SPSS Modeler ヒモトク
第7回 応用編:サンプルデーターが少ない場合 – IBM SPSS Modelerスクリプトによる分析作業の効率化
2016年03月09日
カテゴリー SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:
応用編:サンプルデーターが少ない場合(クロスバリデーション/交差妥当化、ループ処理)
モデルを作成する際に、大量のサンプルが取れずモデルの精度を評価しにくい場合があります。例えば、メーカーでの不良品予測や金融ローンの不正検 知、製薬開発での研究や症例の少ない医療研究など、発生件数が少ない事象を予分析したい場面は多々あります。このような場合、クロスバリデーションを利用 して、モデルの信頼性を向上させる方法を取ることがあります。
クロスバリデーションとは、モデルの汎化性を調べるための方法の1つで、サンプルをn個のセットに分割し,n-1個のセットを用いて,モデルの構築 を行い,残った1個のセットを用いてモデルの評価を行います。この操作を,n回繰り返し、すべてのサンプルが1個ずつ評価データとして用いられるようにく り返す方法です。各検証結果を算出し、n回の平均値でモデルを評価します。
繰り返し処理ですから、ここでもスクリプトのループ処理が活用できます。
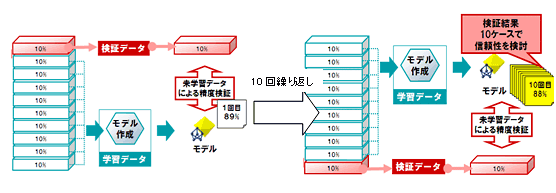
処理概要
今回は、工場の不良品発生率を予測します。生産データを読み込み、データに0~9のグループNo.を追加します。1回目の処理では、第1グループを 作成したモデルの検証用データに、残りの第2~10グループは学習用データに指定します。モデルを作成し、予測値と実績値の正解率を出すために、「正誤判 断」フィールドを追加し、当たった場合は1、外れた場合は0を設定します。「正誤判断」の平均値が予測の正解率となります。これをエクスポートします。
2回目の処理では第2グループが検証用、第1、第3~10グループが学習用となります。処理を10回繰り返します。
最後に、レコード集計ノードでエクスポートした検証結果の平均値を出し、信頼性を評価します。
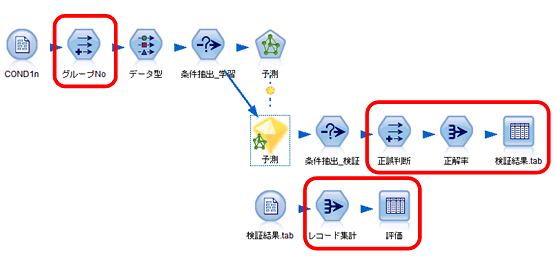
ストリームのポイントは次のとおりです。
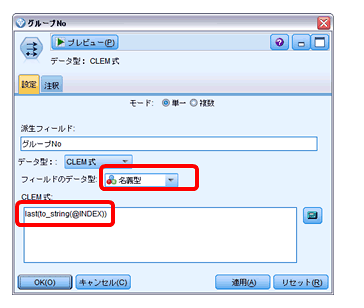
「グループNo」:CLEM式「last(to_string(@INDEX))」を設定し、インデックスの1桁目を割り当て、0~9までの10グループに分けられるようにします。
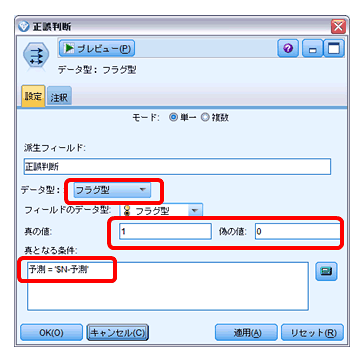
「正誤判断」:正解率を計算できるように、予測が当たった場合は1、外れた場合は0を設定します。
「正解率」:レコード集計ノードで平均値を出します。
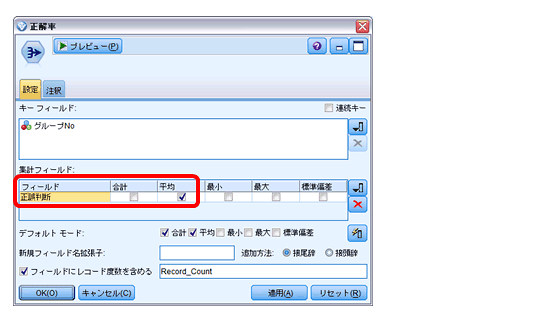
「検証結果」:結果をファイルにエクスポートします。スクリプトで保存モードを設定します。1回目は「上書き」、2回目以降は「レコード追加」とします。
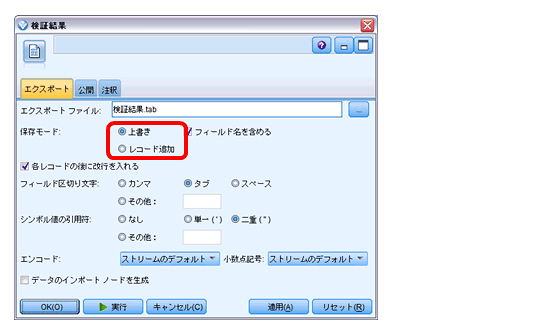
