SPSS Modeler ヒモトク
【リレー連載】わたしの推しノード –フィールドのマエショリスト「置換ノード」が魅せる凄ワザと関数@FIELDの威力
2020年09月06日
カテゴリー Data Science and AI | IBM Data and AI | SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:

福岡大学の太宰です。 大学の講義でSPSS Modelerを使ってデータ分析(決定木分析やクラスター分析等)を教えています。 もう10年以上も前になりますが、私自身が大学院生だった頃、IBMに統合される前のSPSS社で数年間インターンをしていました。当時Clementineと呼ばれたModelerで数多くの企業のデータに触れた経験が今の私の武器になっています。ですので、今回リレー連載の執筆のお話をいたいただいた時には恩返しの気持ちもあって、迷わずお引き受けいたしました。今回私が推すのは、予測モデルの出来を左右するデータ加工の要、「置換ノード」。「@FIELD」等々を使うと効果的にデータの前処理をすることができます。私が頼りにしている「マエショリスト」の凄ワザを紹介いたします。
置換ノードとは?
置換ノードとは、IBM社ホームページによりますと「フィールド値の置換やストレージの変更に使用されます。」とあります。値を変えたり、データ型の変換(質的⇔量的、文字列⇔数字、整数⇔小数、null置換 etc.)に使われることが多かろうと思います。
値を置換したい!(しかも複数の変数の。)
早速「値を変える」例として、(リッカート尺度など)「順序尺度の逆転」をしてみます。(のっけからビッグデータの例じゃないですが…) 顧客へのアンケートなどとして、「1=非常にそう思う~5=全くそう思わない」といった数字の1から5で取得を何変数か取得する、といったことはしばしばあると思います。このとき「非常にそう思う」のほうを「5」にして解釈したい!と言うことが結構あります。数字が多いほう=強く思う、当てはまる、としたほうが解釈しやすいからです。1から5の数字を逆転したいのですから、「6から引く」で、1は5に、4は2に、といった具合で逆転できます。 こんな感じのデータの置換、ということです。
