SPSS Modeler ヒモトク
【リレー連載】わたしの推しノード –機械学習の多重奏。名指揮者「自動分類ノード」が織りなす至高のアンサンブル
2020年12月02日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:

はじめまして、株式会社AITの林と申します。
弊社はIBM製品の販売、導入、サポートを主な業務とするビジネスパートナーです。私個人に関しては、電子帳票、セキュリティ製品、不動産パッケージなどのソリューション担当を経て、現在はSPSS Modelerを中心にアナリティクス製品全般の技術担当マネージャーとして、SPSS等のソリューションの導入やデータ分析のお手伝いをさせていただいております。2020年9月に開催された Think Summit Japan では事例のご紹介もさせていただきました。
→レスキューナウ様における気象データを活用した停電予測検証について(動画)
さて本ブログでは事例の停電予測分析においても利用した「自動分類ノード」について取り上げます。このノードは、SPSS Modelerの紹介ではよく「オートメーション」と呼ばれている機能を持つノードの一つです。アルゴリズムの異なるモデルを複数作成して、比較・評価するための指標をユーザーに提示してくれるだけでなく、複数モデルを組み合わせたアンサンブル学習による予測も可能なのです。最近のAuto MLツールと同様のことが、SPSS Modelerでも一部可能なのです!!
※. 英語でアンサンブル(Ensemble)といえば重奏を意味しますが、機械学習においてのアンサンブル学習(Ensemble Learning)は、複数のモデルを組み合わせて1つの学習モデルとして生成することを意味しています。
自動◯◯ノードとは
データ分析を行っていると、「どのアルゴリズムを用いてモデルを作成するか?」という難問に必ず直面すると思います。
アルゴリズムに詳しい方からそうでない方までレベルは様々だということと、アルゴリズムに詳しくてもどんなアルゴリズム・パラメータを適用すると精度が高くなるかなどは、簡単には分からないからです。
そこで、登場するのが「自動◯◯」ノードになります。◯◯は、分類、数値、クラスタリングとなります。
・自動分類ノード

カテゴリーフィールド(yes/no、 churn/don’t churnなど) の予測に使われる異なるモデルを作成および比較し、指定された基準に基づいてモデルをランク付けします。
・自動数値ノード

