SPSS Modeler ヒモトク
第4回 横持ちデータから縦持ちへの変換 – IBM SPSS Modelerスクリプトによる分析作業の効率化
2016年03月06日
カテゴリー SPSS Modeler ヒモトク | アナリティクス
記事をシェアする:
横持ちデータから縦持ちへの変換
レポートや取引先から提出されたデータを分析する場合、データが集約されすぎてModelerで分析しにくい、と感じたことはないでしょうか。デー タがクロス集計されてしまうと「横持ちデータを縦持ちに加工」する必要がありますが、項目が多いものは手作業や関数を駆使しても展開するのは困難です。と ころが、Modelerスクリプトのループ処理を利用すると、簡単に横持ちデータを縦持ちに加工できます。
今回、日別アイテム別に売上数が集計されているレポートをDBへ保存するため、横持ちデータを縦持ちに加工するケースを見てみます。
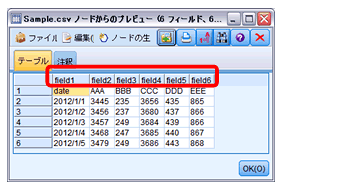
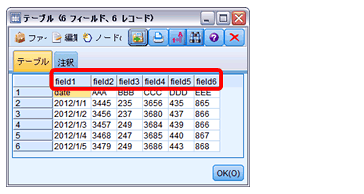
横持ちデータは、5アイテム(AAA,BBB,CCC,DDD,EEE)の値で、これを日別アイテム別に縦持ちに加工します。
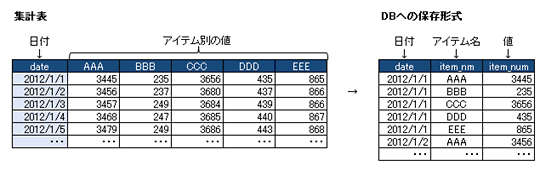
データ加工のイメージは下図の通りです。
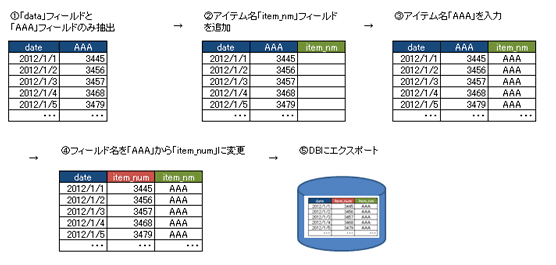
これを各フィールドを対象に繰り返します。「AAA」の処理が終わったら、抽出対象を「BBB」に変更して処理を実行し、EEEまで順次エクスポー トします。この繰り返し作業は、スクリプトのループ処理で行えます。アイテム名の入力については、アイテム名リストを作成しておき、後でレコード結合させ ます。
処理概要
ここでポイントとなるのは、最初に、1 エクスポート用のファイルを作成すること、次に、2 結合のために追加した「ID」フィールドに毎回異なるアイテム名を入力すること、3 ループ処理で抽出するフィールドを毎回変更することです。そこで、下記のストリームを作成します。ループ処理中に変更が必要な設定のみスクリプトで記述します。
ストリームをあらかじめ作成しておくことで、プログラミング作業を短時間で終わらせることが出来ますし、プログラミングが苦手なメンバーにもわかりやすくなります。
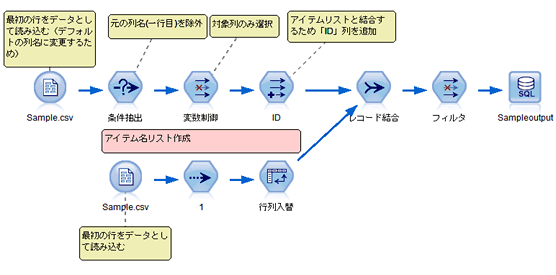
1. ストリーム:エクスポート用テーブル作成
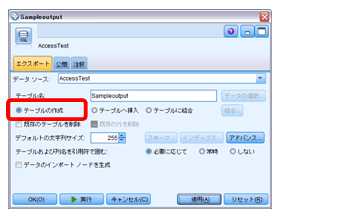
エクスポート用テーブルの作成では、テーブルを上書き(または新規作成)するかレコード追加するかがポイントとなります。今回は、テーブルのデータ を入替えることを前提とします。最初の処理では、テーブルを上書きするために「テーブルの作成」を設定し、処理を1度実行するスクリプトを記述します。 ループ処理では「テーブルへ挿入」を設定します。
今回の処理では、テーブル枠の設定と最初の対象フィールド「AAA」のデータエクスポートが行われます。
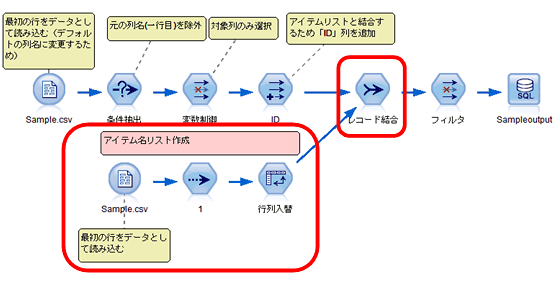
2. ストリーム:アイテム名追加
次に、アイテム名リストの作成、つまり、フィールド名をリストします。今回は入力ファイルとして「Sample.csv」を使用します。
入力ノードで「ファイルからフィールド名を取得」のチェックを外します。(後でコード結合するためにデフォルトのフィールド名を付与します。csvファイルは「field」+数字、Excelファイルは「C」+数字、というようにフィールド名が振られます)
次に、サンプルノードで最初の1行のみを読み込みます。
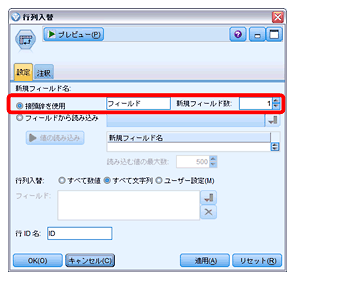
