

























SPSS Modeler ヒモトク
【リレー連載】わたしの推しノード –SQL魔法使い「データベースノード」がとどめの呪文で運用処理速度を向上
2020年09月22日
カテゴリー SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:

日本IBMシステムズ・エンジニアリング(ISE)の水谷です。
データサイエンティストとしてお客様のデータ活用をお手伝いしています。特に最近ではデザインシンキングを取り入れたDX推進オファリングの提案も行っています。このブログでは私が過去にお客様のデータ分析基盤を構築する際に実際に直面したパフォーマンス課題とデータベースノードによる解決策を紹介します。
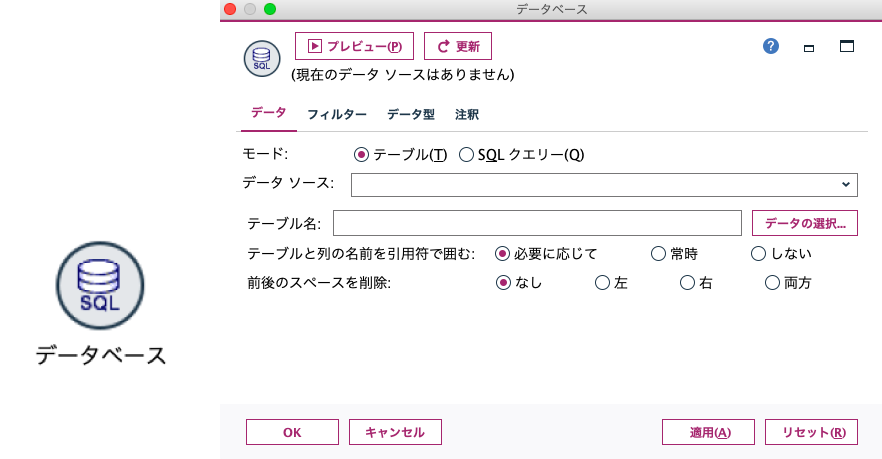
データベースノードとは?
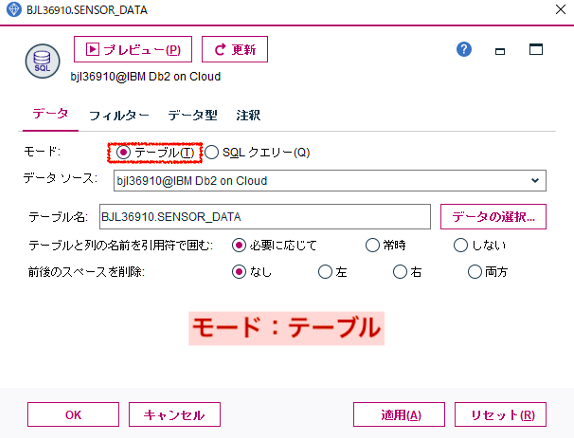
「データベースノード」は入力するデータがデータベースの時に使うノードです。設定項目はいたってシンプル。2つのモードを選択でき、デフォルトは「テーブル」です。こちらは入力としてデータソースの他にデータベースのテーブル名を指定して完了。データソースは予めODBC登録をしておけばOKです。
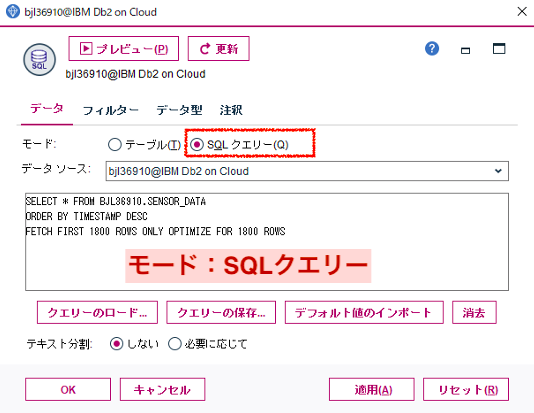
もう一つは「SQLクエリー」です。「SQLクエリー」を選択するとデータソースの指定の下のダイアログボックスにSQL文を記述できます。SQLが得意な方でしたら、複数のテーブルを結合し必要な行や列だけ読み込むなどをこの1つノードで指定できてしまいます。ただし複雑なSQLを張り切って書くとノードアイコンによる可読性を損ない、別の業務担当者が判読できないリスクもあるので注意します。
データベースノードの出番は?
実は私の経験上SPSS Modelerを用いたデータ分析試行プロジェクトでは対象データが大規模すぎて途方に暮れることはまずありません。むしろ入力データセットは限られたサイズのCSVファイルで始まります。このようなフェーズではデータベースノードはベンチ入りのまま温存されますが、データ量が多いときや、データ分析基盤を構築して、本番運用になるとこのノードの出番になります。
特に業務に実装される運用フェーズでは制約時間内に処理を完了させる必要があり、ストリーム処理を少しでも(1秒でも)短縮したいために様々な工夫が要求されます。例えば毎分ごとにスコアリングして、予測結果を業務で利用する場合、ストリーム処理だけで1分近くかかっていたのでは運用が回りません。そのようなケースでは、前後のデータ処理を踏まえて、1分以内といわず、なんとかして、ストリーム処理をスピードアップさせる必要があります。
