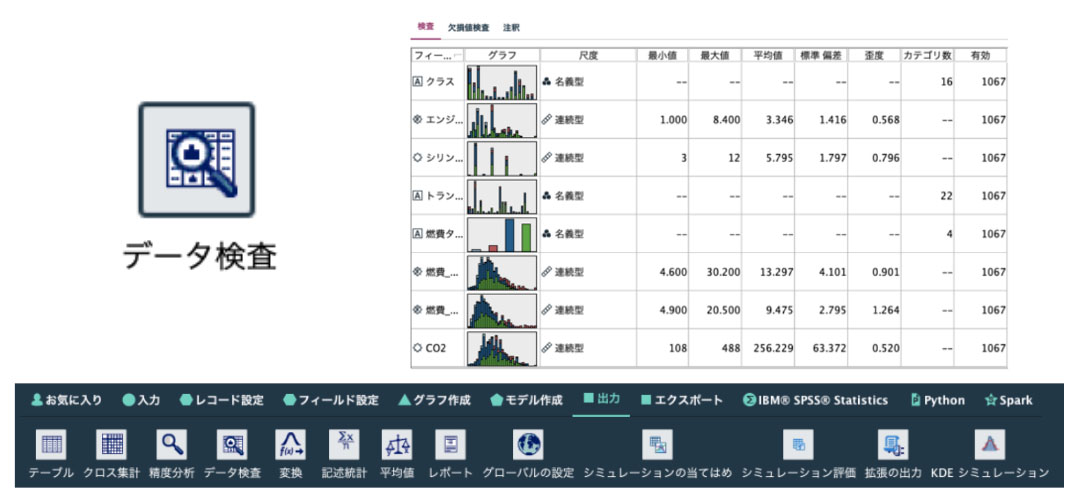
データ検査ノードは、IBM SPSS Modelerに取り込んだデータの特徴や品質を、直感的かつ効率的に把握することが可能な、とても便利なノードです。
データ検査ノードは、出力パレットに含まれています。入力ノードに接続し、実行するだけで、全てのフィールドを簡単に検査することが可能です。

検査結果には、各フィールドの分布がわかるグラフが含まれています。正規分布型かロングテール分布型かなど、分布の大まかな形を素早く直感的に把握することができます。さらに分布によっては変数のグルーピングや外れ値の処理を予めしておくべきかなどを判断する必要があります。
