
西澤 英子
日本アイ・ビー・エム株式会社
東京ソフトウェア&システム開発研究所
データサイエンス&AIサービス
2020年07月06日
カテゴリー Data Science and AI | IBM Data and AI | SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:

IBMソフトウェアサービスの西澤です。
Modelerとは、その前身であるClementineの頃からの付き合いとなります。かれこれ20余年。
この間に、数多くの機能が開発され、ノードとして搭載されてきました。現在も、お客様からのリクエストや、データ分析動向の流れから人気のあるアルゴリズムやテクノロジーを使った新機能を拡充し続けています。また、以前からのノードも、新バージョンに置き換わるものがあるにせよ、途中からなくなったノードはありません(ゼロではありません。私の記憶の中ではただ一つ)。
最近、Modeler とRを連携させた機能を見直していたら、以前使えていたRパッケージが更新されていないためにR環境で利用できなくなっていることに気づきました。オープンソースならではの事でしょうか。仕方ないな、と思いつつ、お客様に提供したノードを、メンテナンスして20年後でも使えるように提供しつづける、これこそ、製品の価値ではないかと改めて思った次第です。
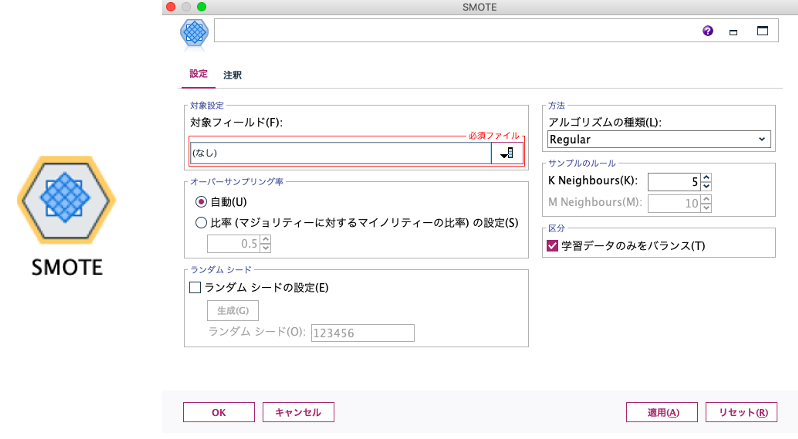
今回は、比較的新しい機能である「SMOTEノード」を中心に紹介させていただきますが、以前からのノード機能にも少し触れさせていただきます。
予測する対象を持つ分析(いわゆる教師あり学習)で予測分析モデルを構築する際に、やっかいな事象の一つとして、カテゴリ対象データの不均衡(アンバランス)により、注目しているカテゴリの予測ができない、というものがあります。実務でご経験がある方も多くいらっしゃるのではないでしょうか。
