
鳥海 淳一 氏
プラス株式会社
リテールサポートカンパニー ラックジョバー事業部
分析・プランニング部
部長
2020年07月22日
カテゴリー Data Science and AI | IBM Data and AI | SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:

プラス株式会社の鳥海です。
プラスは「新しい価値で、新しい満足を。」を企業理念に、「ユニークネスの追求」のもと、文房・事務用品やオフィス家具の製造・販売、そして新たな中間流通事業を柱に事業を展開しています。
その中で私の所属するリテールサポートカンパニーは、主に量販小売チェーン(ホームセンター、GMS、スーパーマーケット、ドラッグストア…)のお客さまに対し、業界に蔓延る「経験」・「勘」・「慣習」による売場提案ではなく、POSやID-POSデータといった、データ分析(エビデンス)に基づいた、お客さま視点の最適な文具売場の提案活動を推進しております。
IBM SPSS Modelerを使い始めて6年、そのお陰でバリバリ文系の私ですが「データ分析者」を名乗っています。SPSS Modelerはプログラミング知識なしでもデータの集計・統合から機械学習アルゴリズム、たとえば「教師なし学習」で知られる「クラスターモデル」も簡単に作れます。実は顧客や商品のグループ化で知られる「クラスター分析」ですが、私はよく店舗を分類・理解して課題解決の材料にしています。このブログでは「クラスターモデル」の中でも私が最も頼りにしている「TwoStepノード」を、その「推す」理由とあわせてご紹介します。
クラスターとは花やぶどうの「房」のことで、同種の「もの」や「人」の集まり、群れ、集団を意味します。クラスター分析とは、その名の通りデータ全体をいくつかの集団(グループ)に分類する分析手法で、分類にあたってはサンプル同士がお互いに「似ているか」または「似ていないか」を基準に分ける、簡単に言えば「似たもの集めの手法」です。
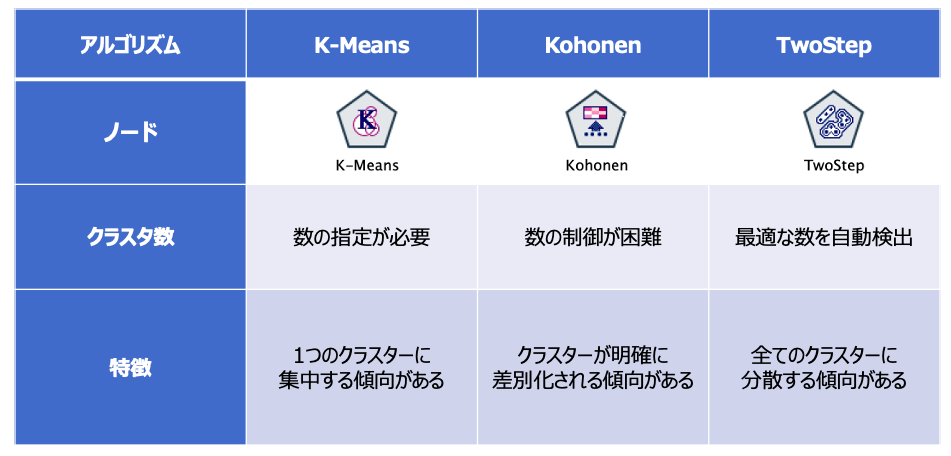
SPSS Modelerではこの「クラスター分析」に「K-Means」「Kohonen」「TwoStep」の3つのモデルが用意されています。それぞれそれぞれの特徴は以下の通りです。
クラスター分析はID-POSデータなどのいわゆる顧客購買データから顧客をグループ化するために頻繁に利用されます。顧客グループの特徴や傾向を理解したうえでマーケティング施策に活かせると顧客のLTV向上が期待できるからです。