またグラフに続いて、連続型フィールドの場合は基本統計量(最小値、最大値、平均値、標準偏差、歪度など)、名義型またはフラグ型フィールドの場合はカテゴリ数などが表示されます。
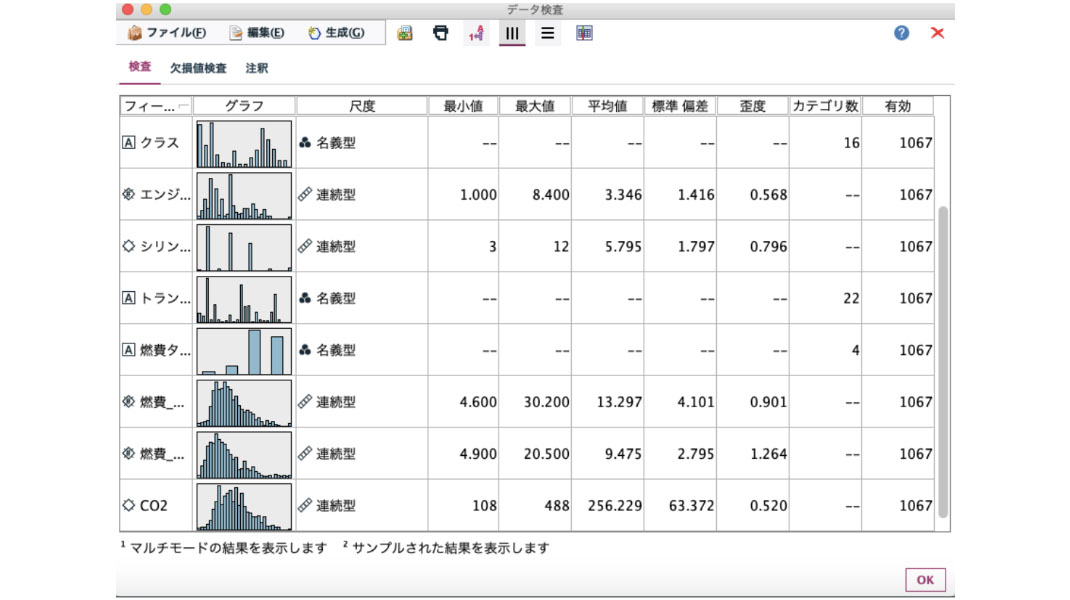
各サンプルグラフをダブルクリックすることにより、グラフを詳細に確認できます。
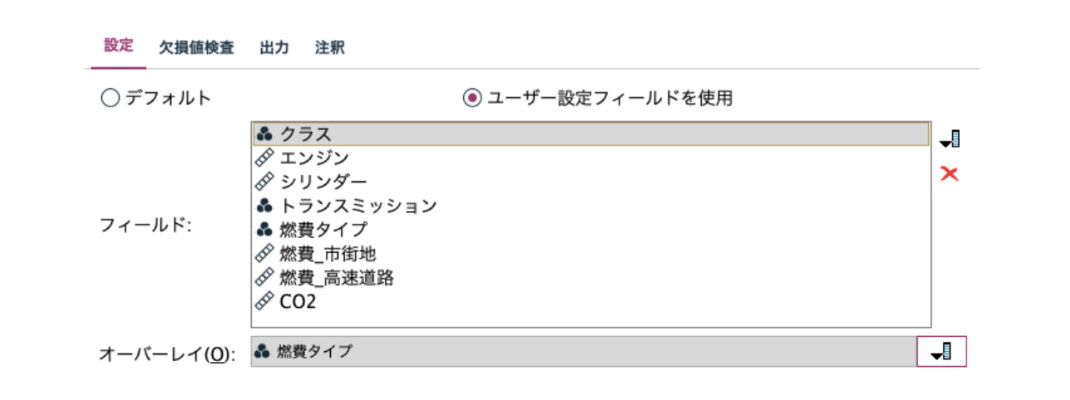
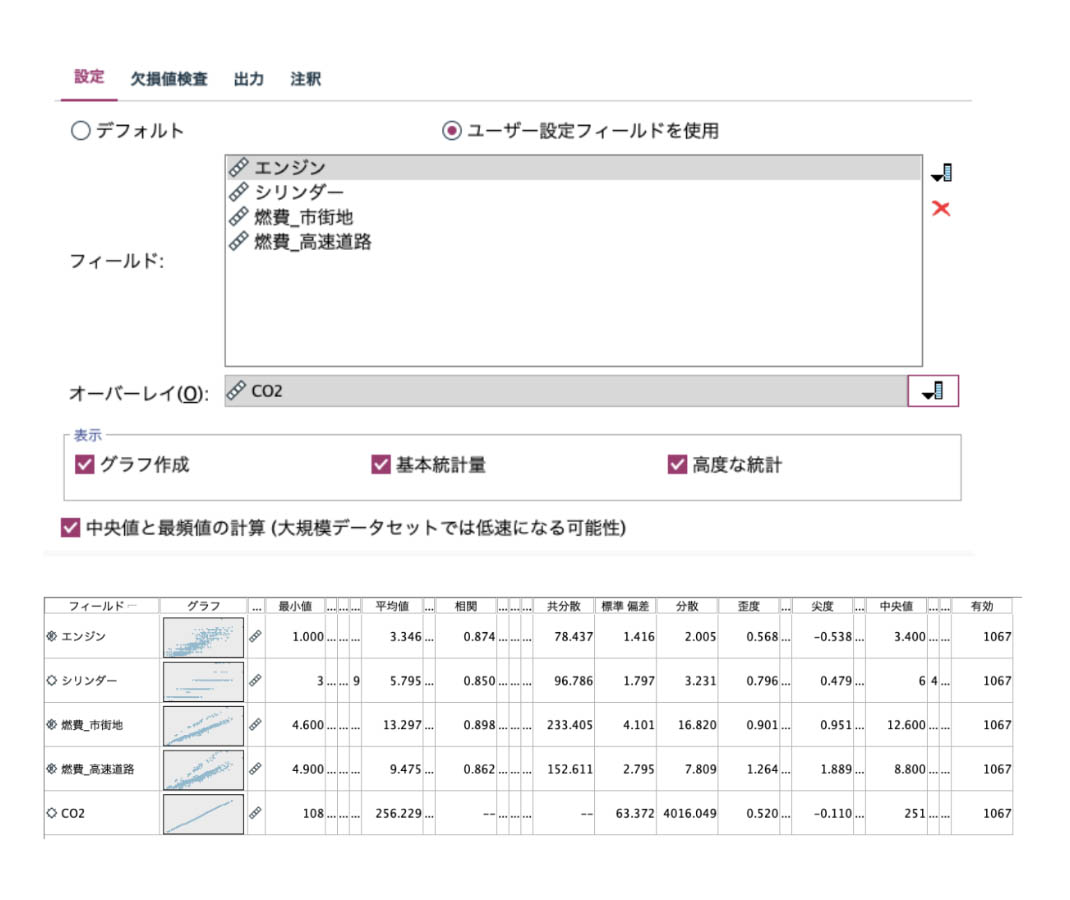
さらに次のように、設定画面で重要な変数をオーバーレイにすると他の変数との関係が明らかになります。この時点で特定の変数を予測材料としては役に立ちそうにもないと見切りをつける場合もあります。
