SPSS Statistics
SPSS Statistics Small Tips #07銀行の融資業務における人工知能を利用したデータ分析活用例 ~ SPSS Neural Networks ~
2022年02月10日
カテゴリー IBM Data and AI | SPSS Statistics | アナリティクス | データサイエンス
記事をシェアする:
人工知能を利用したデータ分析手法
ニューラルネットワークとは、ヒトの脳の情報処理を模倣したモデリング手法のことです。代表的なデータ分析のアルゴリズムのひとつで、人工知能を利用した複雑な数式を実現しています。ニューラルネットワークは、ネットワークを構成しているいくつかのニューロンからできており、最も一般的な次の学習は図で示すとおり、層で編成されているため多層パーセプトロン(マルチレイヤーパーセプトロン)とも呼ばれます。
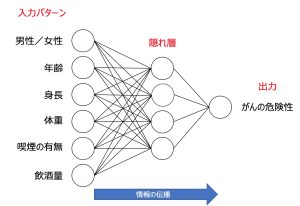
ニューラルネットワークでは、層間のニューロンが接続されることで、データのパターンや関係をネットワークが学習できるようになります。観測されたケースを1つずつ扱って、繰り返しネットワークを更新し続けることで学習を行い、学習が終わったネットワークに、新しい未知のデータを与えると、それまでの経験に基づいて予測を行うことができるようになります。
IBM SPSS Statisticsでは、多層パーセプトロン (MLP) ネットワークと放射基底関数 (RBF) ネットワークが使用できます。
それでは実際に分析してみましょう。
銀行与信
今回は銀行融資担当者が、与信の診断をするために利用する例をご紹介します。
銀行の融資担当者は、過去に債務不履行に陥った人の特徴をモデル化して信用リスクの良し悪しを判定します。過去に返済できた顧客とできなかった顧客のを区別するように、ニューラルネットワークの多層パーセプトロンのアルゴリズムを使ってデータを学習します。なおモデル作成に用いた学習データとは別に、検証するためのホールドアウトサンプルに準備し、モデルの安定化を図ります。
例で利用するデータ(bankloan.sav)はIBM SPSS Statisticsにサンプルデータとして含まれています。
1.学習用と検証用のデータを準備する
最初にランダムシードを固定しておきます。これにより毎回異なる結果になることを回避し、再現性を確保することができるようになります。
変換メニュー > 乱数ジェネレータ
乱数を常に新しく生成するか、固定するかを選択できます。テストや確認をする際などに使います。
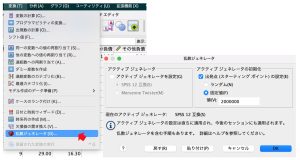
ここでは、アクティブジェネレータの初期化の出発点の設定を固定値 2000000 としておきます。同じデータで同じ固定値を使えば、同じ結果が得られます。
モデル作成をする際は、モデルの安定性を向上させるために学習用と検証用データにデータを区分するのが一般的です。学習用のデータを使用してモデル作成し、そこで使用しなかったデータで検証を行います。IBM SPSS Statisticsでは、「関数」を使って新たに変数を作成し、ケースを学習用にするか検証用にするかを分けることができます。以下の例では、データのうち70%を学習用に設定してみます。
変換メニュー > 変数の計算
目標変数は「データ区分」、数式ボックスには「RV.BERNOULLI(0.7)」と入力します。
関数グループの「乱数」を選択して、関数と特殊関数リストから「Rv.Bernoulli」をダブルクリックすると数式ボックスに関数を投入できます。
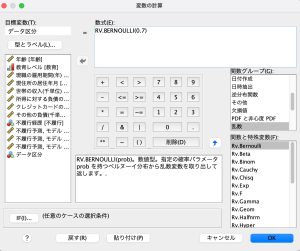
今回は乱数を発生させる関数の中でもベルヌーイという手法を使用しました。ベルヌーイを使って、70%の確率で1を発生させ、それ以外は0を記録します。「データ区分」に、1のついているケースは学習用に、0のケースは検証用に使われます。
実行の結果、全体の約70%のケースがランダムに、1.00になります。
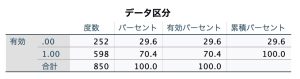
以下は、データ区分変数の度数分布表です。ぴったり70.0%とならず70.4%と端数が生じるのは乱数を利用した場合の特徴です。
では、このデータを使ってモデルを作成してみます。
2.ニューラルネットワークで分析を行う
分析メニュー> ニューラルネットワーク > 多層パーセプトロン
変数タブをクリックします。
従属変数に予測する値である、不履行経歴[不履行]変数を投入し、因子に教育レベル[教育]変数を入れます。そして、データ区分と不履行予測変数以外の変数を共変量に投入します。