しかし顧客接点を改善する材料は必ずしも顧客データとは限りません。今回の主題である「店舗」をクラスター分析し、グループ化することで有効なマーケティング施策を行うことも可能なのです。
量販チェーンのみなさまは、多数ある自チェーンの店舗をどのようにグループ化すれば良いかを常にお悩みです。それぞれの店舗は地域性やライバルとの関係で等質ではないため、その特性を踏まえた最適な対応が必要だからです。通常は店舗の規模(売上・売場面積)や地域といった情報でグループをつくることが一般的ですが、それだけではお店の特徴を反映しきれません。先に述べた顧客データが手元にあればそのデータをもとに顧客クラスターを作成し、そのクラスターの分布等から店舗をグループ化できます。しかし、多くの場合、手元に顧客データ(ID-POS)はなく、POSデータ(いつ、どの商品が、何個売れた)のみしかないのが実情です。そんな時は店舗における商品カテゴリーごとの売上構成を特徴量とし、クラスターを作成していきます。
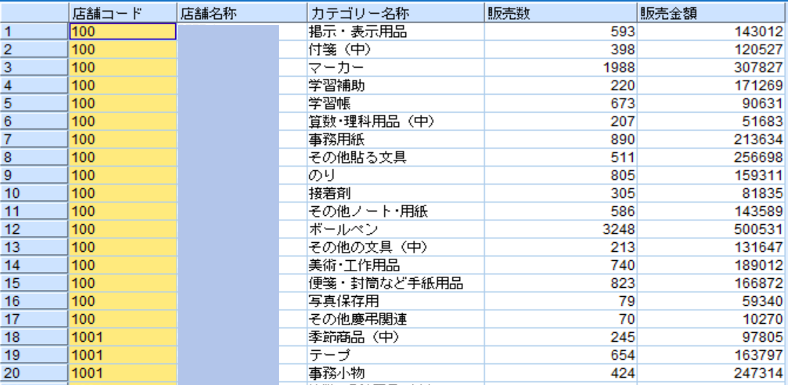
