
櫛田 弘貴 氏
スタッツギルド株式会社 StatsGuild Inc.
取締役
統計解析・データマイニング推進部 部長
Modelerのオンライン・トレーニングコース
2020年08月12日
カテゴリー Data Science and AI | IBM Data and AI | SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:

スタッツギルドの櫛田です。
弊社は、IBM SPSSのライセンス販売、受託データ分析、コンサルティング、研修サービスなどの支援サービスによって、データ分析による価値創出のサポートさせていただいております。これまで、企業、医療機関、大学、研究機関、官公庁など1500社を超えるお客様にソフトウェアや支援サービスをご提供して参りました。今回は、数あるModelerのノードの中から前処理のための「レコード結合」ノードを留意点と合わせて解説したいと思います。
分析のためのデータの下拵えを前処理と呼びます。業界や分野によって、データ加工、プリパレーション、クレンジングなど、呼び方はさまざまですが、手間も時間もかかる作業で、目肩腰に来ます。Modelerは前処理の履歴がストリームで把握できて、社内共有しやすいなどのメリットもありますが、ノードと矢印が増えすぎて曼荼羅ストリームに昇華することもしばしばです。余談ですが、本当はデータの取り方さえしっかりしていれば、データ加工も最小限、分析手法はシンプルなもので良いことも多いのです。
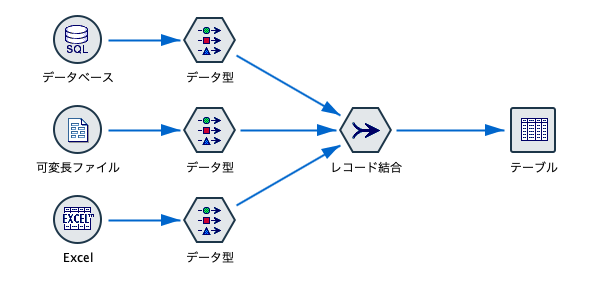
さて、分析したいデータが綺麗に完成しているとしたらラッキーです。実際は、データソースが、企業や組織内の色々なシステムやデータベースに散在していることが少なくありません。また、通常は活きの良いデータほど後から追加されたり、既存の箱には入っていなかったりします。そこでそれらをくっつける、この代表的な前処理が「ファイル結合」です。名寄せとも呼び、データベースではSQL、RやPythonではコードを書きますが、Modelerは、何と言ってもマウス操作のみ。分析結果の良し悪しは必要なデータを適時適切につなげられるかにかかっており、私が推す「レコード結合」は思いついたら即繋いでゲームメイクする「キーマン」といえます。それでは、異なるデータソースのフィールド(列)を結合してみます。
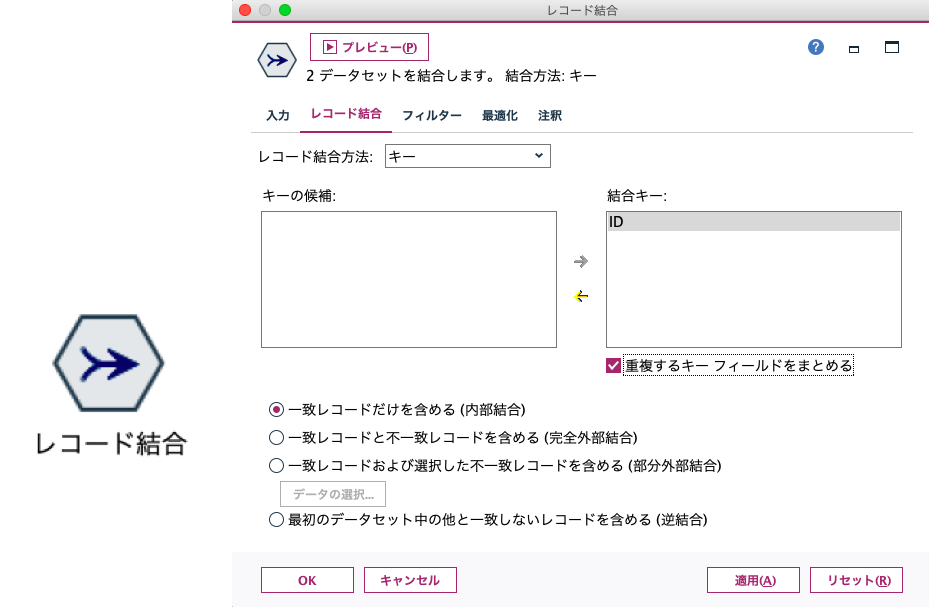
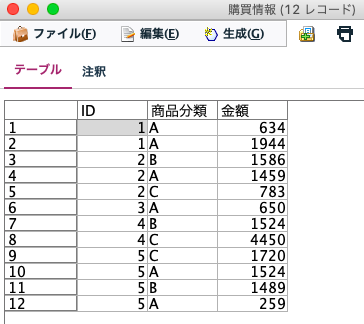