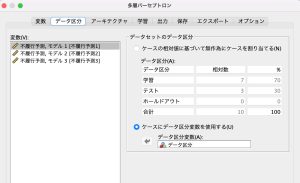
データ区分タブをクリックします。
「ケースにデータ区分変数を使用する」を選択し、データ区分変数を投入します。
これで、学習用・検証用データをデータ区分変数で識別するようになります。
出力 タブをクリックします。
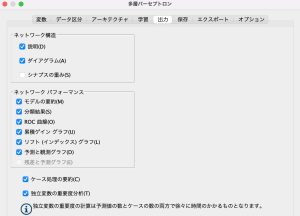
「ネットワークパフォーマンス」の全ての項目にチェックを入れ、ここでは「独立変数の重要度分析」にチェックを入れ、出力結果を実際に見てみましょう(重要度分析は変数の数やケース数によっては時間がかかるため注意が必要です)。
3.出力結果を見る
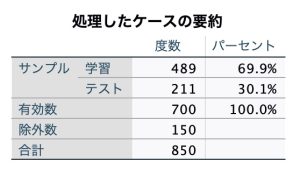
処理したケースの要約から確認しましょう。ここでは有効数の700ケースに対して、69.9%にあたる489ケースが学習用データとして、残り30.1%の211ケースが検証用データ(テスト)として使われたことが分かります。
ネットワーク情報では、入力層、隠れ層、出力層別の情報が確認されます。ここでは入力層のニューロンは12個であり、隠れ層のニューロンが4個、出力層のニューロンは2個であることがわかります。
カテゴリ変数の場合、各カテゴリが1ニューロンとしてカウントされます。そのため、入力層は、左に表示されている7個の共変数と、因子である教育レベルの5つのカテゴリを合わせて、ニューロンの数は12個となります。

ダイヤグラム出力をみてみます。入力層には予測(独立)変数が含まれています
隠れ層には、観測不可能なユニット(処理の単位=ニューロン)が含まれます。隠れ層にあるそれぞれのユニットの値は、予測変数の結合関数です。
出力層には、従属変数のカテゴリが含まれます。従属変数の不履行履歴には、不履行:なし=0と不履行:あり=1の2つの値が記録されています。出力層にあるそれぞれのユニットの値は、隠れ層の結合関数です。