先ずは店舗ごと、商品カテゴリーごとの売上を集計します。
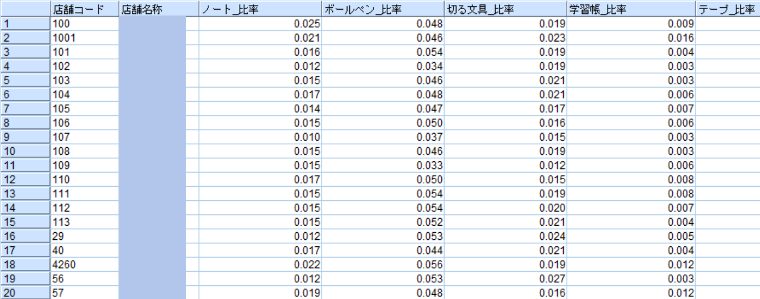
縦持ちデータを横持ちデータへ変換し、店舗ごと、商品カテゴリーごとの売上比率を算出します。

次に作成されるクラスターの数を設定します。「TwoStep」ではSPSS Modelerが自動で最適なクラスター数を算出してくれます(これがほんとうに助かります)が、最大値と最小値の設定が必要です。クラスター分析後のマーケティング施策の内容(多数のクラスターが作成できても、クラスターごとに施策ができなければ意味がありません)によって最大値、最小値を決めていきます。
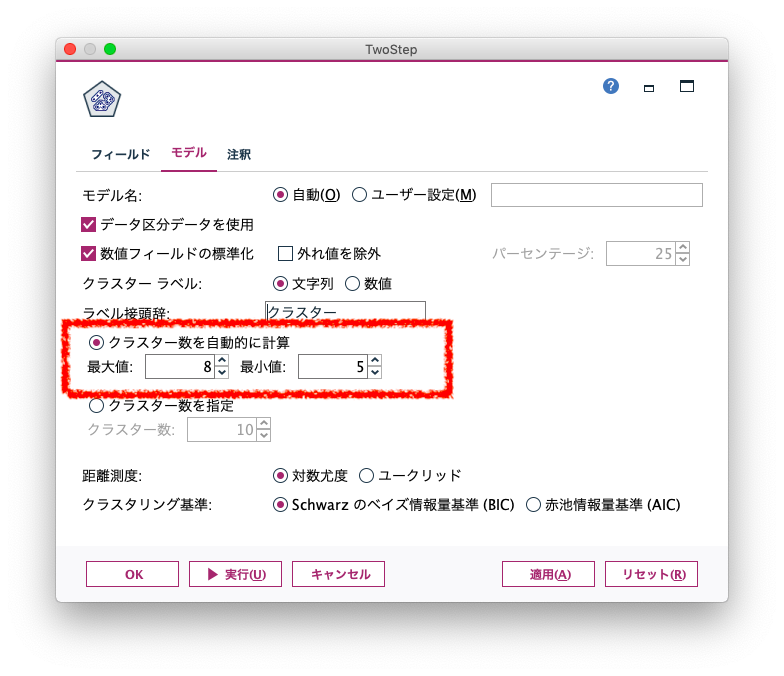
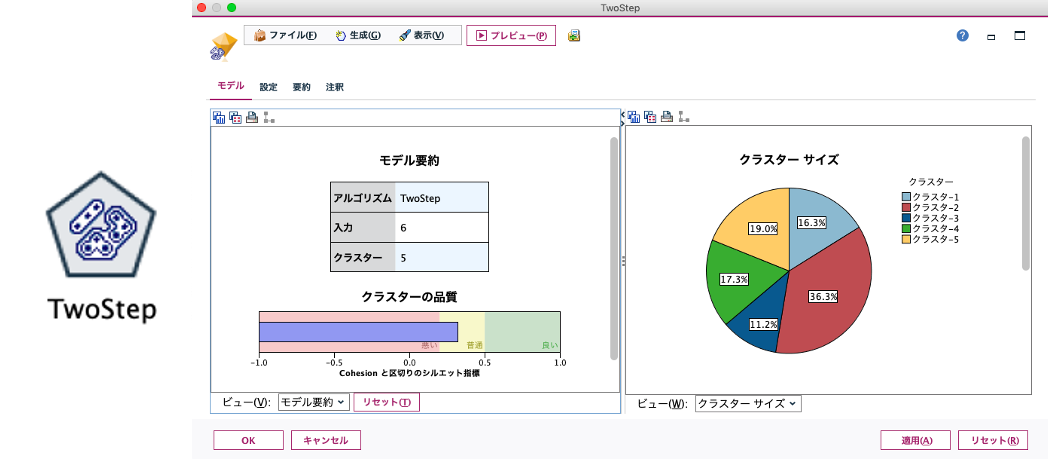
出来上がったモデルの中身を確認します。結果としてクラスターは5つ(最適クラスター数は5と判定)作成されました。
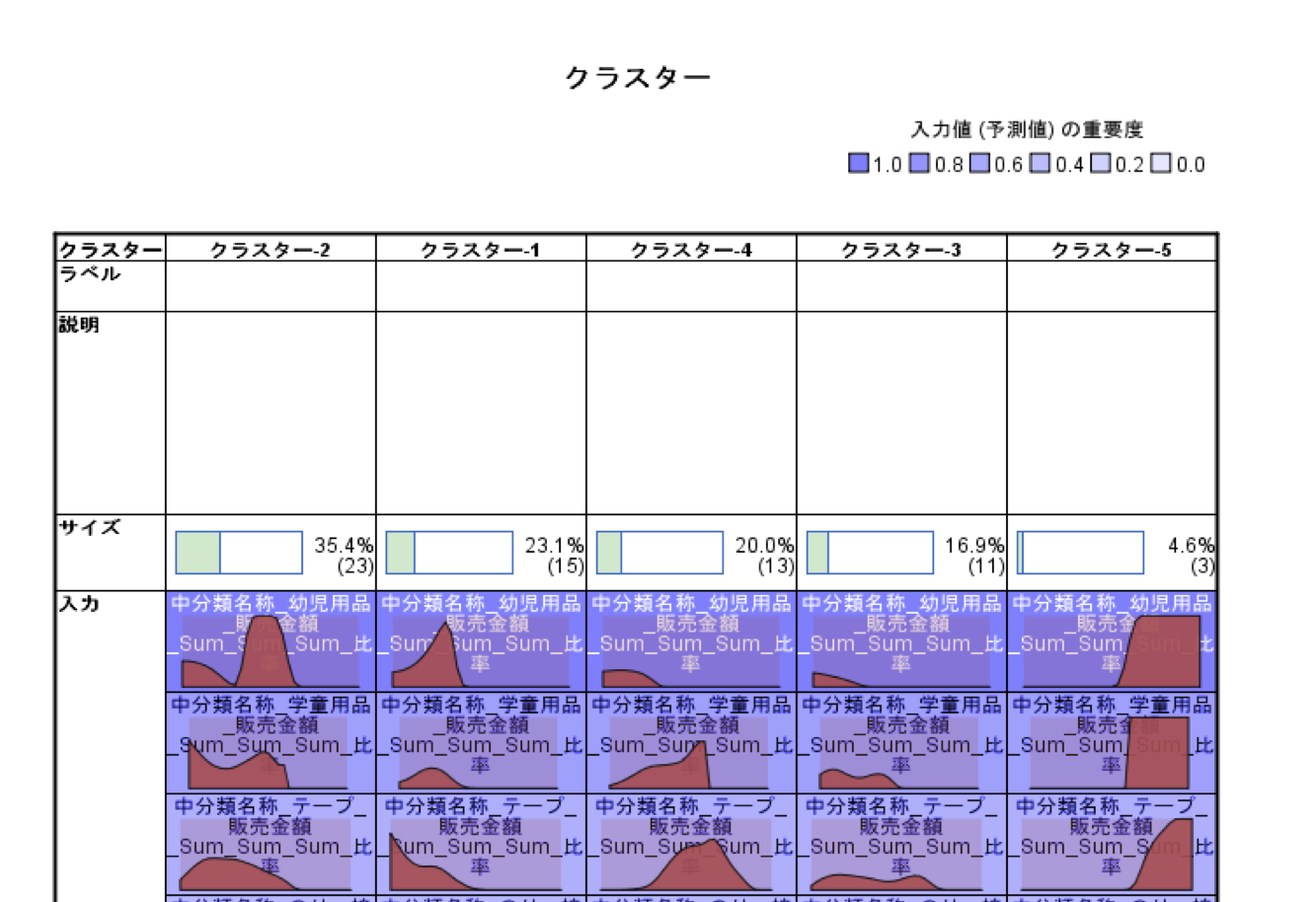
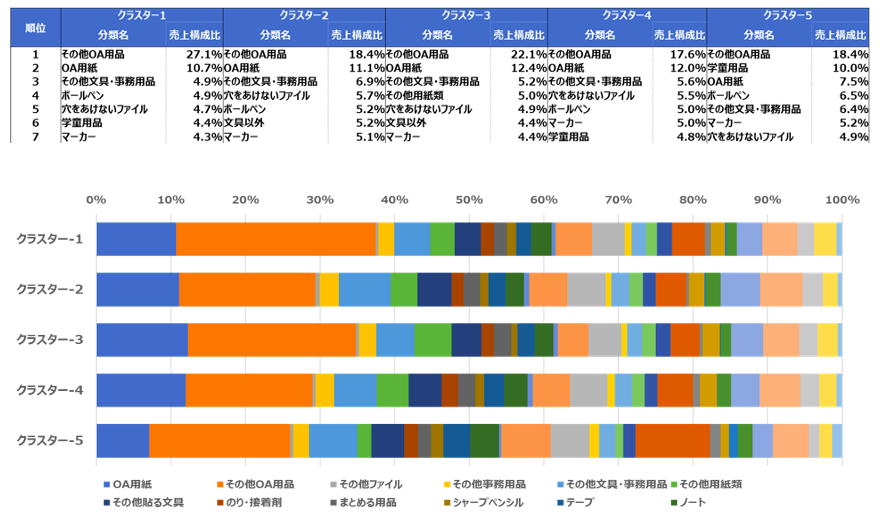