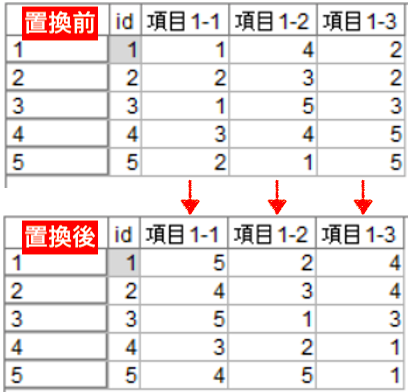
もちろんExcelでも簡単に加工はできるのですが、いちいちローデータを手で触るのも面倒な場合もあるのでは、と。そんなとき、置換ノードひとつですぐ逆転できます。
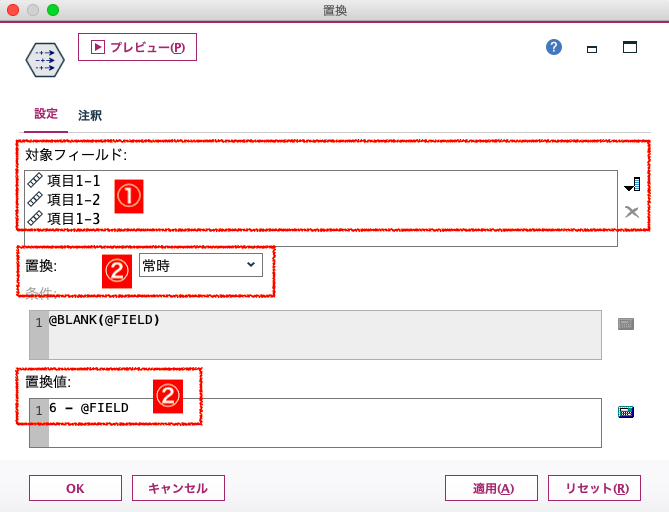
①:逆転させたいリッカート尺度を選択 ②:特に置換の条件はないので「常時」 ③:置換値の欄に、「 6 – @FIELD 」と記す 先頭に「@」がある関数は特殊関数と言われ、「@FIELD」は、簡単に言うと「フィールド名の代入」です。上の置換ノードでは項目の1-1, 1-2, 1-3の3変数を指定しているので、その3変数の値が対象となります。 このように、置換をするときは変数が複数であることも多く、結構「@FIELD」を併せて用いることが多いのです。
「型」の変換
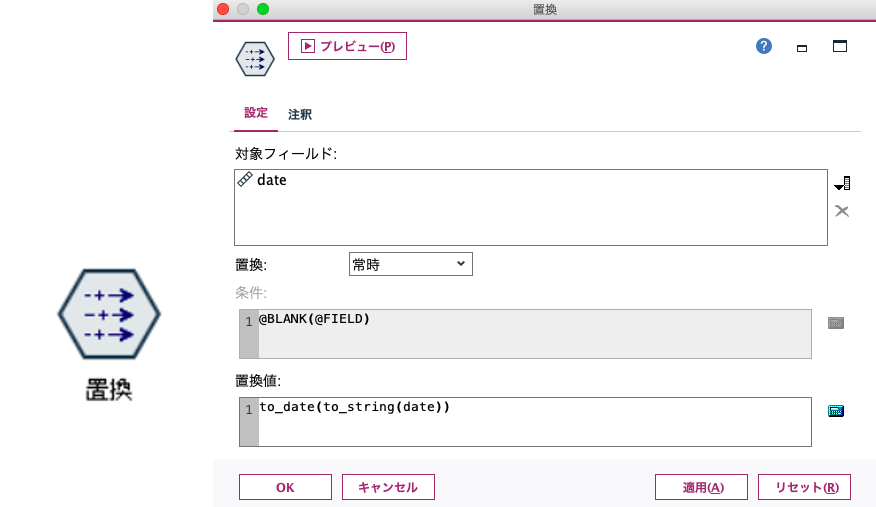
置換ノードは、上のような値の置換のほかに、「型変換」でもよく用います。このように「yyyymmdd」で日付を表す整数が入っていたとします。
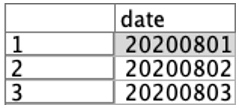
これをもちろん日付にしたいのですが、この数字のままでは「二千二十万八百一」(笑)とかになってしまいますので、「日付型」にするために、「to_date」という関数を用いて型変換を行います。
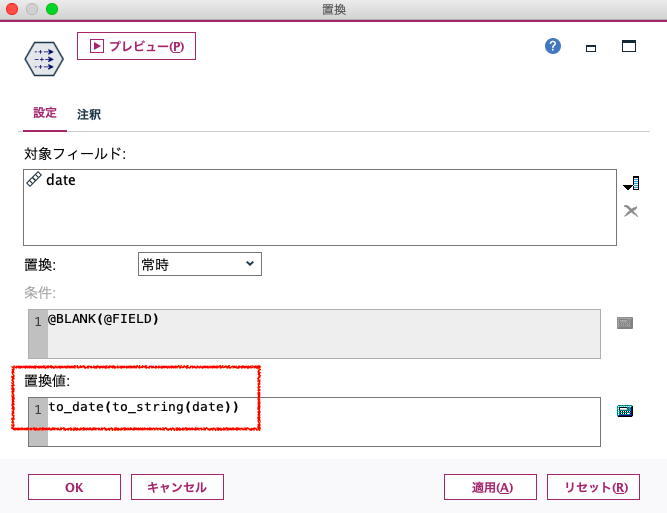
関数「to_date」は、続くカッコ内で指定する変数が「文字列、タイムスタンプ、日付」のどれかになっている必要がある(つまり整数のままだとエラーになる)ため、いったん「to_string」で文字列化し、それを「to_date」で日付に変換しています。入れ子になっていますが、このページの読者なら大丈夫でしょう! この置換ノードを通したあとは、ハイフンが年・月・日の間に入る形となって日付型になり、データ型でみても「フィールド」の欄がカレンダーのアイコンになっています。
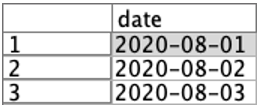

