

























SPSS Modeler ヒモトク
効果的な車内広告のための分析
2016年11月12日
カテゴリー SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:
~ データサイエンティストを目指す大学生のブログ ~
データサイエンス系のメモとか備忘録とか。

みなさんこんにちは。
データがあれば社会が見える、そんなことに憧れながら日々データの処理に泣いている慶應義塾大学、湘南藤沢キャンパス4年の石原智哉と中島有希大です。今回も前回に続きSPSS Modelerを使って身の回りで起こっていることを分析していきます。
今回分析するテーマ
今回分析するテーマは電車の車内広告についてです。
最近、気になる電車広告は? と聞かれて何が思い浮かぶでしょうか。毎日、電車に乗る生活を送る方は少なくないと思いますし、自分もいつも見てしまうお気に入りの広告がいくつかあります。また、電車に乗っている時間が長いとつい広告を読んでしまいます。
一方、私たちの大学の友人で湘南エリアを中心とした芸能・エンタメ情報を配信するウェブサイトの運営企業を経営している人がいます。慶應は女優やアイドル、モデルなど芸能活動をしている人が一定数いたりするので、そのような起業がしやすい土壌があるのかもしれません。その友人が電車内に広告を出すとしたら、どこに広告を表示し、どのような人に向けた内容で広告を出せばよいかと私たちに相談をしてきました。
さらに注文は、Twitter、Facebook、LINE、Instagramのどれかにつなげたいがどれがいいかということでした。
そこで、老若男女の乗客という視聴者が一定時間その場に存在し、目にする機会が充分あると思われるこの“電車の車内広告”の見られ方について分析し、どうしたら車内広告をより効果的に活用できるのかSPSS Modelerを使って検討してみることにしました。
今回の狙いは3つあります。
1. 広告をどこに設置すればよいのか考える
特定の電車内広告について、どのような人が、どんな場所に掲示されている広告を見ているのか現在の傾向を探ります。これを元に、どんな車内広告がよいか考察してみたいというわけです。
2. 分析を共有する
どのような分析をしているのかを友人に伝えるとともに、友人もしくは友人の起業仲間が分析を続けられるようにストリームを残します。
3. 後に生かすために
今回の分析を踏まえ、広告を出稿した当事者がより効果が出るように改善を重ねることを目的に、どのようにPDCAをまわせるかを考えます。
電車内広告にもいろいろある
電車に乗ると気づかれるかと思いますが、広告を貼る場所はさまざまであり、資料を見せてもらったところ場所によって費用も異なってくるようです。電車の中とはいえ、広告なのでけっこう高額です!
私からしたら参考:jeki(ジェイアール東日本企画)より中吊り広告の広告料金表
使用するデータ
使用するデータは株式会社マーシュの「電車内での過ごし方に関するアンケート調査」です。
調査項目は以下です。
- 普段、電車に乗る時間はどの位ですか。
- 電車に乗っている時、何をしていますか。
- 電車内でどのような広告を見ることが多いですか。
- 電車内の広告でどのような広告をよく見ますか。
- 「女性専用車両」導入についてどう考えていますか。
- 「女性専用車両」をどの位利用していますか。
1都3県の20代~60代の男女400名に対するアンケートの結果です。アンケートの実査期間は2016年6月3日(金)~2016年6月5日(日)です。
また、上記の調査項目のほかに回答者の属性などがデータには入っています。
分析の目的と手法
1. 目的
今回の分析の目的は、芸能・エンタメ関連広告を見ている人が、電車内のどこにある広告を見ているか、また電車内でよく何をしている人なのかを分析し、より効果的に広告を打ち出していくことです。
2. 手法
SPSS Modelerの決定木分析(ディシジョンツリー)を用いて分析していきます。
決定木分析とは、決定において実際に問題になる属性だけを自動的にルールに取り込むものです。ツリーの精度に関係ない属性は無視されます。これにより、データに関する非常に有益な情報が得られます。
参考:日本IBM公式サイト ディシジョン・ツリー・モデルの説明 (参照:2016-09-27)
今回使用するデータは、分析に使用できる変数のうち、ダミー変数が非常に大きな割合を占めており、回帰分析などは非常にしづらいデータです。そのため、条件分岐もできて、今回のデータを扱いやすいディシジョンツリーを使って分析をします。
使用するモデル
使用するモデルはC5.0です。

