SPSS Modeler ヒモトク
【リレー連載】わたしの推しノード –リスク博士「シミュレーションノード」がシナリオ別に示す臆病と強気の境界線
2020年11月16日
カテゴリー IBM Data and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:

こんにちは三井住友海上火災の木田です。
三井住友海上で損害保険の統計データを活用した新規ビジネス開発や 取引先企業のリスク低減を目的としたデータ分析コンサルティングを担当しています。 このたびデータ分析人材について書籍を出版致しましたので、ご興味があればぜひお手にとっていただくと幸いです。
→データ分析人材になる。目指すは「ビジネストランスレーター」(日経BP)はこちら
損害保険会社ではリスクの定量化が重要な要素となり、数々のシミュレーションを行います。 このブログではModelerに搭載されているシミュレーションの3つのノードが、とてもパワフルでリスク査定のみならず、ビジネスチャンスを見極めるのにも利用できる点について紹介します。 データもシナリオも全て架空ですので私どもの業務とは一切関係がないのですが、わかりやすい例を題材にしましたので、イメージを膨らませて読んでいただけると嬉しいです。
シミュレーションとは
現実に実験を行うことが難しい物事について、想定する場面を再現したモデルを用いて分析することをシミュレーションといいます。代表的なシミュレーションの方法にはモンテカルロシミュレーションがあります。
モンテカルロシミュレーションは、モンテカルロ法または多重確率シミュレーションとしても知られており、不確実な事象の起こりうる結果を推定するために使用される数学的手法です。第二次世界大戦中にジョン・フォン・ノイマンとスタニスワフ・ウラムによって発明され、モデリングアプローチがルーレットに似ていることから、モナコ公国のカジノ街にちなんでその名がついたそうです。ギャンブルでは運営者側はリスクを分析し一方、お金をかける人はチャンスを見出すのに?利用できるかもしれないですね。
実はSPSS Modelerでモンテカルロシミュレーションができるとご存知ないユーザーも多いのですがバージョン16で搭載されてから簡単に実行できるようになっています。
シミュレーションノードとその使い方
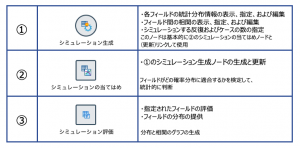
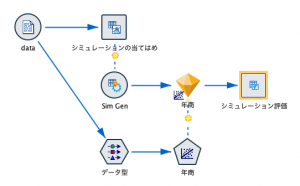
シミュレーション関連のノードには、①シミュレーション生成ノード、②シミュレーションの当てはめノード、③シミュレーション評価ノードの3つがあります。それぞれの役割は以下の通りです。
利用するデータのイメージは次の通りです。各ケースに既存ストアの年商とエリア情報が記されています。

