

























当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
IBM Cloud Blog
クラウドネィティブにおけるサービスメッシュとカオスエンジニアリングについて
2022年12月01日
カテゴリー IBM Cloud Blog | IBM Cloud News | IBM Partner Ecosystem
記事をシェアする:
こんにちは。IBM Cloud Platform Technical Sales坂田です。
クラウドネィティブ時代のシステム信頼性を向上させる新しい手法であるカオスエンジニアリング及びマイクロサービスの連携管理基盤であるサービスメッシュをテーマに話を進めていきます。
はじめに 〜カオスエンジニアリングについて
当職が関わるシステムでOpenShift/Kubernetesの内蔵ディスクが一杯になり稼働するアプリケーションが数日不安定になるという障害に見まわれました。この際ある人から”何故事前にテストして確認しなかったのか”と問われました。
これはシステム用ディスクの使用率が100%になれば問題が発生することを漠然と理解はしていたが、標準の内部レジトリィの増大により”ディスクが一杯になる”可能性の認識はなかったというものです。通常の障害テストは理解し認識している既知の事象に対して想定されている結果を確認するものです(例えばノード障害に対してDeploymentによりpodが他ノードに引き継がれるなど) 昨今の分散・複雑化したシステムでは、これまでのモノシリック・オンプレミス環境と異なり全てのコンポーネントに対して障害ケース/影響範囲を事前に洗い出し対策をたてることは難しくなっています。
システムがマイクロサービス化してサービス連携が複雑化するとともにパブリッククラウドを利用したシステムはユーザーが設計管理できる領域が小さくなりブラックボックス化、またサービス仕様の変更も発生してユーザー側で全ての障害ケース/影響を洗い出すことは困難です。このような環境下で障害を完全に無くす方法を探すのではなく、システムに対してあえて障害を起こし(Fault Injection)それに対する実験(システムの挙動を観察し予測不可能な未知の事象を発見)を繰り返し行うことで、システム全体の信頼性を向上させるメソドロジーがカオスエンジニアリングです。
動画配信サービスを提供するNetflixが導入したことで注目されるようになった手法で「本番稼働中のサービスにあえて擬似的な障害を起こすことで、実際の障害にも耐えられるようにしよう」という取り組みです。
小規模の障害を意図的に発生させ、特定のサービスが一時的に使用不可になった際、システムがどう対応するかを把握するために実施するものでトラブル対処の知見を蓄積していき、サービスを大規模化したときの安定的な運用につなげていくものです。
カオスエンジニアリングはよく予防接種に例えられます。ウイルスの毒性を弱めたワクチンを注射することで人体の免疫を高めるのに対してユーザー影響軽微の障害を意図的に発生させてシステムの障害への耐性を高めます。
従来のテストとカオスエンジニアリングの比較表をまとめました。
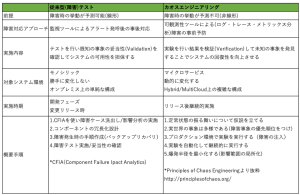
サービスメッシュについて
CNCF(Cloud Native Computing Foundation)の提唱するクラウドネィティブアプリ実現のための技術要素としてマイクロサービス、コンテナー、サービスメッシュ、継続的デリバリが挙げられています。
この中のマイクロサービスを管理・運用するサービスメッシュは、Fault Injection(障害注入)の機能を提供しておりカオスエンジニアリングの実践も可能です。
当職の関わったシステムでは運用管理の共通基盤としてRed Hat Open Shift on IBM Cloudを利用しており、アプリケーションのマイクロサービス化を進めていることからサービス連携を可視化してシステム全体の信頼性を高めるためにサービス間連携を制御するサービス・プラットフォーム・レイヤー(サービスメッシュ)を構築しました、今日はこの時の経験に基づいてサービスメッシュ及びカオスエンジニアリングを紹介します。
アプリケーションの開発生産性・保守性を高めるためにモノシリックなサービスから複数の疎結合されたマイクロサービスに分解すると,インクリメンタル開発が促進され個別機能単位でのリリース/スケールアウトが可能になる一方で、アプリ実装/運用の複雑性がましサービス間の依存関係、システム全体の把握が難しくなり障害発生時の問題判別が困難になります。あるサービスで発生した障害や遅延が広範囲に連鎖してシステム全体に影響を及ぼす可能性もあります。セキュリティ面でもリクエストが複数のサービスを跨ぐために呼び出し元のサービス認証/認可、通信路の暗号化も重要になってきます。こうした環境下で効率よくサービス管理する手法の一つとして利用されるのがサービスメッシュです。