このように、文字列、日付や時刻、整数や小数(float)などの型変換を行うときに、置換ノードをよく用いるのです。
null置換と、欠損の扱い
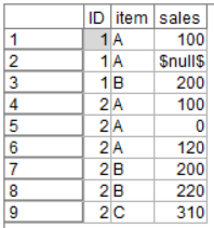
ビッグデータを扱うにあたって、いろいろなテーブルや変数をjoinしたりunionしたり、という場合について困るのが欠損値の扱い、です。例えばこんなごく簡単な、AさんとBさんによる商品AとBの購買があったとします。Aさんの2行目の売り上げが欠損していますね。
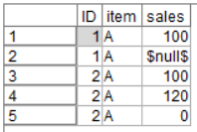
置換ノードで、欠損をゼロに置き換えるのであれば、こんな感じですぐ、です。対象のフィールドには「sales」、置換を「ヌル値」とし、置換値を「0」とします。これで欠損していたところにはゼロが入ります。
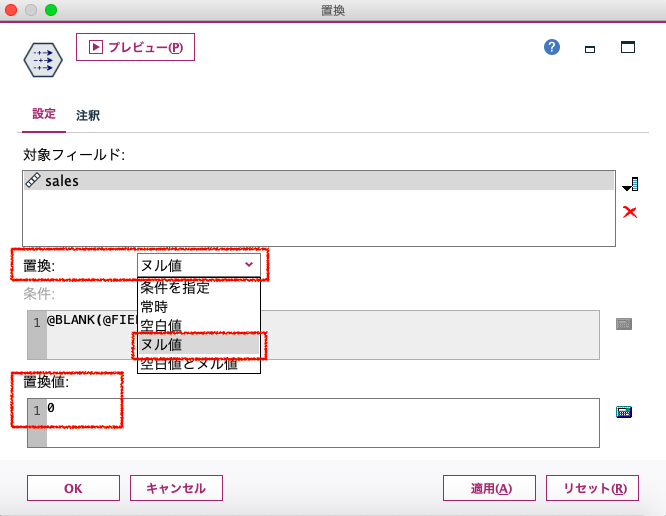
結果のテーブルは、もう割愛しておきますね。「$null$」のところが「0」になるだけですから。 でも、ここで重要になるのが「欠損の置換」による計算、です。 POSの分析においては、明細のテーブルで1行1品になっている状態を、例えば「再構成ノード」で商品やカテゴリーで横展開し、顧客IDなどで集計(多いのは合計もしくは平均)を取って1行1人のテーブルにする、といったことをよくやります。ここで、欠損をどう扱っているか、によって結果が変わり得る、という点に言及したいと思います。 再度、欠損処理「前」の、先のテーブルをみてください。IDの1番さんは商品Aを2回買っていますが何らかで売上の欄が欠損しています。IDの2番さんは商品Aを3回買っており、1回は「ゼロ」が入っています。ポイントか何かを使いまくったのかもしれません。このとき、レコード集計ノードでIDごとに、「sales」の平均を取ってみたのが次の結果です。