このデータ構造なら、Modelerユーザーなら次の瞬間に年商を推測する数値予測モデルを作成、候補物件のエリア情報から年商の推測が可能でしょう。今回は、出店開発そのものではなく、このチェーンストア事業の経営者の気持ちで課題をモンテカルロシミュレーションで解決します。
事業開始以来、現在100店舗ほどチェーン展開してきましたが、時折、出店後、即撤退の不振店や、逆に想定以上の大ブレイク店がしばしば作られ、あと5年同じような立地に1000店、出店し続けても事業全体で利益が出せるのか・・・というのが課題です。
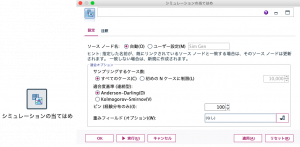
まずは、対象となるデータに②のシミュレーションの当てはめノードをリンクします。このノードで、対象データ内のフィールドがどの確率分布に適合するか検定を行います。
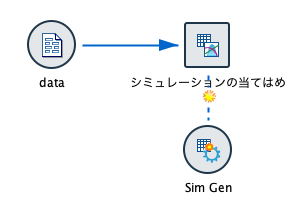
すると、Sim Genという名前の①のシミュレーション生成ノードが生成されます。つまり、①シミュレーション生成ノードは、②シミュレーションの当てはめノードのアウトプットになります。 そして同時に、②が100,000ケース(デフォルト)にデータを膨らませた、シミュレーションの入力ノードになるのです。あまり普通ではない展開ですよね。
シミュレーション生成ノード(デフォルト名:Sim Gen)を参照すると元のデータと統計的に最も適合した確率分布やパラメータが、フィールドごとにリストで表示されます。たとえば、年商や店内面積、・・・、人口(30歳代)男、人口(30歳代)女などのフィールドは、対数正規分布に最も適合していることがわかります。フィールドがどの確率分布に適合しているのかを知ることができるので、分布に適したモデリング手法を見極める目的で使用することもできます。
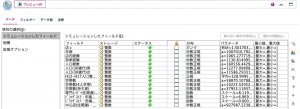
自動的に適合された分布に基づいてこの後、データを膨らませるのですが、分布を分析者の意図で変更することも可能です。
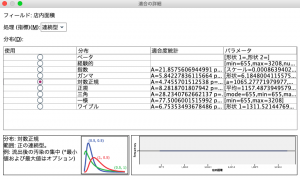
データをどの程度まで増やしてゆくかはシミュレーションするケース数に従います。
そして、各フィールドの分布を維持するだけではなく、フィールド間の相関を考慮してデータを増やします。相関を維持できるので、作られた架空の店舗エリアに、男性ばかり住んでいて、女性が住んでいないということはありません。なるべく現実的にあり得るデータを作ります。分布と同じく、この局面で相関係数を意図的に変更することが可能です。