サービスメッシュとはクラウドネィティブ環境下において、各サービス間連携を一元的に運用・管理する基盤であり、主要な機能は以下のものです。
1.サービスディスカバリ
依存関係のあるサービスに対する接続情報を照会したり,
あるサービスにおいてシステム構成(ホスト追加など)が変更になった場合、
依存関係にあるサービスに対して、接続情報の更新を通知します。
2.トラフィック制御と管理
サービスへのアクセスの割り振りを設定に基づいて変更したり、サービスからの戻り値を変更したりするなどサービス間の通信を制御する仕組みです。条件に応じたトラフィックの分割(Traffic Steering)、指定した割合に応じたトラフィックの分離(Traffic Splitting)が可能で、新旧バージョンの振り分けに利用することでカナリアリリースやA/Bテストに活用できます。
またカオスエンジニアリング実践のためのFault Injection(障害注入)もこのカテゴリに含まれます。特定のサービスへのアクセスについてレスポンスが返ってくるまでに一定の遅延をわざと発生させたり、必ずHTTPステータスコードが500番台のエラーを返すといった疑似的な異常状態を作り出します。
3.障害の分離(Fault Isolation)
あるサービスで発生した障害の影響範囲を局所化してシステム全体に影響を及ぼすのを防ぎシステム全体の回復性を高めるものです。Circuit Breakerはクラウドの耐障害性処理デザインパターンの一つでサービスメッシュでも機能を提供します。1つのサービスのタイムアウトが連鎖してシステム全体のスローダウンが発生するのを防ぐために、(電気のブレーカーが異常を検知すると自動的に通電を遮断するように)一定期間は障害が発生しているサービスのアクセスを遮断してすぐにエラーを返すようにします。サービスの回復を検知すると、回復したサービスへのアクセスを元の通りに回復します。
4.可観測性(Observatory)
マイクロサービス化されたシステムでは通常1つのリクエストが複数サービスをまたがります。サービス毎に取得したログをリクエスト単位につなぎ合わせてリクエスト全体の処理の流れを把握(分散トレーシング)することで、障害や遅延が発生しているサービスを特定することが容易に行えます。サービスメッシュ自体はログデータ収集のみを担当して、可視化ツールとしてJaegarやZipkinなどのオープンソース・ソフトウェアを利用することが多いです。
5.セキュリティ
サービスが他のサービスを呼び出すときの認証・認可やセキュアな通信を管理する機能です。サービスの呼び出し側と呼び出される側を相互に認証するためのmTLS(相互TLS)も実現可能で個別に自前で証明書を準備・管理する手間が省けます。
下記がサービスメッシュを実装するツールの比較表になります。
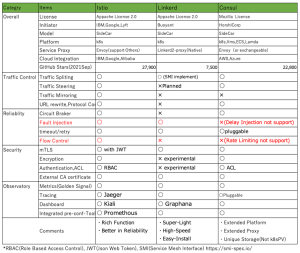
IstioはGoogle、IBM、Lyftによって開発されオープンソース・プロジェクトとして公開されています(https://istio.io/)これまでの利用実績も多く機能も豊富です、
Linkerdもオープンソース・プロジェクト(https://linkerd.io/)でCNCFのプロジェクトの一つでもあります。機能を絞り軽量・小型・高速/導入簡単をその特徴とします。V2からKubernetesのみが稼働環境になっています。
Consul(https://www.consul.io/)はHashiCorpが開発、k8s以外のPlatformでも稼働、サーバー/クライアントの構成になります。データセンター間などのクラスター間も相互接続・管理可能です。
ここではDelayタイプのFault Injection, Rate Limitingがシステム要件に上がっており、またROKSのOperatorから標準/簡易導入できることからIstioを選択しました。
Istioアーキテクチャーについて
下記がIstioの全体アーキテクチャー図になります。
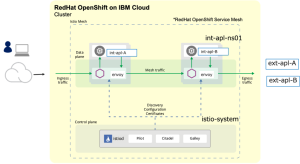
サービスメッシュは、Control plane(サービスメッシュ全体の管理・制御)と
Data plane(ユーザーアプリおよびenvoy proxy稼働)からなります。
サービスメッシュを実現するコンテナ構成はサイドカーパターンになり
プロキシー機能を提供するコンテナ(envoy)をアプリ・コンテナに並行稼働させるので
アプリケーション・コードを(基本的には)変更することなく、必要な機能を提供します。