SPSS Modelerには決定木(ディシジョンツリー)だけでもいくつかのモデルが搭載されています。
C5.0 ノードは、ディシジョン・ツリーとルール・セットのどちらかを構築します。このモデルは、各レベルで最大の情報の対応をもたらすフィールドに基づいてサンプルを分割します。対象フィールドは、カテゴリーでなければなりません。複数の分割を 2 つ以上のサブグループに分割できます。
参考:日本IBM公式サイト C5.0ノードの説明 (参照:2016-09-27)
では分析に取り掛かります!
広告を見る人はどのような行動をしているのか
ストリームは以下です。
図1:ストリーム
「データ型」ノードの設定で 「芸能・エンタメ関連」広告を見る(Q6-1、複数回答)を対象(目標変数) に設定します。入力(説明変数) には性別、年齢、住んでいる地域、結婚しているか、子供はいるか、どのような勤務体系か、世帯収入、電車に乗る頻度、電車に乗る目的、電車に乗っている時間、どのような電車に乗るか、電車内でどのようなことをしているか(「広告を見る」を除く)、スマートフォンで何をしているか、どこの広告を見るか、を選択しました。
電車内ですることの設問において、スマートフォンを使用しているという回答は、のちのスマートフォンですることの前提となる質問であり、回答が重複してしまうため、分析から除外しています。
また、今回は条件抽出ノードを追加しています。今回は乗車時間と世帯収入を未回答にしている人を分析から除外しています。