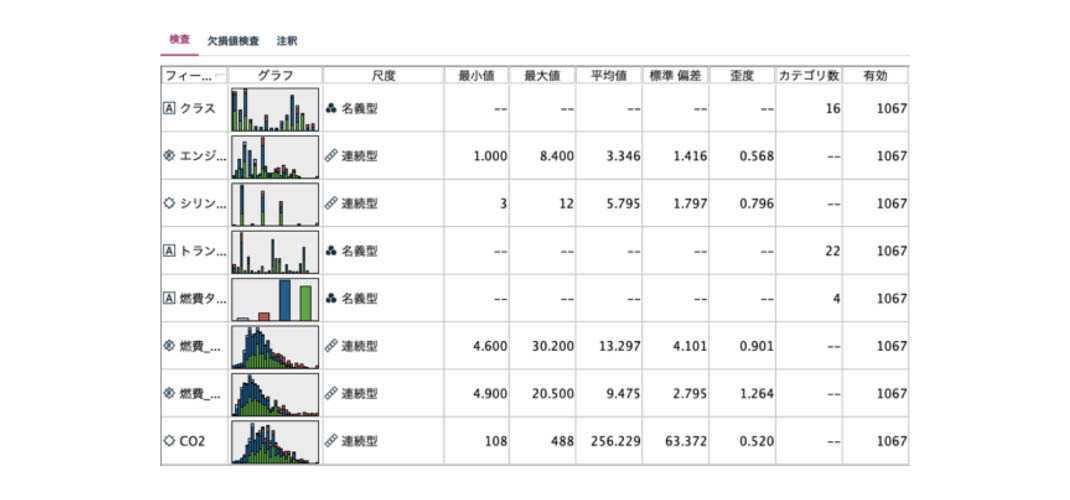
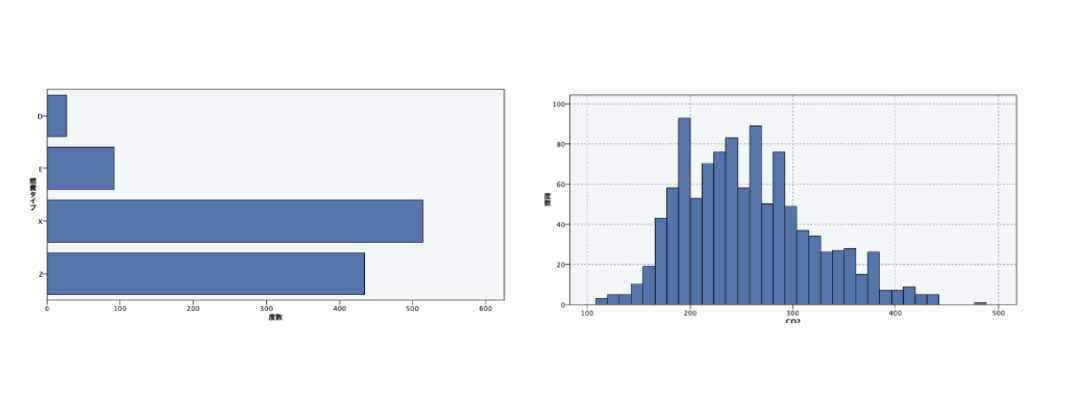
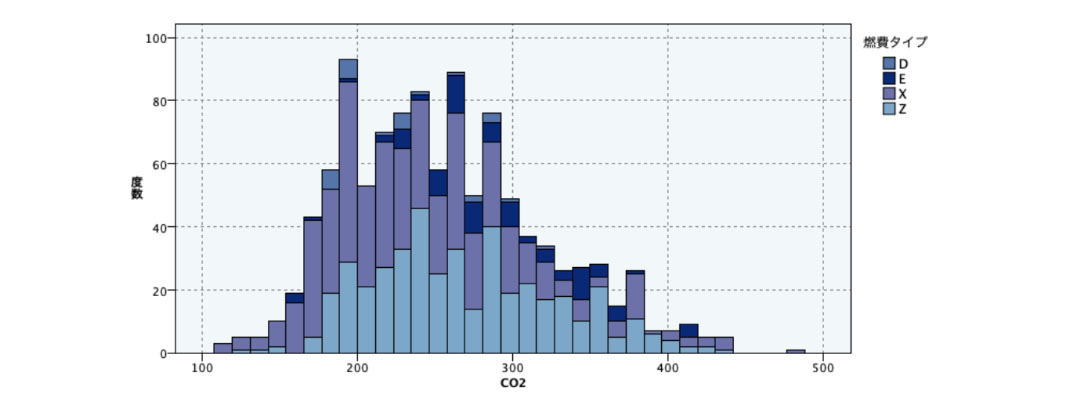
サンプルグラフの 1つをダブルクリックすると、詳細表示されます。ヒストグラムの配色が一様でないため燃費タイプとCO2は関係がありそうだと解釈できそうです。
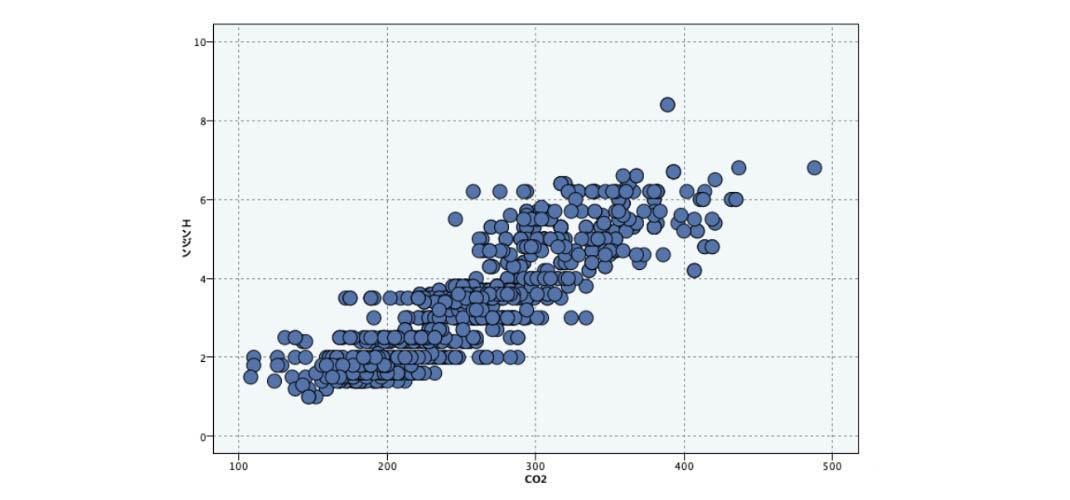
ここでオーバーレイを連続型にすると、他の数値データとの相関をグラフと値で判断できます。SPSS Modelerは散布図行列も相関行列も個別に出力できますが、説明変数の候補検討にはこの表示がとても役に立ちます。