そして、行列入替ノードで横持ちになっているフィールド名を縦持ちに変換します(新規作成フィールドは「1」に設定します)。
出力すると下記のようにID(デフォルトのフィールド名)とフィールド名のリストができます。
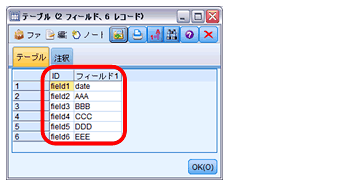
※Excelファイル入力ノードの場合は「ID」の値がC1、C2・・・となります。
レコード結合させるため、元データにも「ID」フィールドを追加して結合キーとします。その際、「AAA」のデータには「field2」を、「BBB」の場合は「field3」を「ID」の値として入力します。
3. ストリーム:対象フィールド抽出
次に、フィルタノード「変数制御」で対象フィールドのみ抽出します。その際、「BBB」以降のデータをループ処理します。
入力ノードで「ファイルからフィールド名を取得」のチェックを外し、入力データのフィールド名をデフォルトのフィールド名にします(2 のアイテムリストと結合するため)。
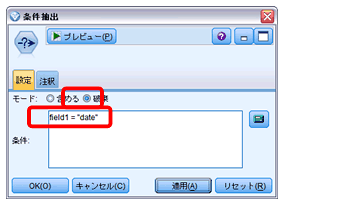
1行目(元のフィールド名)は不要なため、条件抽出で除外します。files1=”date”
4. スクリプト
フィルタノード「変数制御」で対象フィールド「field1」、「field3」を選択します。field3はループ処理の中で可変となるため、スクリプトでパラメータを使用します。
/* 変数宣言 */
var p
var Cnum
var Cnm
/* パラメータ設定*/
set p=0
/*対象2列目以降のデータエクスポート(ループ処理)*/
for p from 1 to 10
set p=^p+1
set Cnum=^p+2 /*ターゲットとなるフィールド名の数値*/
set Cnm=field><^Cnum /*ターゲットとなるフィールド名*/
抽出対象フィールドを選択します。
include.field1 = true
include.^Cnm = true
}
2 のアイテムリストと結合するため、キーとなる「ID」フィールドの値を入力します。
set ID:derivenode.formula_expr=””” >< ^Cnm >< “””
結合後、フィールド名をエクスポート用テーブルのフィールド名に変更し、不要なフィールド「ID」を除外します。
set フィルタ:filternode{
new_name. field1=’date’
new_name.^Cnm=’item_num’
new_name.フィールド1=’Item_nm’
include.ID = false
}
処理を実行します。実行後は、次の処理のために「item_num」がフィールド名が被らないように名前を元に戻し、フィールドの選択も解除します。
set 変数制御:filternode{
new_name.^Cnm=^Cnm
include.^Cnm= false
}
endfor
以上を踏まえてスクリプトを記述すると次のようになります。
/* 変数宣言 */
var p
var Cnum
var Cnm
/* パラメータ設定*/
set p=0
set 変数制御:filternode.default_include = false
/*エクスポート用テーブル作成&対象1列目のデータエクスポート*/
set Cnm=field2 /*ターゲットとなるフィールド名*/
set 変数制御:filternode{
include.field1 = true /*対象列を選択*/
include.^Cnm = true
}
set ID:derivenode.formula_expr=””” >< ^Cnm >< “”” /*アイテム名リストとレコード結合するため*/
set フィルタ:filternode{