「SMOTE」とは、「Synthetic Minority Over-sampling Technique」 の頭文字から命名されています。分析に使うカテゴリ対象データが不均衡であり、そのデータ数が少ないカテゴリに対して、オーバーサンプリングする分析テクニックです。内部で機械学習のアルゴリズムを使ってオーバーサンプリングを実施します。この時代ならではの機能であり、Modelerにはv18.1から搭載されています。
不均衡データに対する一般的なアプローチは、以下の3つがよく使われます。
① カテゴリデータ数を増やしたり、減らしたりする方法
② 誤分類コストなどを設定して、ペナルティを付加する方法
③ 少ないカテゴリデータを異常値として分析する方法
Modeler には、①から③を実現する機能が備わっています。このブログで紹介するSMOTEノードは①のアプローチです。
顧客10,000人のうち、あるサービスを解約した人が100人いた例を考えてみます。以下のグラフは、その解約状況の分布を表した棒グラフです。
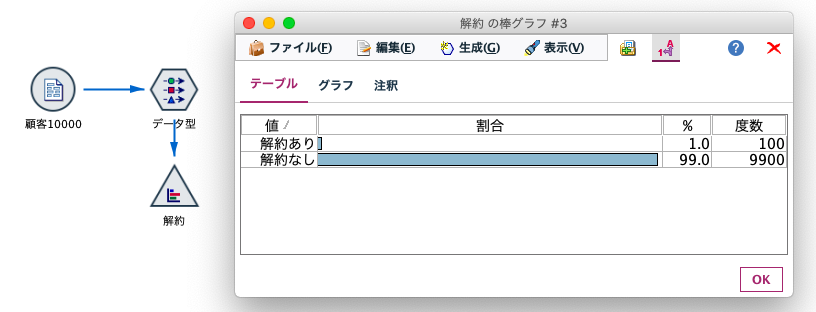
この1%(100件)のデータに特別な偏りがある場合は別として、普通に予測モデルを構築すると、すべてを「解約なし」と予測するモデルが出来上がるでしょう。すべてを「解約なし」に予測しておけば、99%は当たるのですから、当然ですね。しかし、分析者の注目しているカテゴリが「解約あり」の場合は、困ったことになるわけです。予測モデルが使えない!データ分析が役にたたない!!ユーザー様からご相談をいただくこともある非常に悩ましい問題です。
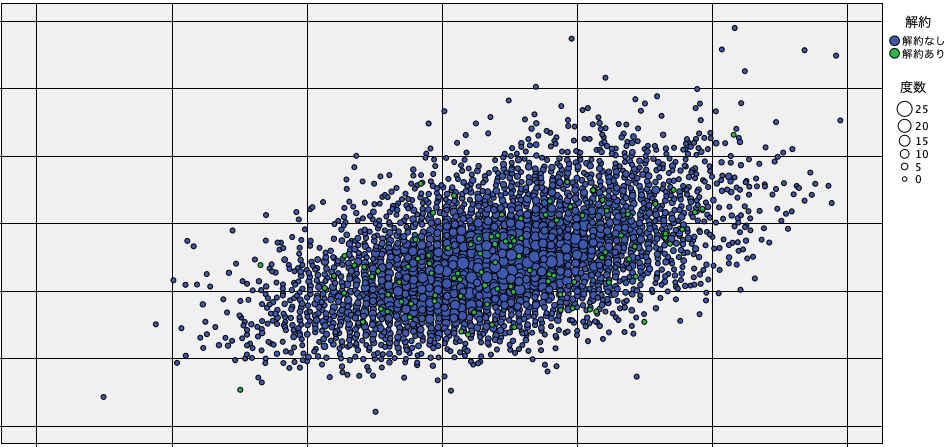
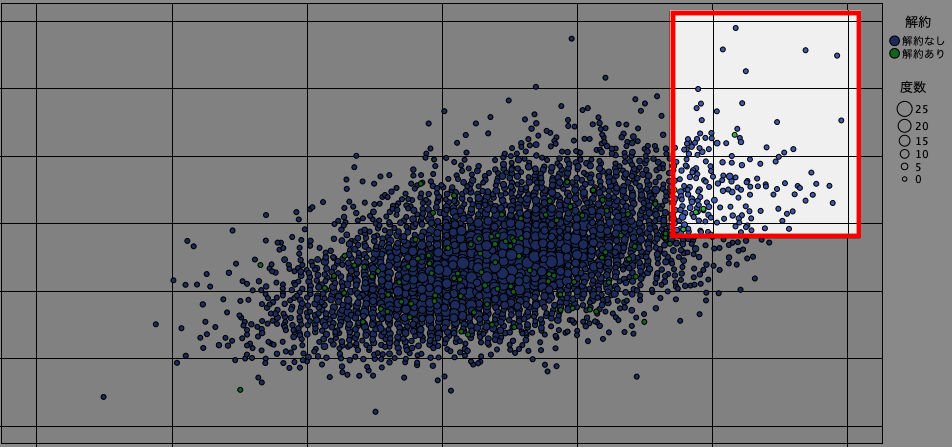
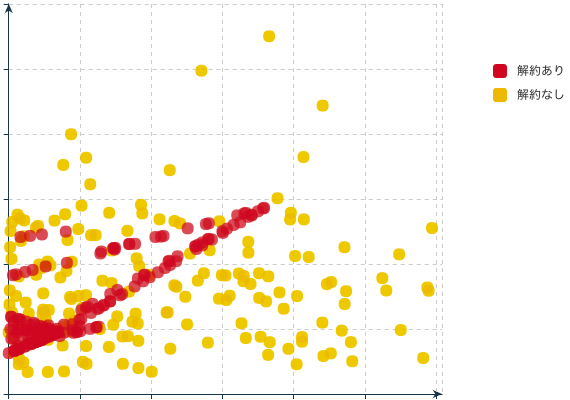
次に、10,000人の顧客データの中の2つの特徴量データを散布図で表現し、その上に解約状況のデータをマッピングしてみます。グラフ上の緑の丸が全体の1%に相当する「解約あり」データです。
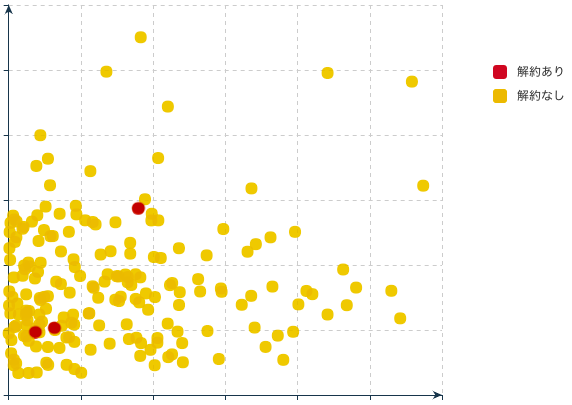