乗車時間と世帯収入は実数ではなく、カテゴリーに分かれているいわゆる順序尺度となっています。未回答を含むとこの順序が乱れてしまうため、排除しています。
条件抽出はExcelを使う際にはIf関数を利用すると思いますが、関数をExcel上に残しているとどんどんデータが重くなっていきますし、SPSS Statisticsなど別のソフトウェアに関数を残したまま読み込ませると不具合が起きる場合があります。
また、値として貼り付けてしまうと、後からどのような基準でデータを作成したのかわからなくなったり、他の人との意思疎通が困難になったりします。
その点SPSS Modeler上でこのようなデータ加工処理を行えば、オリジナルのデータを保持しつつ、処理の記録が残るため、どのようなロジックで条件を抽出したのかを後から思い出したり、他者と共有したりする時に非常に便利です。
最後に、友人からの依頼上、“人々がスマートフォンを使ってやっていること”はなるべく分析に追加できるよう、ノードのデータ型で調整しました。
2. 解釈
芸能・エンタメ関連広告を見るは0:見ない、1:見るとなっています。芸能・エンタメ関連広告を見ると回答した人は、106人でした。これは、全体(400人)の約25%、Q-2で電車内広告を見ると回答した人(168人)のうちの約63%です。
さらに①で記載したように条件を抽出すると対象サンプル数が151、広告を見る人が97、割合として約64%となります。
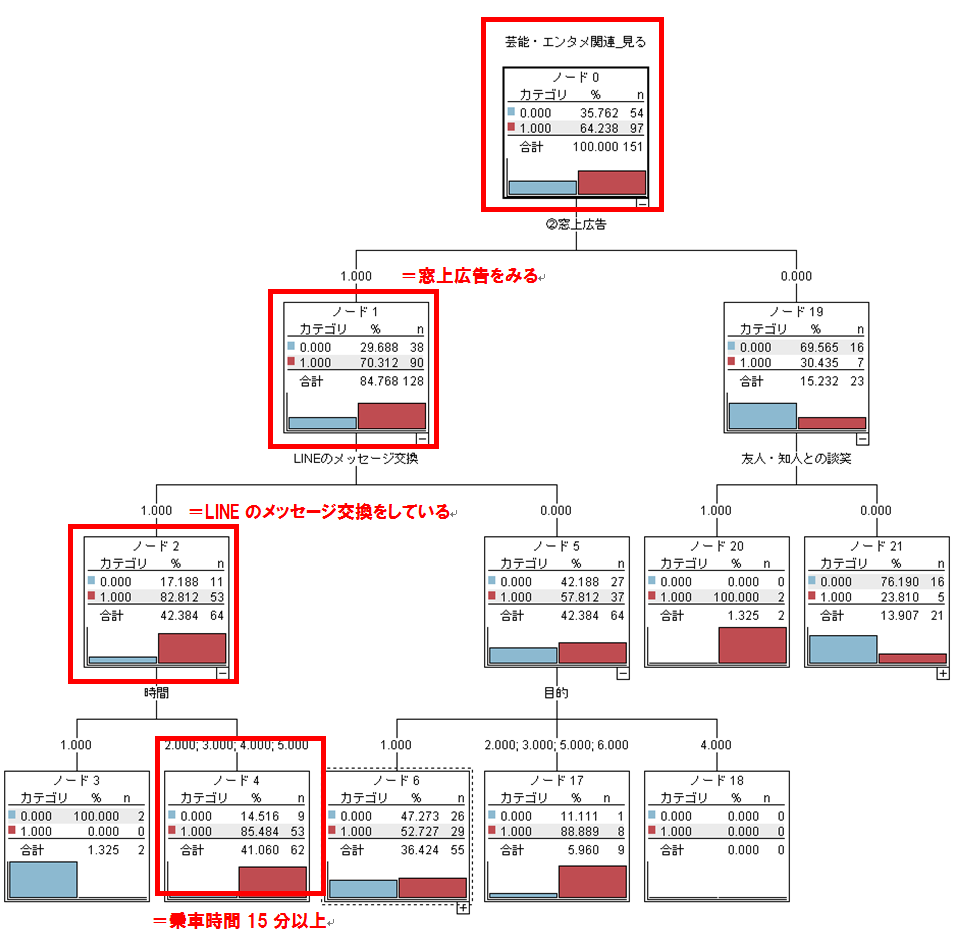
出力されたディシジョンツリーは図2のようになります。
図2:ディシジョンツリー

