IBM Data and AI
実践!IBM Cloud Pak for Dataチュートリアル (Multicloud data integration後編)
2022年07月22日
カテゴリー DataOps | Hybrid Data Management | IBM Cloud Blog | IBM Data and AI | IBM Watson Blog
記事をシェアする:
前編からの続きです。
前編はこちら→ https://www.ibm.com/blogs/solutions/jp-ja/practice-cp4d-04/
3-5. Step 5: Add a Transformer stage
LOAN_AMOUNT列とCREDITCARD_DEBT列を合計して新しい列を作成するTransformerステージを追加します。
- Transformerステージをキャンバスにドラッグし、Join_on_emailノードとSequential_file_1ノードの間のLink_5の上にノードをドロップします。
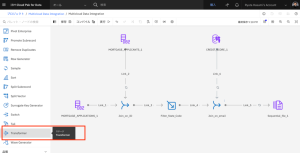
- トランスフォーマー ノードをダブルクリックして、設定を編集します。
- 出力タブをクリックします。
- [列の追加]をクリックします。
- 出力タブをクリックします。
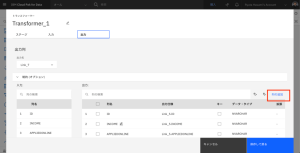
- 列のリストの一番下までスクロールして、新しい列を確認します。
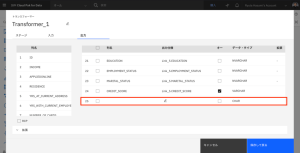
- 列の名前を TOTAL_DEBT にします。
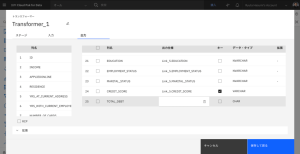
- 行の導出列の鉛筆のアイコンをクリックします。
- 電卓アイコンをクリックし、式ビルダーを開きます。

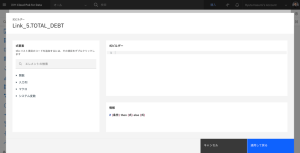
- LOAN_AMOUNT を検索し、その列名をダブルクリックして式に追加します。
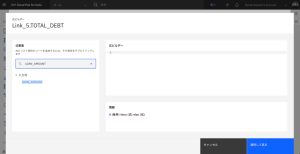
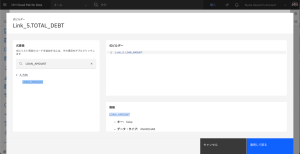
- プラス記号 + を入力します。
- CREDITCARD_DEBT を検索し、列名をダブルクリックして、式に追加します。
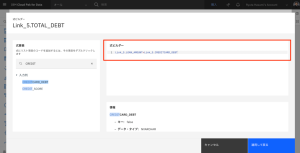
- 最終的な式が LOAN_AMOUNT + Link_5.CREDITCARD_DEBT になっていることを確認します。
- [適用して戻る]をクリックし、[Transformer_1]ページに戻ります。
- [保存して戻る]をクリックして、キャンバスに戻ります。
Step5は以上です。必要な列の追加ができました。
3-6. Step 6: Add MongoDB data
MongoDBデータベースに新しいデータアセットコネクターを追加して、フローに金利を組み込みます。
- ノードパレットで、「コネクター」セクションを展開します。
- CREDIT_SCORE_1 ノードの横のキャンバスに Asset ブラウザ コネクタをドラッグします。
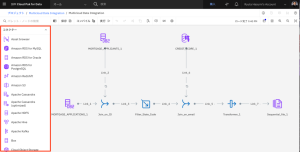
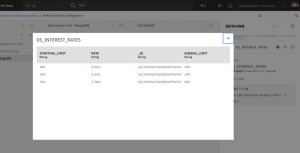
- アセットを見つけるには、Connection > Data Fabric Trial – Mongo DB > DOCUMENT > DS_INTEREST_RATESを選択します。
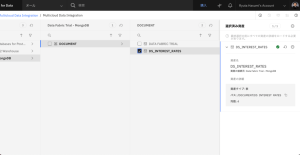
- 目の形のアイコンをクリックすると、各クレジットスコアの範囲の金利をプレビューできます。STARTING_LIMIT と ENDING_LIMIT 列の値を使って、申込者のクレジットスコアに基づいて適切な金利をルックアップすることになります。ID列は不要なので、次のステップで削除します。
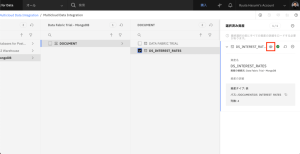
- [追加]をクリックします。
Step6は以上です。データソース(MongoDB)との接続を追加できました。
3-7. Step 7: Add a Lookup stage
各申請者のクレジットスコアに基づいて、適切な金利を検索するため、Lookupステージを追加し、各金利の開始および終了クレジットスコアの制限の範囲を指定します。
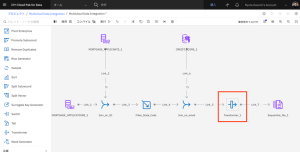
- Lookupステージをキャンバスにドラッグし、Transformer_1ノードとSequential_file_1ノードの間のLink_7ノードの上にノードをドロップします。
- DS_INTEREST_RATES_1コネクターをLookup_1ステージに接続します。
- DS_INTEREST_RATES_1 ノードをダブルクリックして、設定を編集します。
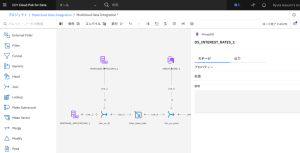
- 出力タブをクリックします。
- [列]セクションを展開し、[編集]をクリックします。
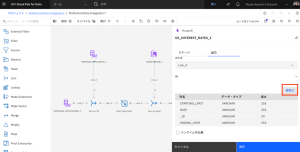
- ID列を選択します。
- [削除]アイコンをクリックして、この不要な列を削除します。
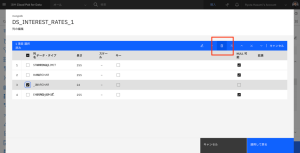
- [適用して戻る]をクリックして、DS_INTEREST_RATES_1ノードの設定に戻ります。
- [保存]をクリックして、DS_INTEREST_RATES_1 ノードの変更内容を保存します。
- Lookup_1 ノードをダブルクリックして、設定を編集します。
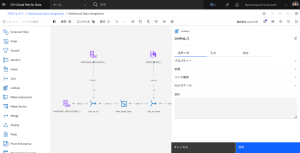
- プロパティセクションを展開します。
- [範囲を列に適用]フィールドで、「CREDIT_SCORE」を選択します。参照リンク、オペレーター、範囲列フィールドが表示されます。
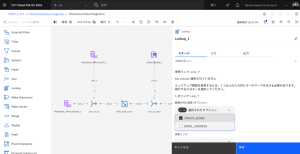
- [参照リンク]では、[Link_9]を選択します。
- 最初のオペレーターには「<」を選択します。
- 最初の範囲列カラムには、ENDING_LIMITを選択します。
- 2つ目のOperatorには、>を選択します。
- 2つ目のRangeカラムは、STARTING_LIMITを選択します。
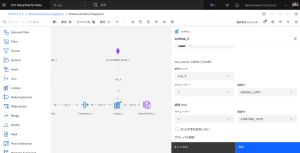
- 出力タブをクリックします。
- [列]セクションを展開し、編集をクリックします。
- STARTING_LIMIT、ENDING_LIMITの列を選択します。
- [削除]アイコンをクリックし、これらの不要な出力を削除します。
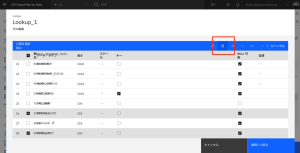
- [適用して戻る]をクリックして、Lookup_1ノードの設定に戻ります。
- [保存] をクリックし、Lookup_1 ノードの変更を保存します。
Step7は以上です。ルックアップ処理の定義ができました。
3-8. Step 8: Edit the Sequential file node and run the DataStage flow
Sequential fileノードを編集し、プロジェクトのデータ資産として最終出力ファイルを作成し、DataStageフローをコンパイルして実行します。
- Sequential_file_1ノードをダブルクリックして、設定を編集します。
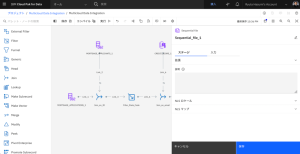
- [入力]タブをクリックします。
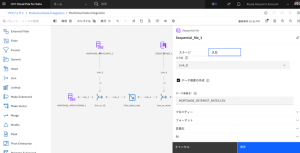
- [データ資産の作成] を選択します。