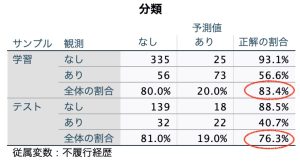
分類ではネットワークを使った結果が出力されています。まず学習用ケースを使ったものでは、実際に不履行がある129データ(56+73)中、73データが不履行ありで予測が的中しました。また実際に不履行がない360データ(335+25)中、335データが不履行なしで予測の通りになっています。つまり全体では学習用489データのうち(335+73)、の408データが正しく予測されており、83.4%が正解になっています。そしてモデル作成には使用しなかった検証用テストデータで当てはめた正解率は76.3%でした。
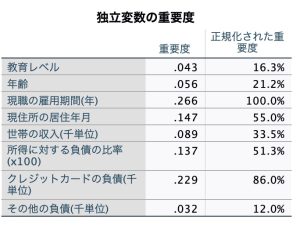
独立変数の重要度ではどの変数の重要度が高かったのかが出力されます。これは計算が複雑で出力に時間がかかりますが、業務経験と照らし合わせてモデルの信憑性を確認したり、注目するべき変数を見直すのに役に立ちます。
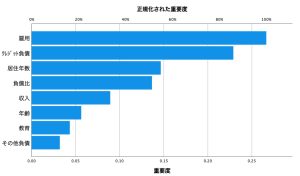
また、正規化された重要度のグラフでも確認できます。ここでは、1.現職の雇用期間 2.クレジットカードの負債金額 3.現住所の居住年月 が不履行「あり・なし」を予測するのに重要である上位3位の変数だということがわかりました。
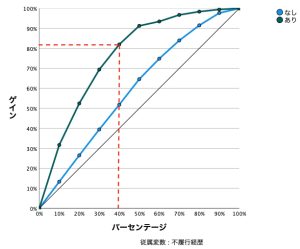
累積ゲイングラフやリフトグラフを使用すると、ある特定の結果を予測するモデルの精度はどの程度なのかを視覚的に評価することができます。
累積ゲイングラフは、ケースの合計数のパーセントを目標にすることで、特定のカテゴリ「ゲイン」のケースの総数パーセントを示します。例えば、不履行ありの緑ラインに注目すると、ネットワークでデータセットをスコアリングし、不履行「あり」と予測された全てのケースを確信度でソートした場合(不履行「あり」の確度が高い順に並べる)、上位40%が、実際に不履行がある全ケースの約82%を含むと期待できることを示しています。対角線はベースラインと呼ばれ、40%のケースを取り出せば、実際に不履行がある全ケースの40%が「あり、もしくは、なし」であるという基準ラインを示しており、これはある意味、予測モデルを使わなくても予想することができるレベルのラインです。ベースラインから上にあればあるほど、ゲインが大きくなり、確度の高い予測ができていることになります。
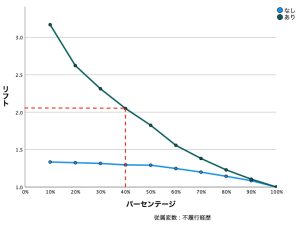
リフトグラフは、累積ゲイングラフから導き出すことができます。リフト値は累積ゲイン値のベースラインに対する比率に対応している指標です。例えば、緑ラインの不履行「あり」の40%におけるリフトは、82%/40%(40%におけるゲイン82%÷40%におけるベースライン40%)=2.05になります。累積ゲイングラフの情報を別の視点で見ることができます。
今回は銀行与信予測の例をご紹介いたしましたが、ニューラルネットワークの手法は様々な予測に使われています。
ニューラルネットワーク活用例
・商品需要予測:ニューラルネットワークを利用した商品需要予測の最適化
・商品開発:調味料の開発にニューラルネットワークを適用、缶コーヒーのにおいの官能評価
・エレベーター運転方式制御:エレベーターの最適スケジューリング制御
・自然言語処理:ニューラルネットワークによる学習を用いた自然言語の処理
・手書き数字の認識:ニューラルネットワークによる手書き数字認識システム
・顔画像認識:目、口、鼻のカテゴリを形成してニューラルネットワークで顔を認識
まとめ
いかがでしたか。このようにデータを学習用、検証用に分け、人工知能を使った高度なデータ分析手法を使いデータ予測分析を可能にするのが、SPSS Neural Networksです。
ぜひ、現在行っていらっしゃる予測分析手法の1つに加えてみてください。
さあ、さっそくはじめてみませんか。
SPSS Statistics 無料評価版 https://www.ibm.com/jp-ja/products/spss-statistics
お問い合わせは SPSS営業部まで jpsales@jp.ibm.com
→SPSS Statistics Small Tips バックナンバーはこちら

牧野 泰江
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

敷居もコストも低い! ふくろう販売管理システムがBIダッシュボード機能搭載
IBM Data and AI, IBM Partner Ecosystem
目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

テクノロジーが向かう先とは〜中長期テクノロジー・ロードマップ
IBM Cloud Blog, IBM Data and AI
IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む