かなり少ないレコード数ですが、顧客情報を格納した「顧客情報」(マスターテーブル、5レコード)と、購入商品や金額などの履歴を格納した「購買情報」(トランザクションテーブル、12レコード)を用意しました。この2つをレコード結合してみましょう。今回は2つのテーブルでやりますが、3つ以上の複数テーブルの結合もGUIのみで可能です。結合のキーになるのは「ID」です。この値が同じレコード同士がくっつくことになります。これは「1:N」の結合です。

用意するのはレコード設定パレットの「レコード結合」ノードです。
1つ目のアイコンと2つ目のアイコンをマウスでドラッグしてくっつける。これだけです。
さすがModeler、ドラックだけでいけます。

少し中身を見てみましょう。
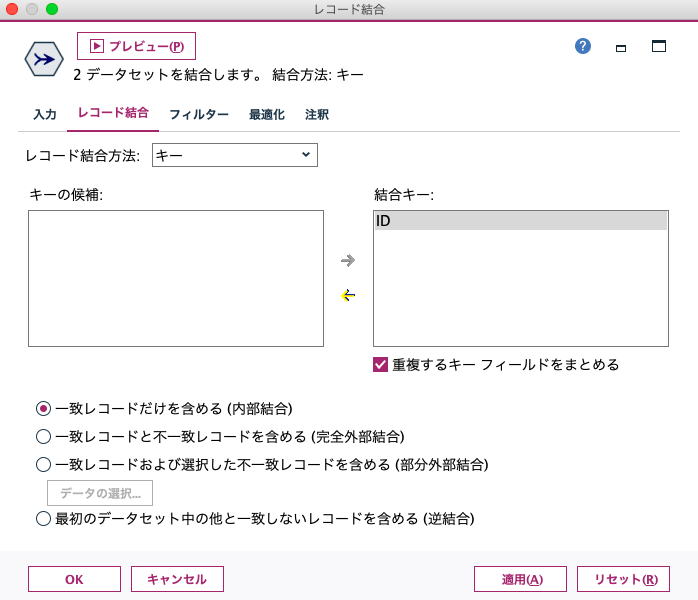
結合の「キー」を指定すると、IDなどの値に基づいてくっつけられます。複数キーの使用も可能ですので、「地域コード+店舗コード+顧客ID」などのように組み合せた結合も簡単に指定できますし、条件式を書いて結合させる応用も可能です。このキーは大文字と小文字を区別するので、場合によっては事前に一致させておく必要もありますが、フィルターの機能もあるのですぐ調整できます。
また、結合方法は、内部結合、完全外部結合、部分外部結合、逆結合が選べます。片方にしかないIDも残したいときは外部結合系を選びます。逆結合のオプションもエラーチェックに使えたりして便利です。そして、フィルタータブを見ると、フィールド名の変更や不要なフィールド除外ができます。特に重複フィールドは赤字で表示されるので、ぱっとみておかしなところを見つけられます。

また、ファイル結合はデータ規模が大きくなると一般に処理が重くなりやすいですが、最適化タブではラージデータセットの指定や、ソート済データセットのソート省略などの設定があったり、色々と便利が細かい機能が用意されていますが、今回はデフォルト設定でやってしまいます。テーブルでチェックしてみるとこんな感じでできあがりです。レコード数は、購買情報テーブルと同じ12レコードです。
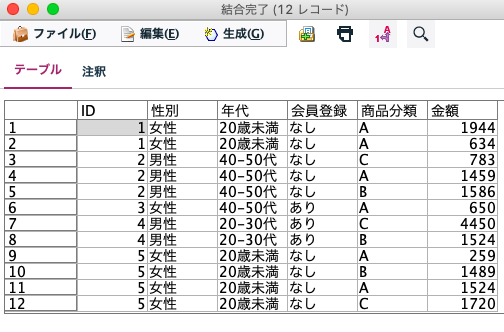
とても簡単なレコード結合ノードですが、注意しなければいけないのは、キーフィールドの関係が「1:1」「1:N」「N:1」のように、いずれかをユニークにしておかなければいけないということです。意図せずに「N:N」の結合を行うと重複レコードが発生し、さまざまな弊害をもたらします。
簡単な例でみてみましょう。
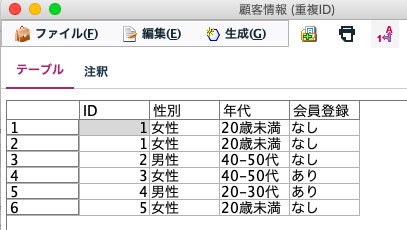
マスターテーブルは顧客情報なので1人1レコードになっている必要がありますが、この例ではID=1さんが重複して2人います。同じIDが「N」個存在して同一人物が2人いる、データの意味としてNGです。