合わせて「高度な統計」のボックスをチェックした場合は、合計や集計範囲、尖度などが追加表示され、「中央値と最頻値を計算」のボックスをチェックした場合は、中央値や最頻値を確認できます。
サンプルグラフの 1つをダブルクリックすると、詳細表示されます。データが想定通りの挙動を示しているのか、仮説通りに進めて良さそうか解釈してゆくことができます。
データ検査ノードでは、外れ値や欠損値のチェックを行うことも可能です。設定は、欠損値検査タブで行います。
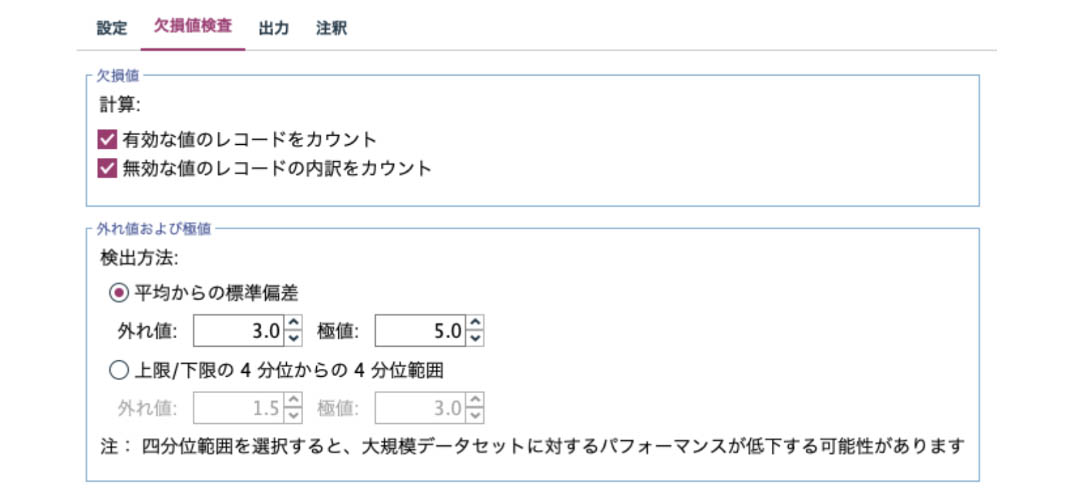
実行結果の欠損値検査タブに、外れ値や欠損値の数などが表示されます。
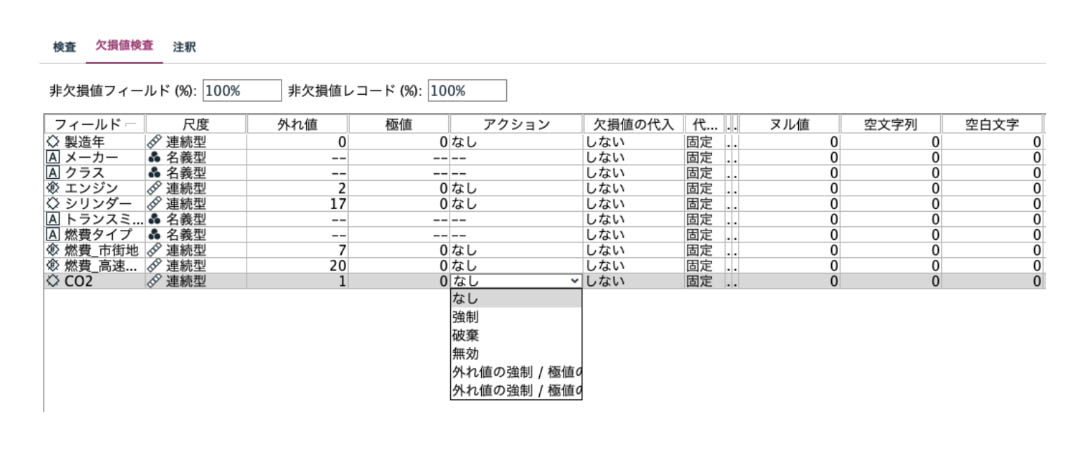