いきなり結果から紹介しますが、SMOTEでオーバーサンプリングをすると、このような散布図になります。
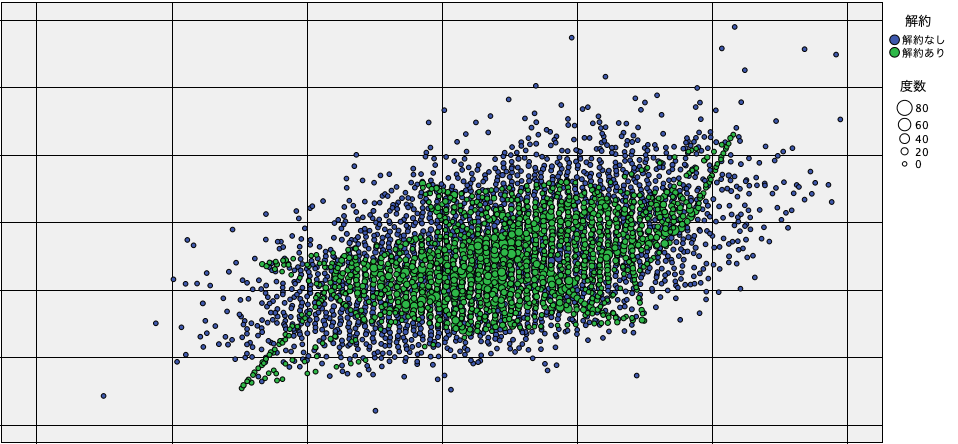
明らかに、緑の丸が増えたことがお分かりいただけますね。この例では、解約なしと解約ありを同じ割合にするように設定しています。
最初の散布図の右上エリアだけのデータを抽出してグラフ化したものが以下です。
Modeler18.2から搭載された視覚化(データの表示)を使用しています。
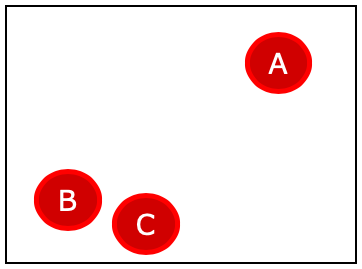
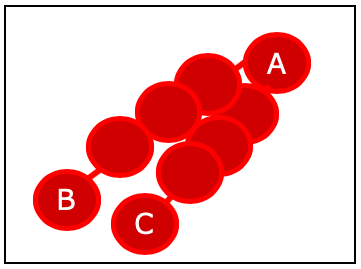
赤丸データだけに注目してみましょう。SMOTEでは、KNN(K-Nearest Neighbor Algorithm : k近傍方)の考え方を使っています。例えば、Aの近隣に存在する赤丸を2つ選ぶとなると、BとCになります。
AとCの間、AとBの間を線補間したイメージです。
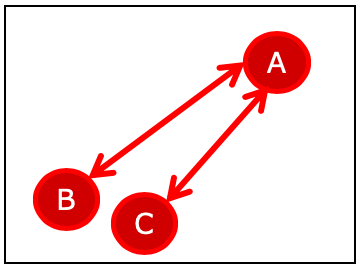
この補間した線上に、乱数を使ってデータポイントを増やしていきます。
新たな赤丸がSMOTEで増やしたデータのイメージです。この補間した線上に疑似的データを増やしていくことで不均衡データを均衡が取れたデータとして扱うことが可能となります。
先ほどのデータに対して、SMOTEでオーバーサンプリングをした結果は以下のようになります。
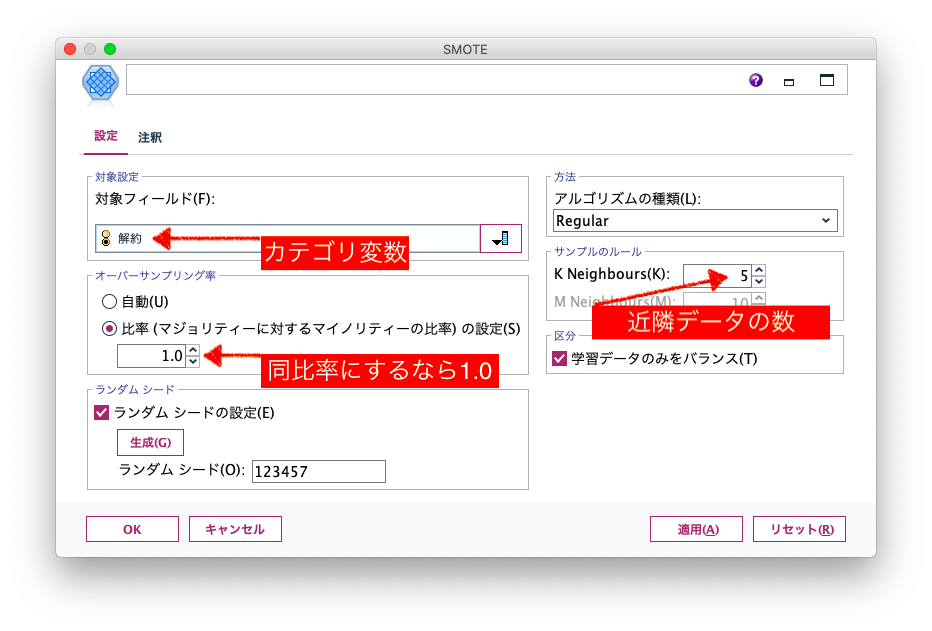
Modelerの「SMOTE」ノードには、アルゴルズムの種類として「Regular」「Borderline1」「Borderline2」の3つがありますが、ここでは、アルゴリズムの種類をデフォルトの「Regular」としました。SMOTEの機能拡張のアルゴリズムは、一説によると80種類を超えて存在しているようです。機械学習の発展とともに、これからもっと増えていくのでしょう。近隣データの数を増やすと、先述の補間の線が増えるので、もっと広範囲に疑似データを作成するようになります。
