

























SPSS Modeler ヒモトク
第8回 おまけ – IBM SPSS Modelerスクリプトによる分析作業の効率化
2016年03月10日
カテゴリー SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:
1. 対象期間のスライド(日付関数)
データ抽出の際、「レポート作成のために直近13ヶ月分のデータを使用する」というように、期間で対象データを区切ることがあります。その際、毎回 ノードの設定値やパラメータを手動で変更するのは大変です。しかし、関数「date_months_difference」と 「datetime_now」を利用することで、前月から必要な月数のデータを対象とするように簡単に指定できます。
「date_months_difference (ITME1,ITEM2)」は、DATE またはタイムスタンプ ITEM1 から DATE または ITEM2 までの月数を実数として返します。ここではITEM1=タイムスタンプ(データのフィールド名)、ITEM2= datetime_nowとします。いずれも「datetime_date」関数を利用して月初日に設定することで、 「date_months_difference」の結果が当月を基準として何ヶ月前かを示すことになります。
(date_months_difference(datetime_date(datetime_year(タイムスタン プ),datetime_month(タイムスタンプ),01), datetime_date(datetime_year(datetime_now),datetime_month(datetime_now),01)) >= 1)
and
(date_months_difference(datetime_date(datetime_year(タイムスタン プ),datetime_month(タイムスタンプ),01), datetime_date(datetime_year(datetime_now),datetime_month(datetime_now),01)) < 14)
スクリプト内では直接日付関数を使用することはできませんが、ノードの条件文としてセットすることで自由に使えます。
例:
set :selectnode.condition = ” date_months_difference (ITME1,ITEM2)<= 13 ”
##N行に準備された多重回答を集計のためにダミーコードにするサンプルスクリプト
#ストリーム領域にのこったストリームを消す
clear stream
2. 多重回答の集計
アンケート等で、15個の選択肢(例えば趣味)から最大5つまで趣味を回答する、というような多重回答を集計する場合、変数を揃えるのに苦労しま す。5つの回答欄(A1-A5)に記入されたものをそのまま集計することができないため、選択肢(ma1-ma15)を15個の変数として追加し、回答を フラグ化する必要があります。手作業で行うとかなりの時間を要しますが、スクリプトを使用すると、短時間で変数が追加できます。
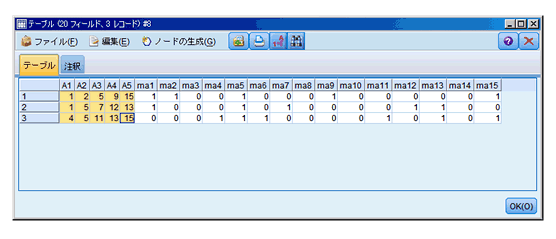
スクリプトの中でデータ作成していますのでModelerのスクリプトタブにペーストしていただき、全文実行で稼働します。
スクリプトは下記の通りです。
#ユーザー入力ノードで行列を作成する。かならずしもここはスクリプトの必要なし
create userinputnode at 50 50
set :userinputnode.data.A1 = “1 1 4”
set :userinputnode.data.A2 = “2 15 35”
set :userinputnode.data.A3 = “125 137 111”
set :userinputnode.data.A4 = “239 142 133”
set :userinputnode.data.A5 = “295 243 215”
set :userinputnode.data_mode = “Ordered”
#変数A1から変数A5に記録されたMAのうち1を回答した人にフラグをたてる
create derivenode at 100 100
rename :derivenode as “MA1”
connect :userinputnode to MA1:derivenode
set MA1:derivenode.new_name = “MA1”
set MA1:derivenode.formula_expr = “count_equal(1, @FIELDS_BETWEEN(A1, A5))”
#以下はまったくおなじ構造でMAの選択肢分作成される。エクセルなどで構造化しておき
#値を循環させると効率よく作成することができる
for p from 1 to 299
set P =p+1
set MAP = MA><^P
set MAC =MA><p
set Posi = (p+1)*100
create derivenode at ^Posi 100
rename フィールド作成:derivenode as ^MAP
connect ^MAC:derivenode to ^MAP:derivenode
set ^MAP:derivenode.new_name = ^MAP
set ^MAP:derivenode.formula_expr = “count_equal(“><^P><“, @FIELDS_BETWEEN(A1, A5))”
endfor
#出力のためにテーブルノードを準備して結合し表示する
create tablenode at 600 200
connect ^MAP:derivenode to :tablenode
execute :tablenode
#以上終了
3. データ型の値でリストの作成
「typenode.values.」を使用すると、データ型で読み込んだ値をリストとして扱えます。
条件別に結果をエクスポートしたい場合などに便利です。
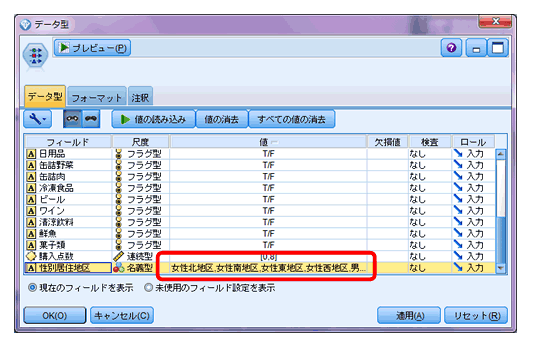
スクリプトは下記の通りです。
execute b
for p in :typenode.values.性別居住地区
set 条件抽出.condition= “性別居住地区=”><“””><p><“””
execute a
endfor

DB2エキスパート座談会 ~ ClubDB2の舞台裏とDb2展望 ~
Db2, IBM Data and AI, アナリティクス
今年、IBM MQ と Db2 は 30 周年。WAS(WebSphere Application Server)は 25 周年を迎えます。アニバーサリー・イヤーとして 3 製品に関わりのある方々へのインタビューを 1 ...続きを読む

IBM SPSS Statistics 書籍紹介
Data Science and AI, SPSS Statistics, アナリティクス...
SPSS関連の書籍をご紹介します。 新刊紹介 SPSSとAmosによる心理・調査データ解析(第4版)―因子分析・共分散構造分析まで [著者] 小塩 真司 出版社] 東京図書 [内容] メニューを選択するだけ ...続きを読む

元技術理事に伺う Db2の軌跡と舞台裏
Db2, IBM Data and AI, アナリティクス...
今年、IBM MQとDb2は30周年。WAS(WebSphere Application Server)は25周年を迎えます。アニバーサリー・イヤーとして3製品に関わりのある方々へのインタビューを1年を通じて定期的に行っ ...続きを読む