SPSS Modeler ヒモトク
【リレー連載】わたしの推しノード –似た者探しの名人「KNNノード」(最近傍法)が気づかぬ隣人を言い当てる!
2020年10月03日
カテゴリー IBM Data and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:

株式会社ADKマーケティング・ソリューションズの田口仁です。
2019年に株式会社アサツーディ・ケイが4社に分割し、現在は前述の会社に在籍。得意先の広告コミュニケーション活動計画を立案するためのマーケティングデータベースの開発や同データを活用した分析手法の開発、各種の効果予測モデルの構築等を担当しています。2000年にModeler(当時の名称はClementine)を導入し、今年で20年目を迎えます。暫くModelerを利用していないと、その操作に戸惑うことも多々ありますが、バージョンアップの度に、データ加工が簡単にできる機能や機械学習の手法が追加されたりすると、有難いと感じます。今回はモデル作成パレットの中から、業務でも何度か利用したことのあるKNNを紹介します。
KNN(K-Nearest Neighbor Algorithm)とは?
KNNは、k近傍法、最近傍法、最近隣法と様々な訳語があります。ニアレスト・ネイバーですので、最もよく似た隣人を探す手法と考えると分かりやすいかもしれません。 機械学習の分野で日々新しいアルゴリズムが作り出される昨今、KNNはもはや古典的な手法の一つと言えるでしょう。ただ、その中身は直感的に理解しやすい上、回帰分析とクラス分類の両方の課題にも適用できます。マーケティングデータを分析する業務があると、まずは試してみる推しノードの一つです。
特徴空間上において「対象◯」と「対象⬜︎」が存在し、ここに未知の「対象△」がいずれのクラスに属するか、という課題があったとします。その際、△に最も近い位置にある対象をK個選択します(図1)。Kを3に設定すると、△から最も近い距離にある3つの対象は◯が2つで⬜︎が1つ。多数決の結果、未知の対象△は◯のクラスに属すると判定します。Kを5とした場合、△から最も近い距離にある5つの対象は◯が2つで⬜︎が3つとなるので、△は⬜︎のクラスに属すると判定します。
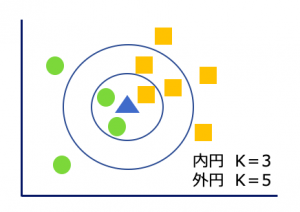
図1
KNNは図2のモデル作成パレットの中にあります。

図2
Modeler上のKNNノードについて実際にデータを使って紹介します。19項目の設問の回答パターンによって、対象者の(ある意識価値観に関する)タイプをAからGの7つのクラスに分類する課題になります。諸事情により、データの内容等詳細については割愛します。ご容赦下さい。
■説明変数:Q1_newからQ19 _new
■目的変数:class(AからGの7クラス)
元データの形式の都合上、データ型ノードやフィルタノードなどを使って加工(図3)し、表1のテーブルにしてからKNNノードに繋げています。IDは対象者番号です。