まず、芸能・エンタメ関連広告は窓上広告の場合に最も見る人と見ない人との差異が大きくなるようです。
芸能・エンタメ関連の窓上広告を見る人は90人で、窓上広告を見る128人の約70.3%でした。
さらに、電車の中でLINEのメッセージ交換をしていて、電車に乗っている時間が15分以上の人が多いようでした。
このディシジョンツリーに表示されている変数以外にも 1. ストリームの作成 で書いたように、様々な変数を投入しています。その中でも特に影響力の強かった変数が図2に表示されている変数になります。
例えば、電車内広告といって思い浮かべるのは、中吊り広告である人が多いと思いますが、芸能・エンタメ関連広告に関していえば、窓上広告のほうがよく見られているので、影響力が大きい可能性があります。
また、スマートフォンでできることにはさまざまなものがありますが、TwitterやInstagramといった別の媒体よりもLINEのほうが利用されているということがわかります。
この2点が分かったことは、非常に大きな意義があるのかなと思います。
また、ディシジョンツリーに現れなかった性別や年代、職業などは強い関係はなさそうです。
3. 考察
以上より、エンタメ・芸能関連の広告を出す場所としては、窓上広告が最適であろうことがわかります。
そして、広告から次につなげる先は、TwitterやInstagram、Facebookなどではなく、LINEであると言えます。LINEをしない人でも窓上広告を見てくれやすいとも言えますが、LINEをしている人のほうが割合として高いため、LINE利用者のほうが確実であると言えます。
ターゲットとしては、電車に15分以上乗る人に向けた広告がよさそうです。
まとめ
1. 芸能・エンタメ関連の車内広告をより見てもらえるようにするにはどうしたらよいのか
芸能・エンタメ関連の車内広告を見てくれるのは、LINEをよく利用する人、15分以上の長い時間乗っている人でした。それを考慮に入れてデザインにしたほうが、アウトカムにつながるのではないかと思います。
最後に広告を出す場所は、荷物置き場の上にある窓上広告がよいですと提案しました。
2. 分析を共有する
今回私たちが使った分析は、ストリームとしてビジュアル化されているので、これを利用して、起業した友人に、どのような分析をしたのか、なぜこのような提案に行き着いたのか、説明することができます。説明している中で、彼から別の視点や意見が出てくるかもしれません。その意見を取り入れて別の分析をしてみるということも、その場で簡単にできます。試行錯誤によって、分析を改善し、新しい施策のアイデアを出していくことができそうです。また、このストリームを 保存して、メールなどで添付することで他の方のPCでも見ることができます。どのような変数を入れて、どのようなモデルを使ったのかを見ることができるので再現性に優れています。
3. 今後のために
今回作ったストリームを基盤として広告効果測定のデータを追加し、ノード同士をつなげて1つのストリーム内でPDCAをまわしていくのがModelerならではの使い方なので、 引き続きPDCAをまわしていくためにはどのようなデータを集めるとよいのかを考えます。
今回、電車内の広告を見ている人との親和性を考えると、LINEを利用する乗車時間が長時間の人に対して窓上広告が有効ということが導かれました。そのため今後見ていくべきデータとしては、例えば湘南で行われる新着イベント等の情報を配信するようなLINE@のアカウントを作成し、電車内広告を載せている期間、LINE@アカウントの友達数の増減などと車内広告との関連があるかの確認などをすることで、今後どのように改善するかなどが導けそうです。
ちなみに、広告の具体的なデザイン内容についても友人とディスカッションしました。15分以上乗車している人に関しては、乗車時間が長いということは、読み物や問いかけ系、複雑な図など、すぐに飽きず読み込むようなものがよいかもしれない。一方で、LINE@の友達数の増減をPDCAで見ていくという点から、広告を見た人がアカウントページに行って友達に追加してくれるような広告にするべきではないかという話も出ました。結論としては、これらの情報をうまく実際の広告デザインに落とし込む際は、デザイン系の研究室に所属している別の友人にも相談してみようという話になりました。その友人と話をする時も、今回の分析内容を振り返ったり、別の視点で見たりするためにSPSS Modelerが活躍しそうです。
*本記事は2016年10月20日時点にはてなブログに掲載された『データサイエンティストを目指す大学生のブログ~データサイエンス系のメモとか備忘録とか。』のブログ記事を転載、製品紹介リンクなどを一部再編集したものです。

DB2エキスパート座談会 ~ ClubDB2の舞台裏とDb2展望 ~
Db2, IBM Data and AI, アナリティクス
今年、IBM MQ と Db2 は 30 周年。WAS(WebSphere Application Server)は 25 周年を迎えます。アニバーサリー・イヤーとして 3 製品に関わりのある方々へのインタビューを 1 ...続きを読む

IBM SPSS Statistics 書籍紹介
Data Science and AI, SPSS Statistics, アナリティクス...
SPSS関連の書籍をご紹介します。 新刊紹介 SPSSとAmosによる心理・調査データ解析(第4版)―因子分析・共分散構造分析まで [著者] 小塩 真司 出版社] 東京図書 [内容] メニューを選択するだけ ...続きを読む

元技術理事に伺う Db2の軌跡と舞台裏
Db2, IBM Data and AI, アナリティクス...
今年、IBM MQとDb2は30周年。WAS(WebSphere Application Server)は25周年を迎えます。アニバーサリー・イヤーとして3製品に関わりのある方々へのインタビューを1年を通じて定期的に行っ ...続きを読む