数値フィールドの予測に使われる異なるモデルを作成および比較し、指定された基準に基づいてモデルをランク付けします。
・自動クラスタリングノード

同様の特性を持つレコードのグループを識別するクラスタリング・モデルを作成・比較します。クラスター・モデルの有用性をフィルタリングおよびランク付けする基本的な指標を使用します。
このように自動◯◯ノードは、複数のアルゴリズムでモデルを作成して、比較・ランク付けをしてくれます。分析目的別に3種類のノードが用意されていますが、今回は、自動分類ノードをピックアップします。
自動分類ノードで複数モデルを一度に作成
実際に自動分類ノードを使って分析モデルを作成してみます。今回使うデータは銀行のテレマーケティングデータです。銀行では、既存の顧客名簿に基づきコールセンターからアウトバウンドのテレマーケティングを行っています。実際の成約率を見てみると、yes(成約)の割合は11.71%です。
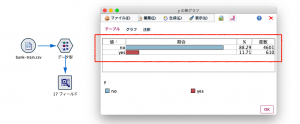
データからは、現在テレマーケティングにおいては、アプローチした顧客の11.71%しか成約していないことがわかります。
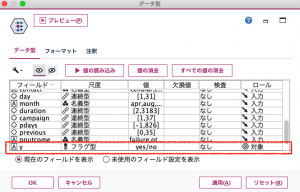
では、顧客の属性データを使って成約可否を予測して、それをテレマーケティングに活用することを想定してモデル作成に取り掛かります。まずはモデルを作るために、データ型ノードでは、成約可否フィールドの “ y “ を対象にして、その他属性情報を入力にします。
データ型ノードの後ろにデータ区分ノードをリンクして、70 : 30 で学習データとテストデータに分割します。
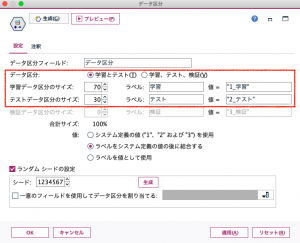
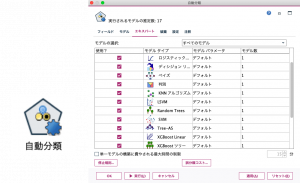
続いて、データ区分ノードから自動分類ノードへリンクして編集画面のモデルタブを確認します。モデルタブでは、モデルのランク付けの基準や、ランク上位のモデルを何番目まで作成するかを設定できます。今回は、以下のように設定します。
・モデルのランク付け基準 – 今回は「曲線下の領域(AUC)」にします。
・使用モデル数 – 今回はデフォルトの「5」のままとします。
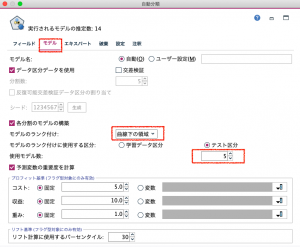
エキスパートタブを開きます。デフォルトでは14種類のモデルが選択されています。ここでは、モデルの選択数は変えずに、ロジスティック回帰モデルのモデルパラメータをデフォルトから変更してみます。
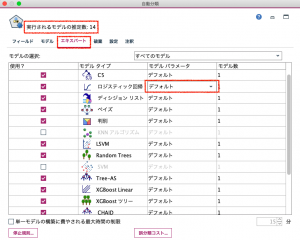
ロジスティック回帰のモデルパラメータで「指定」を選択して、多項式メソッドの項目で、強制投入法(デフォルト)とステップワイズ法を選択します。
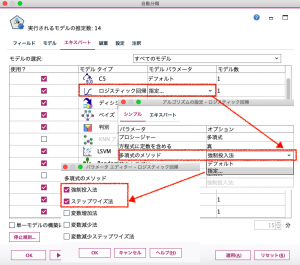
モデルパラメータの設定が完了すると、ロジスティック回帰のモデルパラメータが「指定」、モデル数が「2」となります。ロジスティック回帰に関しては、強制投入法とステップワイズ法、それぞれのモデルを1つずつ作成するということになります。また、画面上部の実行されるモデルの推定数が「15」になっています。
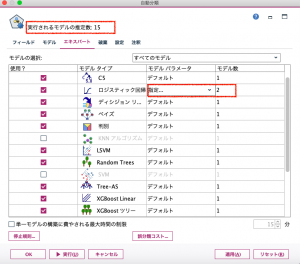
次に、破棄タブを見てみます。このタブではモデルの作成基準を設定できます。今回は設定を変更しません。
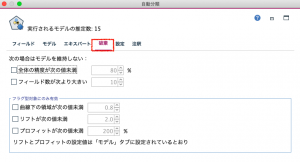
続いて設定タブを確認します。ここでは、複数モデルを組み合わせたアンサンブルモデルを作成した際にどのような方法で予測を算出するのかを設定できます。今回は以下のように設定し実行します。
・アンサンブル法には、票決を選択します。(yes / no 多く予測された方を採用)
・票決が同数の場合は、最高確信度を選択します。(2対2など同数の場合は、最高確信度が高い方を採用)
実行完了を待ちます。
モデル作成結果を確認しよう
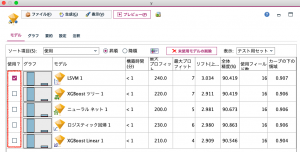
出来上がったモデルナゲットを確認します。カーブの下の領域(AUC)でソートすると、一等賞は、LSVMとなりました。そのほかは、画面の通りとなります。ロジスティック回帰は強制投入法を使ったモデルが選ばれています。(ちなみに、ロジスティック回帰のステップワイズ採用モデルは第6位でした。)
このように複数モデルを一度に作成・評価して提示してくれる、とても便利なノードだということがわかると思います。
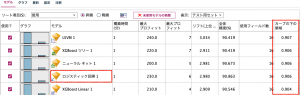
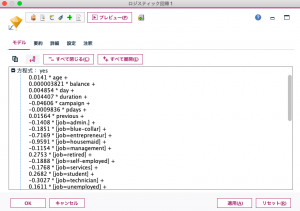
もちろん、それぞれのモデルの内容も参照したいモデル列をダブルクリックすることで確認できます。下記画面は、ロジスティック回帰のモデルの内容になります。
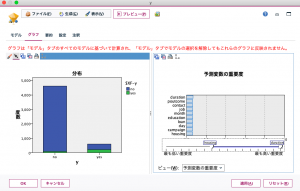
グラフタブを開くと、アンサンブルによる予測結果や変数の重要度が確認できます。
モデルの精度を比較・確認する
出来上がったモデルの精度を精度分析ノードで確認します。今回は、LSVMと5つのモデルを組み合わせたアンサンブルモデルの精度を確認・比較してみます。
ますは、LSVMから確認します。
モデルの一覧の一番左の使用?列にあるチェックをLSVMのみにします。
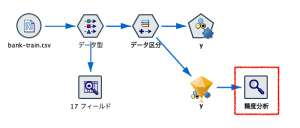
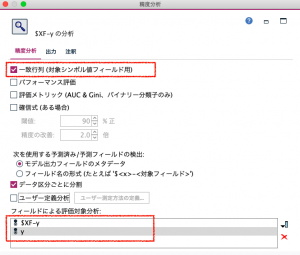
モデルナゲットから精度分析ノードへリンクして編集画面を開きます。
・一致行列にチェックします。
・フィールドによる評価対象分析に予測値$XF-yと実測値yを指定して、実行します。
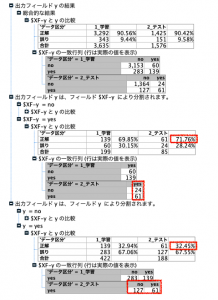
精度を確認します。適合率を確認すると、テストデータでは約71.8% ( 61/85 ) となり、実際の業務での成約率11.71%より大きく向上していることがわかります。ただ、再現率は、約32.5%( 61/188 )と全成約者の1/3にしかリーチできていません。まだ、変数の追加や特徴量の作成が必要みたいですね。
つづいてアンサンブルモデルの精度を確認します。
自動分類モデルナゲットを開き、モデルの一覧の一番左の使用?列を5つのモデルでアンサンブル学習させるように、すべてチェックします。
そして、精度分析ノードを再度、実行します。
適合率を確認すると、テストデータで約73.7 % ( 70/95 ) となり、LSVM単独の精度より改善しています。再現率も、約37.2%( 70/188 )であり、こちらも改善していることが確認できます。少しですが、アンサンブル学習させたことによる成果がでました。