ご存知の方も多いと思いですし当たり前といえばそうなのですが、nullで欠損していたIDの1番さんの売上平均が100円になっており、IDの2番さんは73.33円(=220/3)になっています。実は、ここを意識せずに平均を語っているケースは少なくありません。合計しか使わないのであればnullでもゼロでもよいかもしれませんが、「nullをゼロ置換」する場合は平均をとるときの分母に含まれる/含まれないをちゃんと考えてから、置換をするようにしましょう。
おまけ:「@FIELDS_BETWEEN」で横に集計
今回このコラムを書くにあたり、個人的にはこの関数を真に推したかったがために、今まで置換や@FIELDの話をしてきたと言っても過言ではありません。それくらい便利な関数です。そもそも置換ノードじゃないし、推し「関数」になってる、という反論にはどうか目をつぶって頂いて、先のデータに商品のBとCが追加されたこのようなデータを考えてみます。
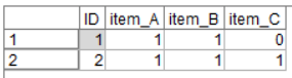
顧客はどの商品を買った・買わない、の状態にしたのが次の状態です。
ここに、横に集計したカラムを設けたい!という場合が結構あります。こんな感じです。
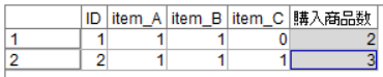
わかりやすさ重視でこの状態を考えているだけなので、1-0のフラグでなくても、リレー連載の「再構成ノード」で河田さんが解説されているような、「1行1人」の単位で各カテゴリーの売り上げがカラムに展開されている状態などでも構いません。 3列くらいであれば、フィールド作成ノードで「item_A + item_B + item_C」でその人が買った商品数を出すことができますが、ビッグデータの時代になると、この横のカラムが数十・数百など、沢山になることがしばしばあります。その場合威力を発揮する関数が、「@FIELDS_BETWEEN」です。
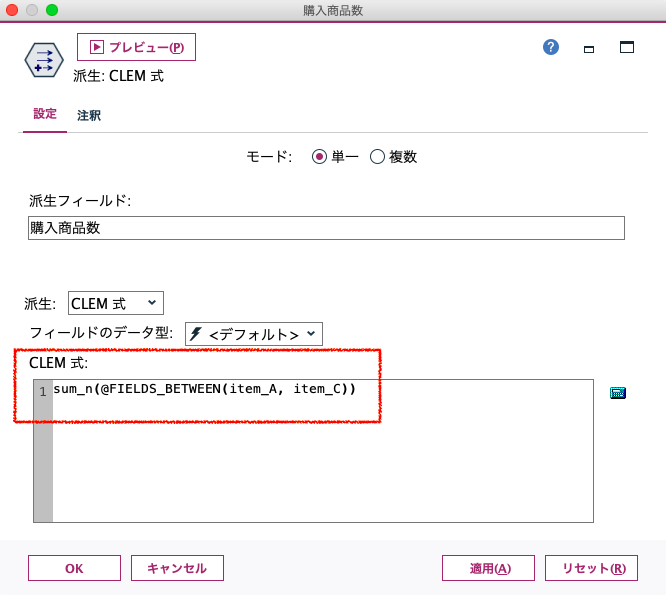
例えば上の「購入商品数」はフィールド作成でこのように書きます。 sum_n(@FIELDS_BETWEEN(item_A, item_C)) 「カラムのここからここまで」を@FIELDS_BETWEENで指定し、sum_nでその横の範囲の合計値をとっています。もちろん「mean_n」関数などで横の平均値を出すこともあると思いますが、その際は、ぜひ先ほどの欠損の扱いに注意ください。 (※この関数が実装されたとき、西牧さんと「列の順番の概念ができた」と言っていたのを今でも覚えています。)
まとめ
値の変換、型の変換、欠損処理という、前処理には欠かせない処理を例に置換ノードを紹介してきました。欠損の置換時はその後の集計値にも影響があることも言及した上で、おまけで横展開した場合の@FIELDS_BETWEENのお話をさせて頂きました。 若干最後で発散してしまったかもしれませんが、複数テーブルを処理し、1行の単位を自由に行き来するような方の何かのきっかけになれば幸いです。
次回のリレー連載、推しノード#16は日本アイ・ビー・エム システムズ・エンジニアリングの水谷さんに「データベースノード」について説明いただきます。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら

福岡大学
商学部 准教授

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

敷居もコストも低い! ふくろう販売管理システムがBIダッシュボード機能搭載
IBM Data and AI, IBM Partner Ecosystem
目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

テクノロジーが向かう先とは〜中長期テクノロジー・ロードマップ
IBM Cloud Blog, IBM Data and AI
IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む