Control planeにあるistiodはPilot,Citadel,Galleyの3つから構成されます。
Pilot: Envoyと連携してサービスディスカバリとトラフィック制御・管理を担当
Citadel: 認証局として、秘密鍵の管理や証明書の発行を行う
Galley: Istioの設定を管理
外部から入ってくるトランザクションをingressにてユーザーアプリint-apl-A、int-apl-Bに振り分け、Egressにて外部サービス(図中ext-apl-A,ext-apl-B)の呼び出しの制御を行います、Egress経由せずに外部サービスを自由にアクセスすることも可能です(Passthrough:デフォルト機能)
ISTIOにはアップストリーム版とRed Hat OpenShift Service Mesh(Operatorによる標準提供/導入)の2つがあります。OpenShift Operatorにより簡単に導入できて、Kiali(ダッシュボード) Jaegar(分散トレーシング)のOSSもすぐに使えることからRed Hat OpenShift Service Meshを選択しました。
Istioリソース構成について
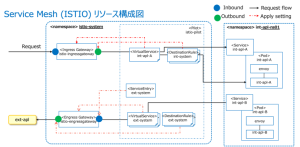
図中右側のint-apl-ns01ネームスペース(Data plane)内でint-apl-A ユーザーアプリが稼働、envoyがサイドカーとして並行稼働します。左側のistio-systemネームスペース(Control plane)内にIstioリソースを配置します。
Gateway:
サービスメッシュと外部ネットワークのエッジ部分を定義しGatewayにVirtual Serviceを関連づけ、転送先を制御します。インバウンドはIngress Gateway, アウトバウンドはEgress Gateway (オプション)になります。
Virtual Service:
各ユーザーアプリ・サービス(図中int-apl-A, int-apl-B,ext-apl)へリクエストをルーティングするための定義です
トラフィック振り分けの条件指定や割り振りの重みづけはFault InjectionでのFaultの具体的な内容などはここで定義します
本プロジェクトではアクセス可能なコンテキストルートの絞り込みや外部サービス呼び出し時のtimeout/retryの設定等をしています。
Service Entry:
Mesh外のリソース(図中ext-apl)への要求を定義します。
Destination Rule:
ルーティングが発生した後のトラフィックに対する動作を定義します。
トラフィック暗号化の方法、また複数バージョンを持つアプリケーションのルーテンングなどはここで指定します。当プロジェクトではCircuit Braker設定に利用しています。
カオスエンジニアリング実践からIstio定義まで(サンプル例)
ここでは実際のイメージを掴んでいただくためにカオスエンジニアリング実施からIstioのFault Injectionの定義までの流れを紹介します。
冒頭に照会したカオスエンジニアリングの実施手順(表中)に則り、最初に定常状態の振る舞いの仮説(Build a Hypothesis around Steady State Behavior https://principlesofchaos.org/ )をたてます。まずビジネスKPI(Key Performance Indicator)や4 つのゴールデンシグナルを使って定常状態を定義します、ここではゴールデンシグナルのメトリックスを使い、当システムのSLO(Service Level Object)等参考に”このシステムの定常状態はエラー率0.5%以下, スループット20https request/sec以上である”と定義します。
次に過去のインシデント(事象)を参考に、全体アーキテクチャー/構成図も踏まえ複数の仮説バックログ(障害事象xxxが発生しても定常状態を遺脱しない)を作成して、その事象の潜在的影響/発生頻度を考慮して優先順位をつけ最終的に実験を行う仮説を決定します(Vary Real-world Events: 実世界の事象は多様である) 今回の場合は将来的にリモートSaaSへの移行の可能性のある共通認証サービスが5秒遅延することを想定し「この共通サービスが5秒遅延しても定常状態に影響を与えず、”error率0.5%, 20https request/sec”のベースラインを維持する」という仮説を実験することに決定しました。
この共通サービスを呼び出すサービスは(timeout/retry値等)様々でその5秒遅延の影響は予測することは困難であるが定常状態は維持できそうであるという仮説です.