先に、不均衡データを扱う3つのアプローチを紹介しましたが、SMOTEと同じ①アプローチであっても、別の考え方で不均衡データを扱う機能もあります。
バランスノードは、Modelerの初期から搭載されている機能の一つです。不均衡なデータを、増やしたり減らしたりすることができるとても便利なノードです。棒グラフの結果から、数の少ないカテゴリデータ数を増やしたり、数の多いカテゴリデータ数を減らしたりすることができます。
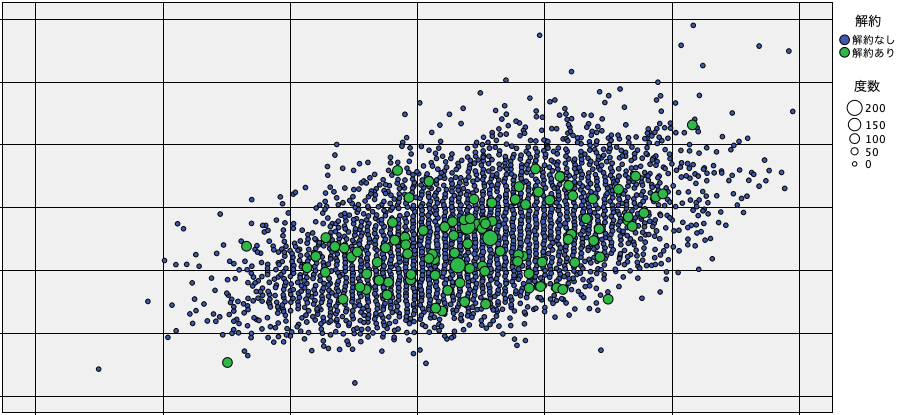
バランスノードで、「解約あり」を増加させたデータを用いて、最初の散布図と同じものを示します。同じデータポイントが単純にコピーされているのがお分かりいただけるでしょうか?明らかにSMOTEの結果とは違いがあります。
不均衡データは、分析者にとって悩ましい問題です。どの方法を使ったらよいのか、そもそも不均衡データを均衡データにしてしまってよいのか。いろんな場面でいろんな考えがあり、唯一解というものは無いでしょう。
でも、不均衡だから分析できない、データが活用できない、と、そこで分析をストップしてしまうのは残念です。Modelerに搭載されているノードで、不均衡データに対する様々なアプローチを試すことで、そこから新たな発見を見出すことが可能になるかもしれませんね。
次回推しノード#11はプラス株式会社の鳥海様が「TwoStepノード」について紹介してくださいます。
→これまでのSPSS Modelerブログ連載のバックナンバーはこちら
→SPSS Modelerノードリファレンス(機能解説)はこちら
→SPSS Modeler 逆引きストリーム集(データ加工)はこちら
西澤 英子
日本アイ・ビー・エム株式会社
東京ソフトウェア&システム開発研究所
データサイエンス&AIサービス

皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む