最後に「TwoStep」で作成されたクラスターを実際のビジネスに活用する為、クラスターグループを理解する必要があります。先ずはクラスターごとのカテゴリー別売上構成を確認します。
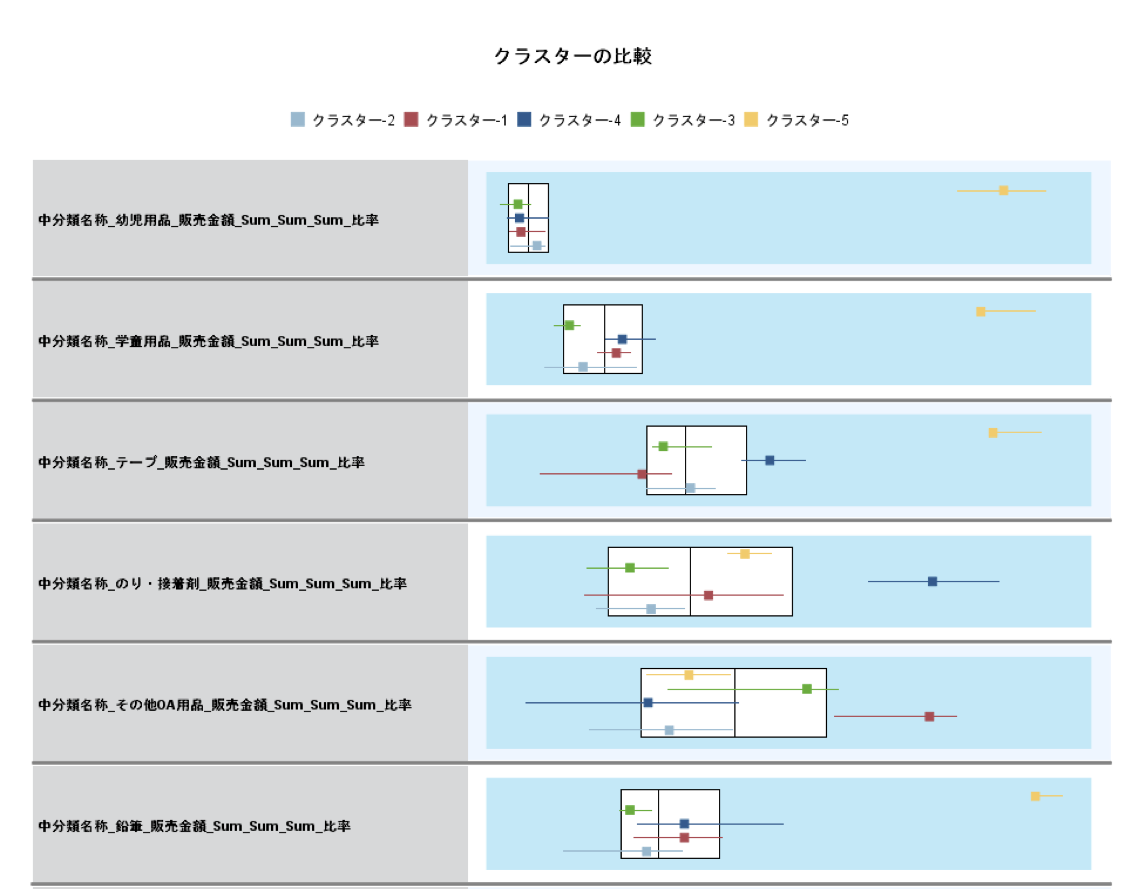
次にクラスターごとの特徴をあぶりだします。場合によっては更に理解を深め、マーケティング活動に展開しやすいように、クラスターに名称をつける場合もあります。ビジネスの仮説からクラスタープロファイルが解釈可能であれば、ネーミングによって現場との合意形成が取りやすくなります。
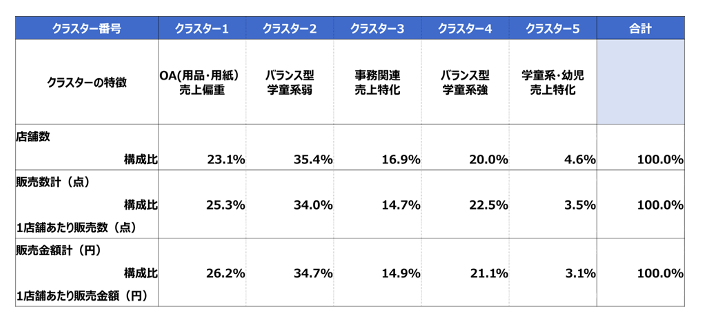
今回作成された5つのクラスターの中で、「クラスター5」は該当する店舗数は少ないのですが、学童・幼児文具の売上構成が高い店舗のグループです。別途、店舗の商圏年齢別人口を確認すると学童・幼児文具の売上と9歳以下の人口構成比に相関がみられました。
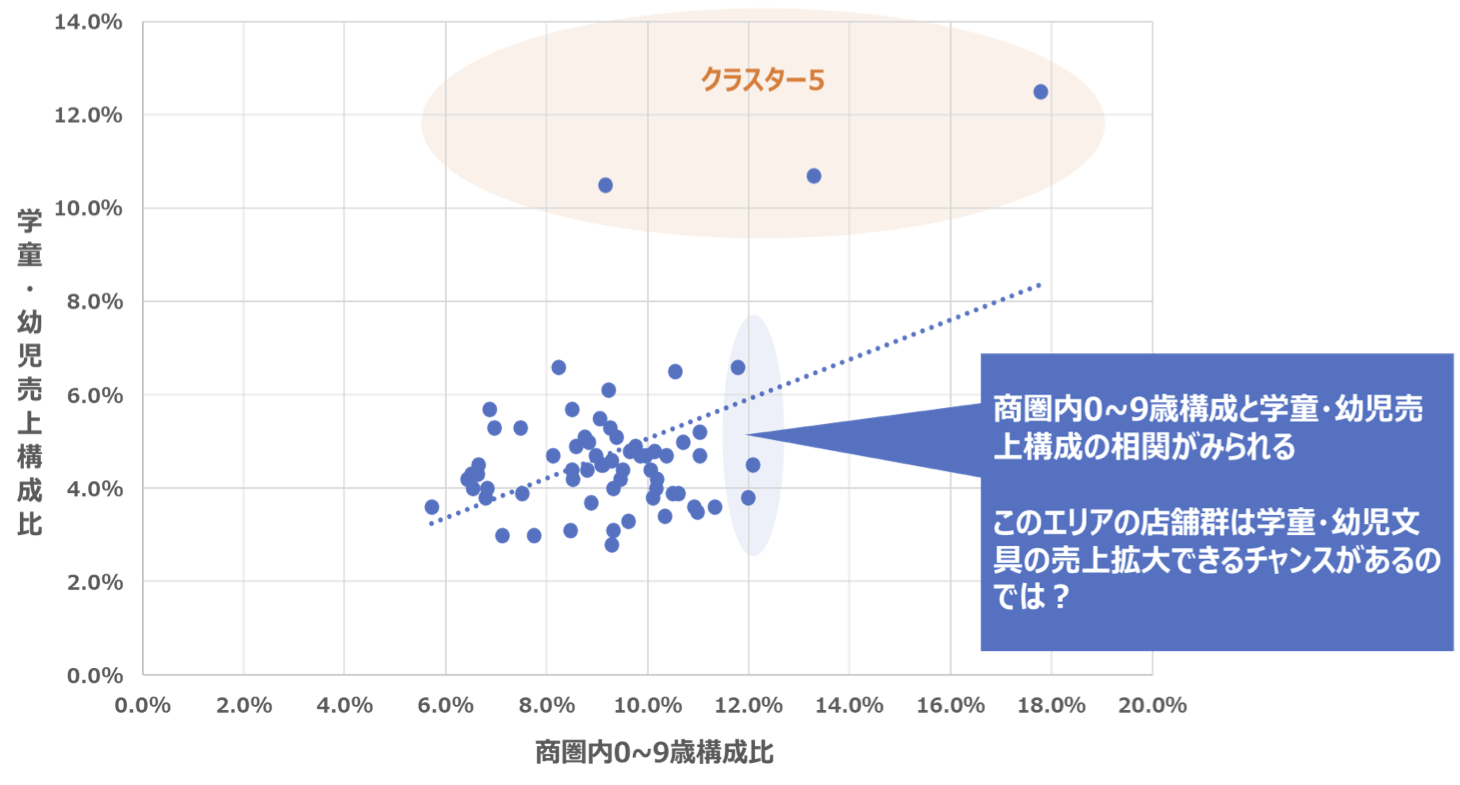
このように「TwoStep」を使用し、簡単に店舗クラスターをつくることで、店舗の特性・特徴の理解やグループ分けができますが、それだけではなく、新たな売上機会の創出につながりやすくなるのです。
今回ご紹介した「TwoStep」をはじめ、クラスター分析の醍醐味は、単にグループ分けするだけではなく、データが導き出すその特徴を深く理解していくことにあります。私のような文系データ分析者にはデータの文脈を読み解くと言う、「たまらない」分析手法だと思います。表面に見えるものだけではなく、見えない特性を気づかせ、そして何よりも「ビジネスの感性」を活かしてくれる文系データ分析者の強い味方です。
リレー連載次回推しノード#12はIBMの守谷さんがグローバルノードを語ってくださいます!
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら
鳥海 淳一 氏
プラス株式会社
リテールサポートカンパニー ラックジョバー事業部
分析・プランニング部
部長

目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む

生成AIによるビジネス革新は、オープンなデータストア、フォーマット、エンジン、製品指向のデータファブリック、データ消費を根本的に改善するためのあらゆるレベルでのAIの導入によって促進されます。 2023 オープン・フォー ...続きを読む