また実験する環境は最初は本番業務に極力影響を与えないよう検証環境で実施しかつ遅延するトラフィックの割合を徐々に増やしていく方法をとることにします。(Minimize Blast Radius:爆発半径の最小化)
検証環境でVirtual Service等のリソース定義追加により障害の注入を行い標準ツールのKiali, Jaegar等により結果を検証します。仮説が正しいことを確認するのはもちろんですが、検証の過程でアプリの影響範囲、直接的なタイムアウトエラー以外に新たな潜在的問題を発見できるかもしれません。結果如何により呼び出しサービス含めてtimeout/retry値の調整やCircuit Brakerの適用、アーキテクチャー見直し等の対応を検討することになります。
5秒遅延を発生させる共通サービスint-apl-XのVirtual Serviceとingress Gatewayの定義例です。

Gateway:
Ingress Gatewayを定義します。
Virtual Service:
fixedDelay値で遅延時間を指定します。
Percent値でDelayを適用するトラフィックの割合を指定します。
ここでは最初は10を指定して業務影響を見ながら増やしていきます。
おわりに
Netflixがカオスエンジニアリングを試み始めた初期にAWS EC2等のコンポーネントをランダムに停止させる実験を実施したり、カオス(混乱・混沌)の言葉自体から単にカオス的な状況をシステムに加えると思われる人もいるかもしれません。その本質はカオス的な振る舞いをする複雑なシステムに対して、影響範囲を見極めた上で制御された計画的な障害をシステムに慎重に加えて振る舞いを観察することです。
制御された障害(コンポーネント停止、ネットワーク遅延など)をシステムに注入することで、事前にシステムに潜む潜在的な脆弱性を発見し改善することで、回復力を高め
大規模障害になるのを防ぎます。
参考資料
Red Hat OpenShift on IBM Cloud のサービス・メッシュ
https://cloud.ibm.com/docs/solution-tutorials?topic=solution-tutorials-openshift-service-mesh&locale=ja
Istio Fault Injection
https://istio.io/latest/docs/tasks/traffic-management/fault-injection/
GitHub Istio Fault Injection
https://istio-releases.github.io/v0.1/docs/tasks/fault-injection.html
カオスエンジニアリング オライリー・ジャパン
https://www.oreilly.co.jp/books/9784873119885/
カオスエンジニアリング入門 C&R研究所
https://www.c-r.com/book/detail/1443
マイクロサービスの仕組み 翔泳社
https://www.shoeisha.co.jp/book/detail/9784798165431
著者:

坂田 直紀
日本アイ・ビー・エム株式会社
クラウド事業本部
テクニカル・セールス
More IBM Cloud Blog stories

ラウンドテーブルを通じてPwDA+Week2024を振り返る(後編) | インサイド・PwDA+9
IBM Partner Ecosystem
日本IBMグループのダイバーシティー&インクルージョン(D&I)活動の特徴の1つに、当事者ならびにその支援者であるアライが、自発的なコミュニティーを推進していることが挙げられます。 そしてD&Iフ ...続きを読む

ラウンドテーブルを通じてPwDA+Week2024を振り返る(前編) | インサイド・PwDA+9
IBM Partner Ecosystem
日本IBMグループのダイバーシティー&インクルージョン(D&I)活動の特徴の1つに、当事者ならびにその支援者であるアライが、自発的なコミュニティーを推進していることが挙げられます。 そしてD&Iフ ...続きを読む

風は西から——地域から日本を元気に。(「ビジア小倉」グランドオープン・レポート)
IBM Consulting, IBM Partner Ecosystem
福岡県北九州市のJR小倉駅から徒歩7分、100年の歴史を刻む日本でも有数の人気商店街「旦過市場」からもすぐという好立地にグランドオープンしたBIZIA KOKURA(ビジア小倉)。 そのグランドオープン式典が2024年1 ...続きを読む