エクスポートされる「検証結果.tab」は下記の通りです。
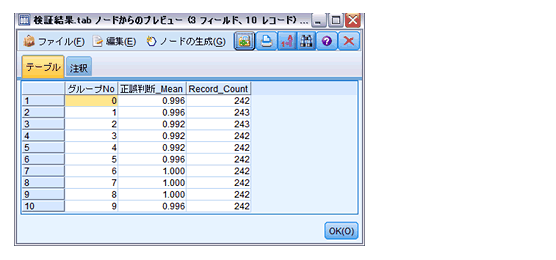
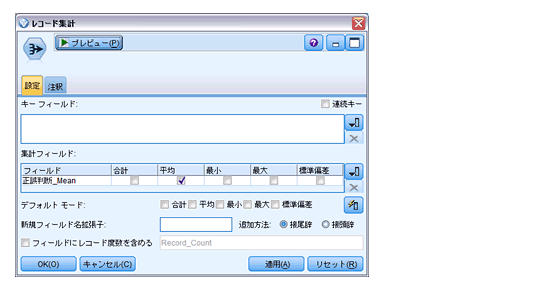
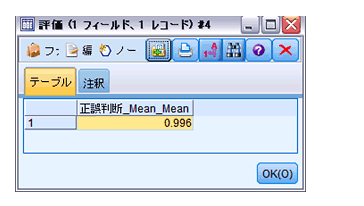
「レコード集計」:「正誤判断_Mean」の平均を出します。
「評価」:最後に評価として「正誤判断_Mean」の平均が画面に表示されます。
モデルナゲットは、各商品のモデルが適用されるようにリンク接続を保っておきます。
スクリプトは下記の通りです。
set p=0for p from 0 to 9set 条件抽出_学習:selectnode.mode = Discard /*条件を「破棄」に設定*/
set 条件抽出_学習:selectnode.condition = “グループNo = “”><^p><“””set 条件抽出_検証:selectnode.condition = “グループNo = “”><^p><“””execute ‘予測’:neuralnetworknode
if p=0 then
set 検証結果:outputfilenode.write_mode = Overwrite /*エクスポートの保存モードを「上書き」に設定*/
else
set 検証結果:outputfilenode.write_mode = Append /*エクスポートの保存モードを「レコード追加」に設定*/
endifexecute ‘検証結果’
set p=^p+1
endfor
execute ‘評価’
補足:モデルナゲットの置換
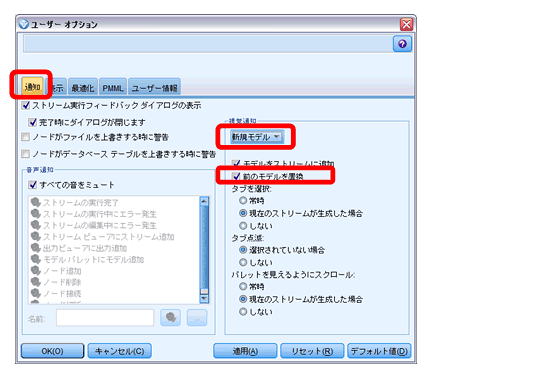
今回は、モデルナゲットを毎回繋ぎ変えずにすむように、実行する度にモデルナゲットが更新される設定をしていますが、場合によっては、スクリプト作 成時にモデル名を重複させたくないことがあります。その際は、ツール>ユーザーオプション>通知で「新規モデル」の「前のモデルを置換」にチェックし、ス クリプト内で一意の名前をつけることが可能です。

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

DB2エキスパート座談会 ~ ClubDB2の舞台裏とDb2展望 ~
Db2, IBM Data and AI, アナリティクス
今年、IBM MQ と Db2 は 30 周年。WAS(WebSphere Application Server)は 25 周年を迎えます。アニバーサリー・イヤーとして 3 製品に関わりのある方々へのインタビューを 1 ...続きを読む

IBM SPSS Statistics 書籍紹介
Data Science and AI, SPSS Statistics, アナリティクス...
SPSS関連の書籍をご紹介します。 新刊紹介 SPSSとAmosによる心理・調査データ解析(第4版)―因子分析・共分散構造分析まで [著者] 小塩 真司 出版社] 東京図書 [内容] メニューを選択するだけ ...続きを読む