

























SPSS Modeler ヒモトク
【リレー連載】わたしの推しノード – 一流エージェント「拡張ノード」。必要なタレントは外から連れてくれば良い!
2020年11月24日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:

日本アイ・ビー・エムの千代田です。
SPSS Modelerは製品が提供するノード(部品)をドラッグ&ドロップで組み合わせ、簡単な設定でさまざまなデータ加工・分析をすることができますが、場合によっては既存のノードでは実現できないケースもあります。そのような場合に、拡張ノードを使用するとSPSSの処理に独自の実装を組み込み、さまざまな要件に対応できるようになります。今回は拡張ノードを使用するための設定方法と具体的な使い道をご紹介します。
拡張ノードとは?
拡張ノードはRまたはPythonでユーザー独自のスクリプトを記述することで、各言語が持つ豊富な機能をSPSSの処理に組み込むことができます。具体的には以下のようなノードが提供されており、必要な処理を実装していくことになります。

拡張ノードでPythonを使用する
SPSS Modeler 18.2.1以前の拡張ノードではPython2しかサポートしていませんでしたが、18.2.2からPython3がサポートされるようになり、Python3を前提とするライブラリが活用できるようになりました。SPSS Modeler 18.2.2をインストールするとPython 3.7.7の環境が含まれていますが、任意のライブラリを導入した独自の環境を使用することも可能です。例えば私の環境(macOS 10.15.4、SPSS Modeler 18.2.2)では、以下のように設定することで個別にインストールしたPython環境を拡張ノードで使用可能です。
Pythonのインストール
Pythonの構築方法はいろいろあるのでここでは詳しくは触れませんが、私はpyenvでインストールしています。

Python環境の指定
SPSS Modelerの構成ファイル(/Applications/IBM/SPSS/Modeler/18.2.2/SPSSModeler.app/Contents/config/options.cfg)で使用したいPython環境を指定します。

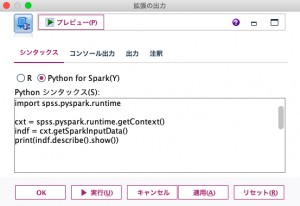
例えば、拡張の出力ノードを使用するとPySpark DataFrameのdescribe() メソッドで各カラムの統計量を表示することができます。

拡張ノードで日本語テキスト分析を行う
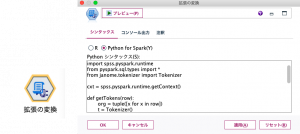
拡張ノードの使い道はいろいろありますが、一例として日本語のテキスト分析は多くのお客様で求められています。現行のSPSS Modelerの標準のノードでは日本語のテキスト分析の機能は提供されていませんが、Pythonのライブラリを使用することで従来の構造化データの分析に加え、非構造化データであるテキストの分析までSPSS Modelerの活用の領域を広げることができます。ここでは日本語の形態素解析ライブラリであるJanomeを使用したテキスト分析をご紹介します。 先ほどSPSS Modelerで使用するために指定したPython環境にJanomeをインストールします。

ストリームは以下のように構成します。
サンプルの入力データとして、ユーザーによる製品レビューが日本語テキストで記述されたものと、各ユーザーの属性情報が保持されたものを使用します。

「拡張の変換」ノードでは「レビュー」列の日本語テキストをJanomeで形態素解析するためのPythonスクリプトを記述します。
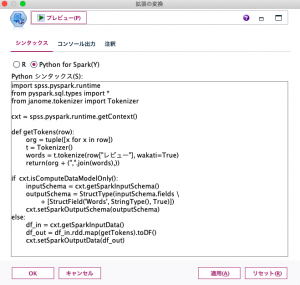
このスクリプトにより、「レビュー」列を形態素解析した結果が「Words」列に出力されます。

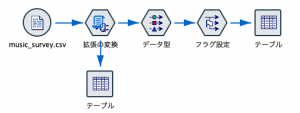
SPSS Modelerの既存の機能と組み合わせるとさまざまな分析に応用することができます。次の例では「フラグ設定」ノードと組み合わせて、単語の有無をフラグ化してみます。ストリームは以下のように構成します。
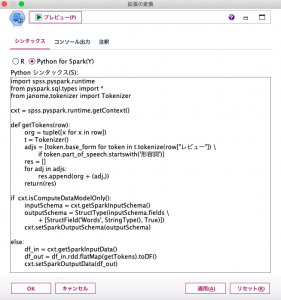
入力は先ほどと同じデータになります。「拡張の変換」ノードではJanomeで形態素解析した上で、各レビューに含まれる形容詞を特定して「Words」列に縦持ちしています。

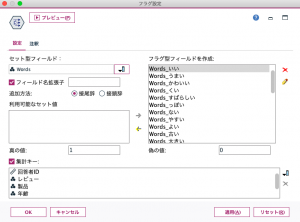
後続の「データ型」ノードで「値の読み込み」を実行した上で、「フラグ設定」ノードでフラグ化のための設定を行います。
最終的な出力は以下のように、各レビューに対して、形容詞の有無をフラグ化して出力されました。

まとめ
必要なタレント(能力)を外から連れてきて仕事をしてもらうー流エージェント「拡張ノード」いかがでしたか?
SPSS Modelerは製品自身で豊富な機能を有しており、さまざまなデータ分析のニーズに応えることができるものですが、拡張ノードを活用するとPython、Rの機能も組み込み、非構造化データの分析等、より広範な要件に対応できるようになります。今回はPythonで日本語テキスト分析にフォーカスしてご紹介しましたが、アイディア次第でその可能性はより広くなっていくと考えられます。ぜひ一度拡張ノードを試してみていただき、活用のアイディアを考えてみていただければと思います。
なおSPSS Modelerで、すぐにテキスト分析を始めるためのストリームテンプレートがSmart Analytics様より2020年11月から提供されています。以下のサイトでご確認ください。
→テキストマイニングを実現する「DSTAS for SPSS Modeler」の詳細はこちら
次回推しノード#23は、AITの林様に自動分類ノード編を寄稿いただきます。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら

千代田 真吾
日本アイ・ビー・エム株式会社
クラウド&コグニティブ・ソフトウェア事業本部
Data and AI事業部
データサイエンス&AI テクニカルセールス

Women in Data Science Tokyo @ IBM 2024 開催レポート
Data Science and AI, IBM Data and AI
こんにちは。IBM西戸です。 今年で5回目のWomen in Data Science (WiDS) Tokyo @ IBM が2024年6月14日に初の会場とオンラインのハイブリッド開催されました。会場は2024年2月 ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(後編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 前編での法務・AI ...続きを読む

法務・AIリスクのスペシャリスト三保友賀が語る「ダイバーシティー」 | インサイド・PwDA+7(前編)
Data Science and AI, IBM Sustainability Software
日本IBMにて法務、特にAI倫理・リスクのスペシャリストとして、そして同時にLGBTQ+コミュニティー*1やPwDAコミュニティー*2のアライとして積極的に活動している三保友賀さんにお話を伺いました。 <もくじ> 企業内 ...続きを読む