SQLプッシュバック
SPSS Modelerでパフォーマンスの話題となれば、真っ先に泣く子も黙るSQLプッシュバックが挙げられます。SQLプッシュバックとは、「データベースノード」に接続されたストリームに含まれる多くの加工処理を自動的にSQL化して、データベース側で高速に処理することです。この機能の威力は絶大です。ノードさえ並べられれば、SQLをご存知ない方でも結果的に最適なSQL処理ができるとあって、多くのユーザーに高く評価されてます。複雑なストリームを一瞬でSQLに変身させる様子はさながら、「魔法使い」のようです。
つい数年前までModeler Serverの機能として限定されていたSQLプッシュバックは現在はModeler Clientで使用可能となっています。読者の中で、「実は利用したことがない」という方がいらっしゃったらぜひ、この魔法を体験ください。1億件を超えるクラウドのデータを、ローカルのストリームから3秒で加工処理できるのは圧巻です。
SQLプッシュバックが有効なデータベースはこちらから確認できます
さて、そんなSQLプッシュバックですが、これさえ使っていればパフォーマンスは万全かというと、そういうわけではありません。特定の条件下では、SQLプッシュバックが期待通り働かない場合もあるのです。
パフォーマンス改善のとどめのSQL
ここから実際にDb2環境でデータベースノードを使ってパフォーマンス改善をした実プロジェクト例に照らして説明します。
■想定運用ケース:
まず、以下のような予測の運用ケースを想定します。入力はSENSOR_DATAという名前のテーブルで、1レコードあたり1秒のセンサーデータです。
予測は1分に1回実行され、その度にストリームが実行されます。ストリームは最新30分間(1,800レコード)のデータを使って特徴量(説明変数)を作成し、モデルでスコアリングされます。処理の流れは、以下の通りです:
【予測用ストリームの処理ステップ】
- タイムスタンプ列(”TIMESTAMP”)で降順ソート
- 上から1,800レコードをサンプリングで最新データのみ取得
- 特徴量を作成
- モデルに投入して予測結果を表示
※この検証は以下の環境で実施しました:
- IBM Cloud上のDb2にテーブル(フィールド数:50、レコード数:40,000)を作成
- ローカルPCのSPSS Modeler Client 18.2.1から上記DBにODBC接続をしてストリームを実行
【ケース1】デフォルトのままストリームで実装
ステップのうち加工の前処理に相当する①と②を、それぞれソートノード、サンプリングノードで実装しています。実行中のストリームのイメージは以下のとおりです。