おまけでアンサンブルノード
実は、自動分類ノードでなくても複数モデルでアンサンブル学習させることができます。それが、アンサンブルノードです。下記のようにモデルを直列にリンクして、その先にアンサンブルノードをリンクします。(モデルは自動分類モデルナゲットより生成して利用しています。)
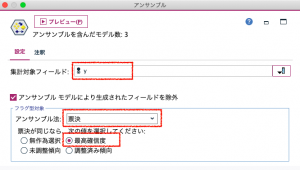
アンサンブルノードで集計対象フィールド、アンサンブル法などを指定します。今回は、自動分類ノードの設定と同様にします。
最後に精度分析ノードをリンクして実行すれば結果が確認できます。3つのモデルによるアンサンブルの適合率は約72.2%( 70/ 97 )、再現率は約37.2%( 70/188 )となりました。こちらも、LSVM単独より精度が改善したことが確認できます。

まとめ
いかかでしたか。自動分類ノードは、精度の高いモデルを提示してくれるだけでなく、有力な複数モデルを組み合わせたアンサンブル学習を利用することで、さらなる精度向上を目指します。個々の楽器(モデル)を組み合わせて調和させる、さしずめ名指揮者といったところでしょうか。
アンサンブル学習は Driverless AIやAuto AIなどのAuto MLツールでも採用されている手法です。Auto MLツールは複数モデルをアンサンブルするだけでなく、各種パラメータの自動チューニング、特徴量の自動生成など+αの機能も実装されていますので一概にSPSS Modelerのアンサンブル学習と比較はできませんが、特徴量の生成(SPSSはデータ加工の機能が充実しています)やパラメータの設定は分析者が今までの知見や経験で設定・作成することで精度向上が期待できる場合もありますので、予測精度が思うように改善しない等、お悩みのユーザーの方は、一度自動分類(自動数値、自動クラスタリング)ノードを活用してみてはいかがでしょうか?もちろんアンサンブルノードもおすすめですよ。
さて次回は日本アイ・ビー・エム 京田さんによる本リレー連載のエピローグとなります。ここまで23回にわたり「推しノード」をご紹介してまいりましたが、感動のフィナーレもぜひご覧いただけますようお願い申し上げます。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら

林 啓一郎
株式会社AIT
開発事業本部 ソリューション戦略第2部 次長

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む