また、外れ値・欠損値を処理(フィールドやレコードの削除、代入など)のノードを生成することも可能です。つまり、検査するだけではなく、検査結果に基づいたアクションを途切れることなく実行できます。
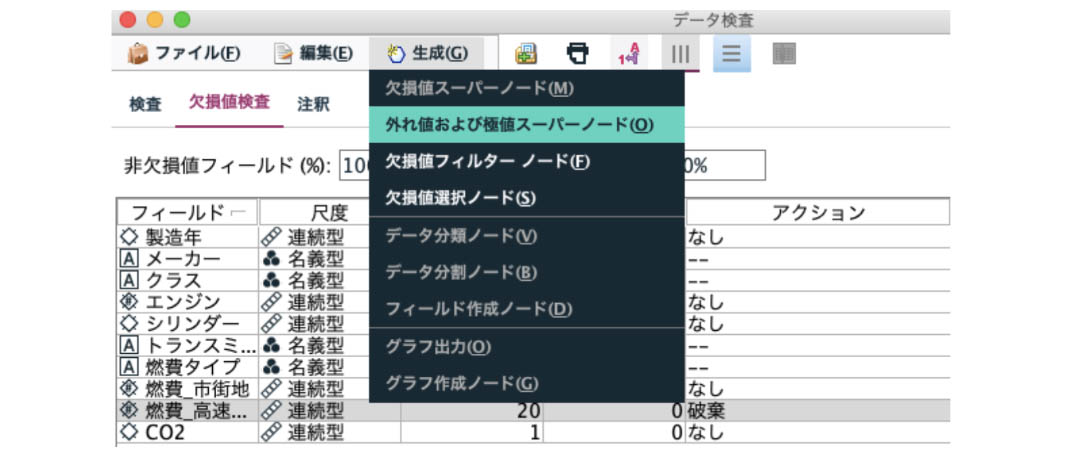
例えば「燃費_高速道路」のアクションを「破棄」として「外れ値および極値スーパーノード」の生成を行うと、以下のような星型のスーパーノードが自動生成されます。
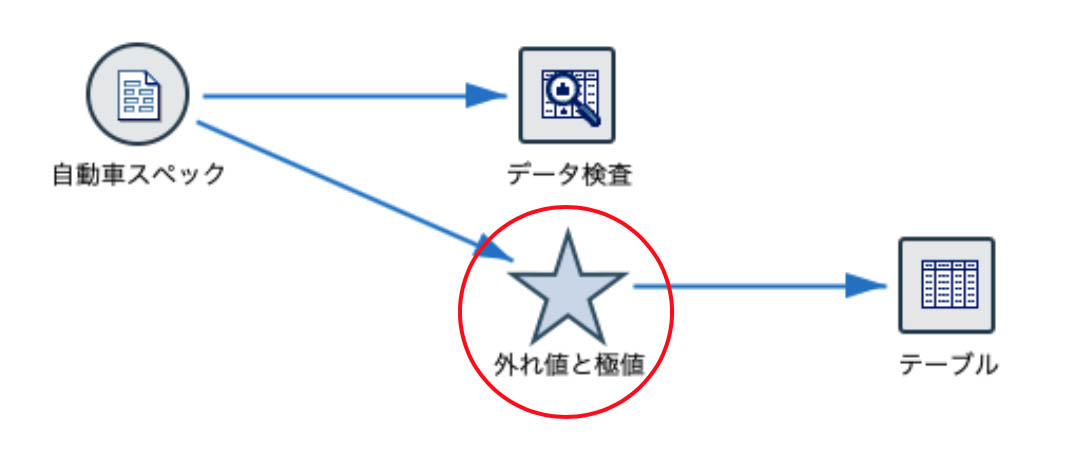
このスーパーノードを通過すると「燃費_高速道路」に存在した3σ(シグマ)より外側の20レコードが自動的に除去されます。グラフでは濃紺の部分です。