new_name.field1=’date’ /*エクスポート先の列名設定*/
new_name.^Cnm=’item_num’
new_name.フィールド1 =’Item_nm’
include.ID = false /*不要な列を除外*/
}
set Sampleoutput:databaseexportnode.write_mode = Create /*エクスポートの保存モードを「上書き」に設定*/
execute ‘Sampleoutput’
set 変数制御:filternode{
new_name.^Cnm=^Cnm /*次の処理でフィールド名「item_num」が被らないように列名を元に戻す*/
include.^Cnm= false /*次の処理のために選択解除*/
}
set Sampleoutput:databaseexportnode.write_mode = Append /*次の処理のためにエクスポートの保存モードを「追記」に設定*/
/*対象2列目以降のデータエクスポート(ループ処理)*/
for p from 1 to 4
set p=^p+1
set Cnum=^p+2 /*ターゲットとなるフィールド名の数値*/
set Cnm=field><^Cnum /*ターゲットとなるフィールド名*/
set 変数制御:filternode{
include.field1 = true /*対象列を選択*/
include.^Cnm = true
}
set ID:derivenode.formula_expr=””” >< ^Cnm >< “”” /*アイテム名リストとレコード結合するため*/
set フィルタ:filternode{
new_name.field1=’date’ /*エクスポート先と同じ列名に変更*/
new_name.^Cnm=’item_num’
new_name.フィールド1=’Item_nm’
include.ID = false /*不要な列を除外*/
}
execute ‘Sampleoutput’
set 変数制御:filternode{
new_name.^Cnm=^Cnm /*次の処理でフィールド名「item_num」が被らないように列名を元に戻す*/
include.^Cnm= false /*次の処理のために選択解除*/
}
endfor
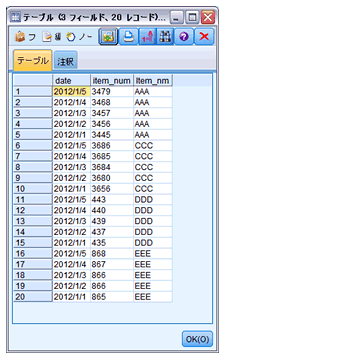
実行結果は下記の通りです。
※ループ処理中に何度も警告メッセージが出てくる場合は、ユーザーオプションで警告のチェックを外すことでメッセージが表示されないように設定できます。
ここでご紹介した「横持ちデータを縦持ちに変換する」処理は、様々な場面で応用できます。例えば、レポートとしてあらかじめクロス集計されているものでも、一旦集計直前のデータに展開することで更なる詳細な分析をするのに役立てられます。

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

DB2エキスパート座談会 ~ ClubDB2の舞台裏とDb2展望 ~
Db2, IBM Data and AI, アナリティクス
今年、IBM MQ と Db2 は 30 周年。WAS(WebSphere Application Server)は 25 周年を迎えます。アニバーサリー・イヤーとして 3 製品に関わりのある方々へのインタビューを 1 ...続きを読む

IBM SPSS Statistics 書籍紹介
Data Science and AI, SPSS Statistics, アナリティクス...
SPSS関連の書籍をご紹介します。 新刊紹介 SPSSとAmosによる心理・調査データ解析(第4版)―因子分析・共分散構造分析まで [著者] 小塩 真司 出版社] 東京図書 [内容] メニューを選択するだけ ...続きを読む