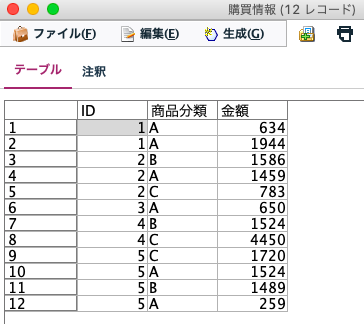
購買情報は、1人が複数回購入することを想定しており、同じIDが「N」個存在していますが、データの意味として問題ありません。例えば、ID=1さんは商品分類Aを2回購入しています。
上記2つのファイルのIDの関係性は「N:N」(複数対複数)になります。これをこのまま「レコード結合」すると、こうなります。
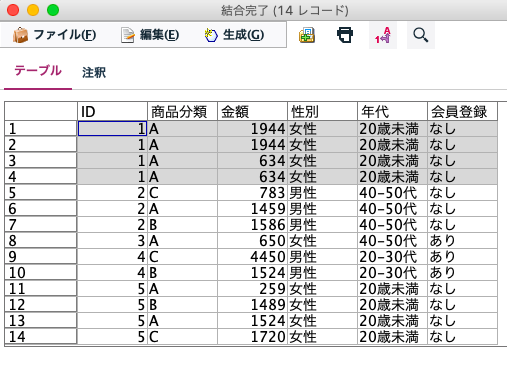
なんということでしょう。ID=1さんは2回しか買い物をしていないのに4行に増えてしまっています。これは「N:N」の結合によって、双方のファイルの同じID同士を突き合わせることで重複したレコードができてしまった例です。
顧客情報に2レコード、購買情報に2レコードありますので、2×2=4レコードできてしまいました。もちろん、結合結果のレコードは誤りです。これは少数なので目視も不可能ではないですが、数百万レコード、数千万の規模になったらどうでしょう。仮に、ID=1が双方にそれぞれ、1000レコードずつあったとすると、1000×1000で100万レコードもの実用性のないレコードができてしまいます。これは、すべてのレコードの組み合せからなるデカルト積(直積)と呼ばれる問題で、データのエラーに起因することが多く、データは間違っているし、処理時間もかかるし、いいことなしです。実際、過去のコンサルティングの場面でも何度も遭遇している事例です。
基本的に、どちらか一方のIDはユニークにしておく必要があります。ツールによってはこのような「N:N」の結合に機能上の制限をかけているものもありますが、Modelerは「N:N」の結合にも対応できるよう制限をかけていないので、事前に「重複レコード」ノードなどを使用して、IDの関係を整理しておくひと手間があるとより良いでしょう。
「N:N」の結合を、意図的に実施することもあります。例えば数値予測モデルが出来上がった後で、いくつかのパラメータ候補からもっとも理想的な予測値になるデータの組み合わせを見つけたい場合です。起こり得る全ての組み合わせをもつシミュレーションテーブルを作るために元データから「レコード集計」でメンバーや数値のリストを作ります。そして「レコード結合」の結合方式はキーにしながらも実際のキーをブランクのまま結合すると、以下のような「N:N」結合の利点を活かした組み合わせテーブルを生成できます。ぜひトライしてみてください。
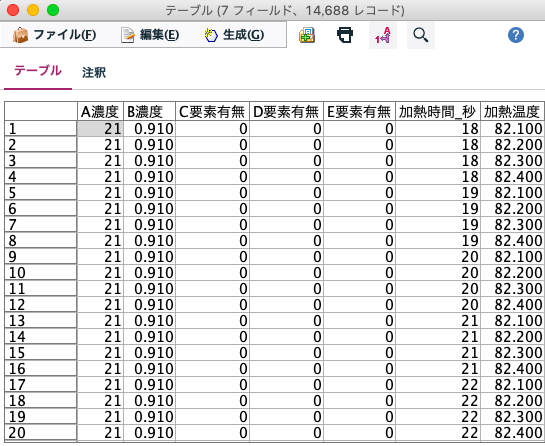