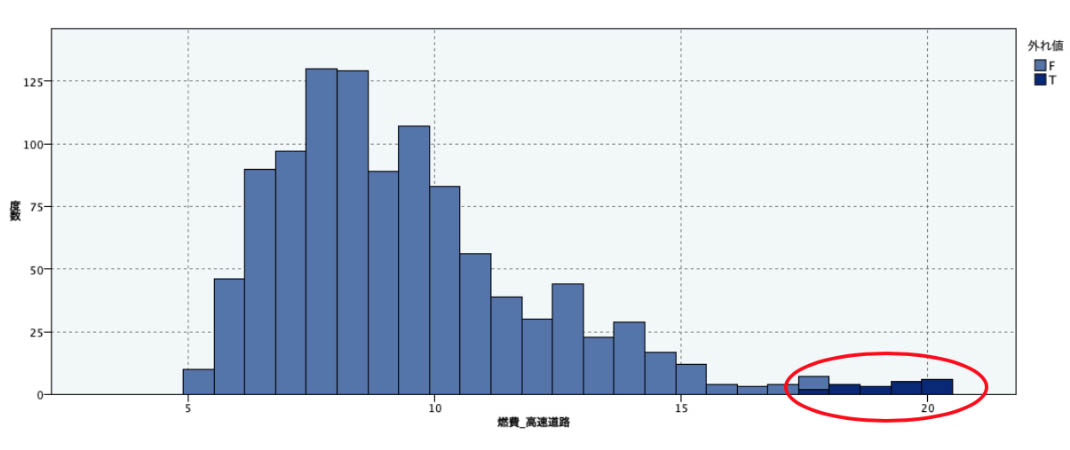
故障予知や異常検知などは、安易に外れ値を除去してはなりませんが、一般的な機械学習モデルでは異常値や空白データをきちんと処理することで精度や安定性が向上します。またIoTデータなどは通信状態から特定の時間帯が欠損して記録されることがあり、こういった空白の時間帯をどのように埋めるかが問われます。まずは手早く中央値や予測値を埋めるなどができるのはとても便利です。
データ分析の成否を左右する要因は多数ありますが、地味(?)で根気が必要な「データの理解」が不十分であったために、後で泣きを見た経験があるのは、私だけではないはず。統計量や分布、欠損値などを、直感的な操作で分かりやすく把握可能な「データ検査ノード」を利用し、面倒なデータの理解を一気に進める快感をぜひ味わってみてください。
なお、いわゆるビッグデータを対象として検査を行う場合は、計算に時間がかかるため、「データ検査ノード」の前にサンプリングノードを挿入し、レコード数を削減するなどの対策をお勧めします。
リレー連載次回推しノード#04はIBMのSPSSアーキテクト河田さんが再構成ノードを語ってくださいます!
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら
神子島 隆仁 氏
株式会社荏原製作所
技術・研究開発統括部
基盤技術研究部
データ科学研究課

皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む