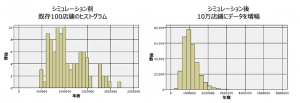
オリジナルのデータがシミュレーションで膨らませるとどうなるのかヒストグラムで確認してみます。
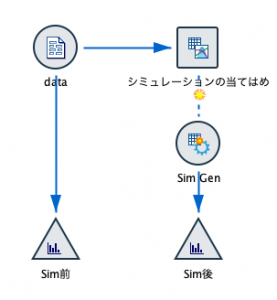
左がオリジナル。100ケースとあって分布がいびつです。右は適合した分布に従って増やした100,000ケースなので滑らかなカーブを描いています。このヒストグラムだけでも、今後の事業計画の参考になりそうです。
ただ、SPSS Modelerユーザーの皆様であれば、100の年商データの単純な分布の当てはめよりも別の方法を検討するのではないでしょうか?例えば説明変数データを分布と相関を維持してシミュレーションにより増幅、それに予測モデルを当てはめるのは良いアイデアです。 実際にやってみましょう。 既存100店舗のデータで年商を予測する回帰モデルを作成して、シミュレーションデータにリンク。最後は冒頭に紹介した③シミュレーション評価ノードを使います。
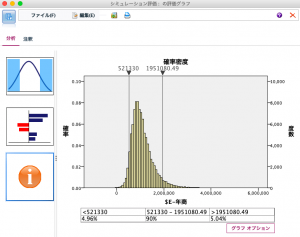
シミュレーション評価ノードの結果は次の通りです。確率密度が示され、100,000店舗出店した場合の9割がどの幅に入るか分かります。
シナリオ別にリスクを評価する
さて、ここからが、シミュレーションノードが「博士」と称されるゆえん。本領を発揮します。
自分達の意思決定で、将来のリスクやチャンスがどうなるのかを評価したくなりますよね?例えば、今後店舗のお客様駐車場を何台(15台・45台・60台)でセットするとどうなるのか。ビルインテナント・路面店・駅ナカ店のどれかに出店を集中させるとどうなるか。まずは収益ベースで単純に比較するだけでも価値があります。
では、もう一度、出来上がったストリームの①Sim Genを編集します。
ここでは非現実的な例で恐縮ですが、年商の予測モデルにおいて、30歳代男性の人口が3種類(たとえば500、20000、50000人)の場合、それ以外の条件は同じだとすると年商はどのようになるかを調べます。 そこで次に、シミュレーション生成ノードのフィールドで人口(30歳代)男の分布を対数正規から固定に変更し、パラメータにシミュレーションして比較したい値(500、20000、50000)をセットします。
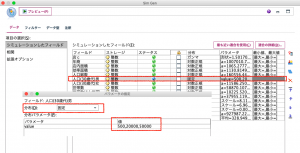
項目の選択(S):の拡張オプションを選択すると、パラメータで設定した種類の反復回数が表示されています。今回は3種類の値をセットしたので、反復回数は3となっています。この後、3種類をシミュレーションして比較したいので反復フィールドの作成にチェックを入れてIterationフィールドを作成します。Iterationフィールドは、3種類のパターンを識別するフィールドです。
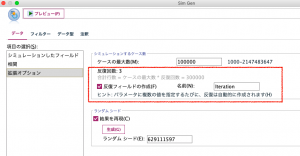
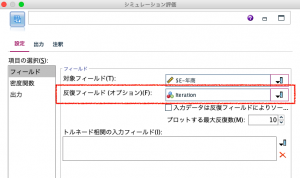
さらにシミュレーション評価ノードでは、人口(30歳代)男の分布を固定し、3種類の値をセットしたのでそれらを比較しやすいようにグラフを作成してみます。反復対象フィールド(オプション)(F):にIterationをセットします。
シミュレーション評価ノードを実行するとグラフが表示できます。30歳代男性の人口が、青:500、緑:20000、黄:50000の場合です。
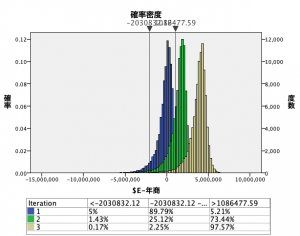
青:500と緑:20000だと予測した年商にマイナスが見られますが、黄:50000になるとマイナスになることはなくなっています。この予測モデルでは、年商をプラスにキープするには30歳代男性の人口が50000人必要ということになります。 (くどいですが、年商がマイナス、30代男性の数500は全てフィクションです。)
まとめ
サンプルが少ない事象でも、意思決定によって将来どのような分散になるかをシナリオ別に示せるのが、このノードの凄いところです。 例えば大手商社は原料を輸入してビジネスされますが、為替レートをいくつかのパターンで設定しながらリスクをコントロールし利益の幅を想定します。これに利用されるのがモンテカルロシミュレーションです。 ぜひお使いになっていない方がいらしたらチャレンジしてみください。
おまけ
2020年11月現在、鬼を退治する漫画が大流行。そのキャラのシールが入ったチョコレート菓子が手に入らないとニュースになっています。2009年頃同僚の呼びかけで、当時復刻した元祖キャラシール入りチョコ菓子を恵比寿のコンビニで毎日大人買いしたのを覚えています。良い大人が仲間とキャラ43種類コンプリートするのは楽勝だという考えが間違いと気づいたのは37種類のキャラが集まった頃です。買っても買ってもキャラの重複ばかりで、先の見えない戦いに仲間の苛立ちは募り、目的はキャラのシールなので、不要なチョコレートだけを受け取る周辺の社員からも非難が出始めた矢先に「SPSS Modelerでシミュレーションしてあと幾らで終わるか幅で推定しよう」と誰かが言い出しました。結局予測通りの結末を迎えました。 その時に計算した結果は以下です。
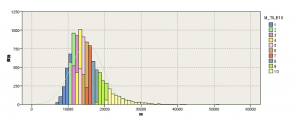
総額3万円の可能性は薄いですが2万円はこのチョコ菓子に予算が必要だったと気づかされる1枚です。この内容はその年のSPSS イベントで事例として利用されました。生活の中でもリスクは計算するべきだと思い知らされた瞬間です。
リレー連載次回推しノード#22はIBM千代田さんが拡張ノードを語って下さいます。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら

木田 浩理
三井住友海上火災保険株式会社
デジタル戦略部
プリンシパルデータサイエンティスト

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

敷居もコストも低い! ふくろう販売管理システムがBIダッシュボード機能搭載
IBM Data and AI, IBM Partner Ecosystem
目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

テクノロジーが向かう先とは〜中長期テクノロジー・ロードマップ
IBM Cloud Blog, IBM Data and AI
IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む