実は他にも要注意の落とし穴があります。特にCSVのようなテキストデータの場合フィールド名が正しく、同じ数字が入っていても一方が「整数」で、もう一方が「文字列」であるためにエラーになります。
この場合は「可変長ノード」読み込み時点で、強制的に型を上書きしてどちらかに合わせるか、「置換ノード」で「to_integer(ID)」のように変換関数を使ってください。

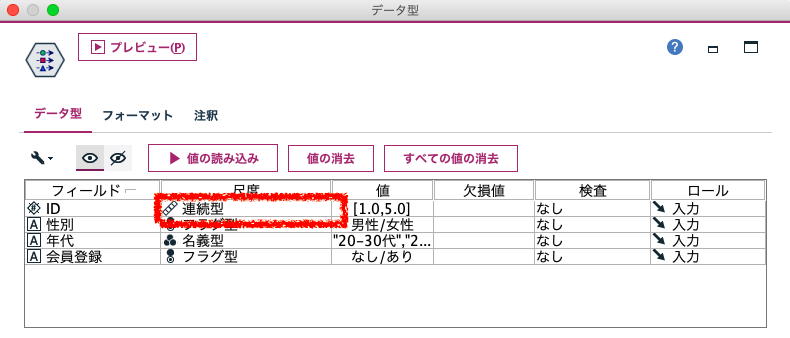
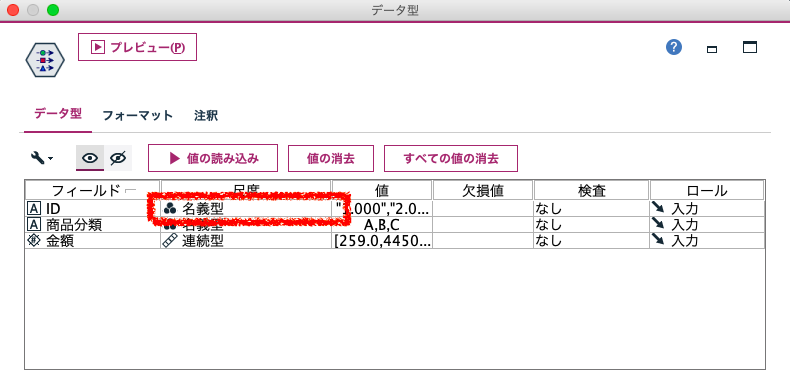
また数字ではなく「商品名」のような文字列をIDにすると「爽やか緑茶500ML 」のように後方N文字空白がはいったことで結合が成り立たないケースがあります。これは、直前に「trimend(商品名)」として後方に存在しているスペース文字を「置換ノード」でトリミングしていただくと良いと思います。
他にも「なんで?繋がらない」という状況に出くわしても、ほぼ確実にデータ側になんらかの罠がありますので深呼吸して、もう一度データを調べてみてください。
何のために前処理をするか、何のために分析をするのか、それは、業績の改善や向上など何らかの価値を創出したり課題を解決したかったりするからです。その意味で、分析ツールはGUIでも言語でもなんでも良いわけですが、ニーズや用途、費用対効果(時間的なコスト含む)などを考えて、使いやすさは重要な選択肢の1つにあがります。ニーズや状況、ユーザーレベルなどにもよりますが、マウスでできてしまうファイル結合はとても魅力的な機能の1つではないかなと思います。おそらく全てのユーザーが使っているはずの「レコード結合」ですが、この記事をきっかけに今一度便利さやリスクを見直していただけると幸いです。
次回の推しノード#14はIBMの上田さんが「時系列ノード」を紹介してくださいます。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら
櫛田 弘貴 氏
スタッツギルド株式会社 StatsGuild Inc.
取締役
統計解析・データマイニング推進部 部長
Modelerのオンライン・トレーニングコース

皆さんこんにちは。山下研一です。IBM Data&AIでデータサイエンスTech Salesをしています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活 ...続きを読む
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む
皆さんこんにちはIBMの河田です。SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を進め ...続きを読む