図3

表1
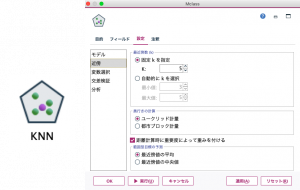
KNNには4つのタブ(目的・フィールド・設定・注釈)があります(図4)。
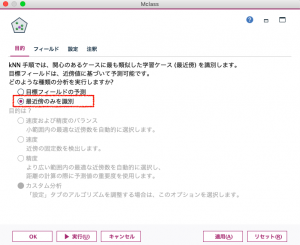
図4
始めに【目的】タブにおいて、「目標フィールドの予測」か「最近傍のみを識別」のいずれかを選択します。 「最近傍のみを識別」を選択した場合、後述する【設定】タブでKの値と距離の算出方法を選択します。接尾語にneighborとある出力結果変数は、そのIDと最も近い距離(=回答パターンが似ている)に存在するIDを示します。接尾語にdistanceと表示されている変数は、前述の距離の値を表します。 $KNN-neighbor-1はそのID本人を示しており、距離を表す$KNN-distance-1の値は0になります。表2で言えば、ID_4337番さんは(本人を除いて)ID_4619番さんと最も距離が近く、ID_1980番さんがそれに続きます。 ModelerではKNNノードを実行後に得られたモデルノードを右クリックするとグラフが表示されます(図5)。
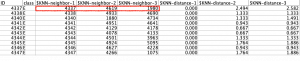
表2
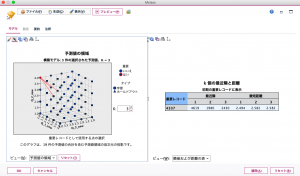
図5
前述の図4の【目的】タブで「目標フィールドの予測」を選択すると、4種類の「目的」のいずれかを選ぶことになります。本例では図4でカスタム分析を選択しています。 【フィールド】タブでは、目標(目的変数)と入力(説明変数)を設定します。Q1_newからQ19 _new の19項目の回答データを入力欄に、classを目標欄に入力します。(図6)。
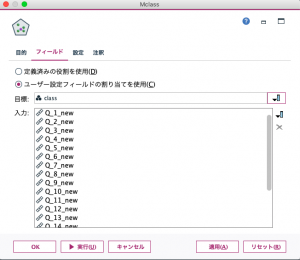
図 6
【設定】タブではモデル、近傍、変数選択、交差検証、分析の5つのサブメニューがあります。 近傍メニューでは、Kの値(固定値もしくは範囲を選択)と、対象との距離(ユークリッドと都市ブロック(=マンハッタン距離))などを設定します。本例ではK=5で固定し、距離はユークリッドを選択しています。説明変数の重要度によって重みを付けて距離を計算する機能もあり、今回はそれにもチェックを入れています(図7)。
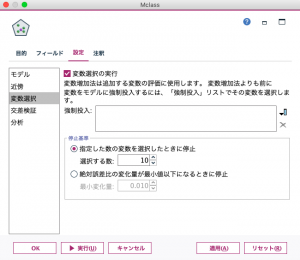
図7
変数選択メニューには、今回の課題であるクラス分類において重要と見なされる説明変数を自動的に選ぶ機能(変数選択の実行)があります。今回は19項目の説明変数から10個の重要(と見なされる)な説明変数を抽出したら、それを使ってKNNを実行し、計算を停止させる設定にします(図8a)。 計算が終了した後に作成されたKNNモデルのアイコンを右クリックすれば、抽出された10個の説明変数とその重要度が表示されます。今回の例ではQ_8_newの重要度が最も高いことがわかります(図8b)。
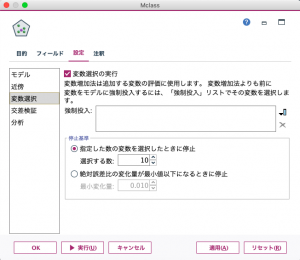
図8a
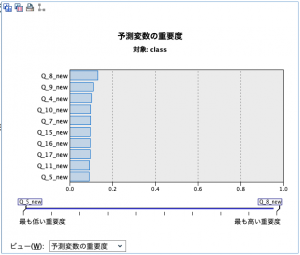
図8b
分析メニューでは、各ケース(本例ではID)と近い距離にあるケースと、その距離を結果テーブルに出力する設定を行うことができます(図9)。
図9
全ての設定を完了し、KNNノードを実行した後のテーブルが表3になります。$KNN-classが、予測されたclassに該当します。
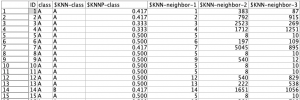
表3
KNNモデルアイコンをクリックしてレコード(※本例でいうIDのこと)を選択し、その結果を確認してみましょう。例えばID4004番とユークリッド距離が近い順での上位5名のIDは{1660番、4879番、5056番、4170番、4646番}となりました。同5名の実際のclassはそれぞれ{B、E、E、E、E}となっており、ID4004番は多数決の結果、$KNN-classでEと判定されています。参考までに、実際のID4004番のclassもEでした(図10)。

図10
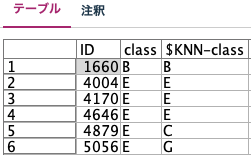
表5
表6は行に各IDの実際のclassを、列にKNNを実行して判定した予測classを置いたクロス集計の結果です。対角線上の値が実際のclassと予測のclassが一致していることを示します。classAでは90.1%、classBでは84.5%、classCでは84.6%が実際のclassと予測のclassが一致しています。 今回の設定で実行したKNNで構築したモデルが実務において満足できる精度と判断したら、同モデルを使って未知の対象のclassを識別します。
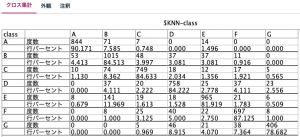
表6
まとめ
私の推しノード、KNNはいかがでしたでしょうか。 例えばKNNはマーケティング領域で、お菓子メーカーが新しい商品をリリースする前に市場のどの商品と競合する(つまり「最近傍」なの)か、ライバルを把握し自社の販売戦略を考えるために利用することができます。他にも不正検知に応用したり、設備の不具合事象の分類など様々な目的で用いられています。
実際に弊社では過去に性格診断のサイトを制作する際に、大規模なデータをModeler上にある色々な機械学習アルゴリズムを試行し、最終的に性格タイプの判定手法としてKNNを採用したこともあります。 冒頭で言及した通り、機械学習の新しいアルゴリズムが続々と誕生する状況においても、個人的にはまだまだKNNの名人芸に助けられるのではないかと考えています。
リレー連載次回の推しノード#18はIBM小林竜巳さんがベイズノードを語って下さいます。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら

田口 仁
株式会社ADKマーケティング・ソリューションズ
統合チャネル戦略センター プランニングディレクター

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

敷居もコストも低い! ふくろう販売管理システムがBIダッシュボード機能搭載
IBM Data and AI, IBM Partner Ecosystem
目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

テクノロジーが向かう先とは〜中長期テクノロジー・ロードマップ
IBM Cloud Blog, IBM Data and AI
IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む