紫色のノードは、SQLプッシュバックの対象となっている処理です。ここでお気付きかと思いますが、サンプリングノードが紫色になりませんでした。つまり、処理ステップのうち②がSQLプッシュバックの範囲外となっています。
実行されたSQLのログからSQLプッシュバックによって生成・実行されたSQL文(抜粋)を確認してみましょう。

やはり、サンプリングノードの処理内容(②)が含まれていないことがわかります。
ところで、ここでストリームの作り方を少し変更して、サンプリングノードの前のソートノードを除外してみます。すると、サンプリングノードの処理が紫色になり、SQLプッシュバックに含まれました。

再度、SQLのログで確認します。”FETCH FIRST 1800 ROWS ONLY”という記述がそれに相当する個所です。サンプリングノードそのものがSQL化できないわけではないとわかります。

本来最新のデータだけ1800行を取得して、降順ソート + サンプリングの両方にSQLプッシュバックが効いて欲しいと期待します。しかし、この場合サンプリングでSQLが有効にならず、後続処理でローカルのリソースを利用してしまいパフォーマンスが得られません。
かなり長いストリームの全てのノードが紫色に変化してSQLプッシュバックの恩恵を受けることも多い一方で、今回のケースのように自動生成されるSQL文では、限界を感じる場合もあります。あいにく、どれだけストリームのノード配置を工夫しても、加工処理をSQL化する自由度には制限があるというのが現実です。
【ケース2】SQLクエリーを選択して加工処理をSQL文で実装
SQLプッシュバックの対象となる加工処理を明確に指定するために、①と②の処理内容を、データベースノードにSQL文で記述しています。
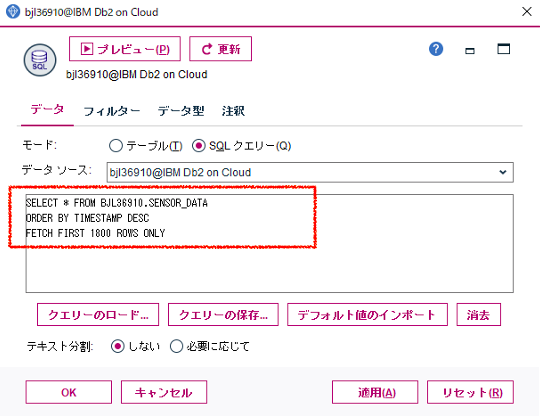
SQLクエリーとして記述したSQL文(赤字が①と②の処理)は以下のとおり。

ストリームの実行イメージは以下のようになります。データベース入力ノードが紫色になり、SQLプッシュバックの対象となっていることがわかります。

【ケース3】SQLクエリーを選択して+αのチューニングを実装
最後に、データベース入力ノードを使った+αのチューニング例です。これによってパフォーマンス改善の最後の一押しを実現します。
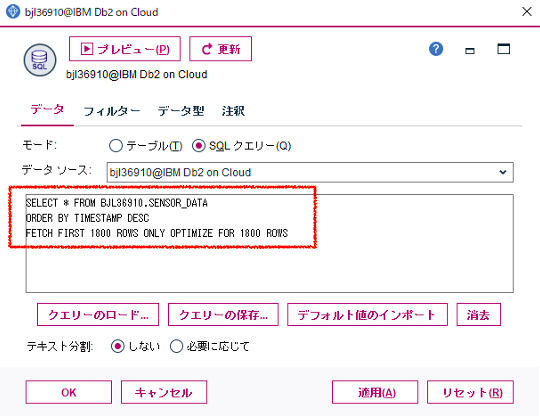
SQLクエリーとして記述したSQL文(赤字が+αのチューニング個所)は以下のとおり。

データベースの知識に基づくパフォーマンス・チューニングが実装されました。OPTIMIZE FOR n ROWSを追加することで、結果セット全体ではなく、最初の少数の行しか取り出さないことを考慮したアクセスプランが選択されています。その結果、ストリームの処理時間を短縮できるという効果が狙えます。
■処理時間の比較
3つのケースの処理実行の計測結果は以下のとおりです。狙い通りの結果となりました。今回の条件ではケース1とケース2にさほど差が出ませんでしたが、それでもETL処理のSQLプッシュバックの適用範囲が広い分、ケース2が高速になりました。ケース3は、ケース1と比較して安定して2秒程度処理が速く、+αのチューニングの効果が見て取れます。

まとめ
いかがでしたでしょうか?分析環境を運用実装するにあたりストリームの処理時間を少しでも切り詰めたい場合データベースノードにSQLクエリーを記述することで突破口を開いてくれます。参考にしていただけますと幸いです。
次回推しノード#17はADKマーケティング・ソリューションズ田口様からKNNをご紹介いただきます。
【参考情報】
FETCH FIRST N ROWS ONLY 節と共に OPTIMIZE FOR N ROWS 節を使用する
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら

水谷 好伸
日本アイ・ビー・エム システムズ・エンジニアリング株式会社
アナリティクス・ソリューション

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む
データ分析者達の教訓 #21- 異常検知には異常を識別する「データと対象への理解」が必要
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの宮園です。IBM Data&AIでデータサイエンスTech Salesをしています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、デー ...続きを読む

【予約開始】「SPSS秋のユーザーイベント2024」が11月27日にオンサイト開催
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
本年6月800名を超える方々にオンライン参加いただいたSPSS春のユーザーイベントに続き、『秋のSPSSユーザーイベント』を11月27日に雅叙園東京ホテルにて現地開催する運びとなりました。 このイベントは ...続きを読む