- データ資産名に、「CSV」と入力します。
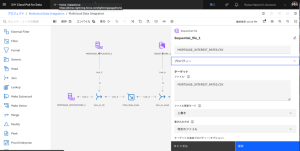
- [プロパティー] セクションを展開します。
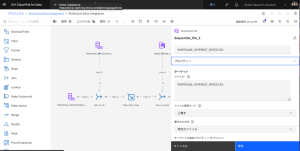
- [ターゲット]の[ファイル]に、「CSV」と入力します。

- [保存]をクリックします。
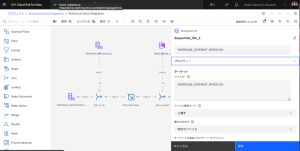
- [実行]をクリックすると、DataStageフローがコンパイルされ、実行されます。

- ツールバーの[ログ]をクリックすると、フローの進行状況が表示されます。
Step8は以上です。ETLフローの修正が完了し、データをCSVファイルに出力できました。
ここまでで、下記の流れでフローを修正したので、ローン申請、申請者情報、クレジットスコア、適用金利を含むCSVを出力することができました。
- 修正前ETLフローで、ローン申請データと申請者データを結合し、州コードでフィルタリングして、CSVファイルに出力する処理が記載されていることを確認
- PostgreSQL上のクレジットスコアデータと接続
- クレジットとローンの負債を合算する列を追加
- MongoDB上のクレジットスコア別の適用金利データと接続、クレジットスコアでルックアップする処理を追加
3-9. Step 9: Create a catalog
Golden Bankの他のデータ・エンジニアやビジネス・アナリストは、住宅ローン金利にアクセスする必要があります。カタログへのアクセスがまだない場合は、以下の手順に従ってカタログを作成し、そこに金利データセットを公開します。
(Cloud Pak for Data as a Service の無償プランではカタログを1つしか作成できません。既にカタログを作成されている方は、この Step 9 をスキップして Step 10 へ進んでください。)
- Cloud Pak for Dataのナビゲーションメニューから、[カタログ] > [すべてのカタログを表示]を選択します。
- [カタログの作成] をクリックします。
- [名前]に「Mortgage Approval Catalog」と入力します。カタログをクラウドオブジェクトストレージインスタンスに関連付けるよう指示されたら、リストからクラウドオブジェクト ストレージを選択します。他のすべてのフィールドはデフォルト値のまま設定します。
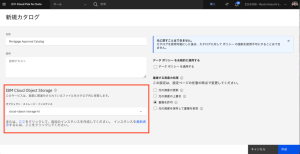
- [作成] をクリックします。
Step9は以上です。データカタログを作成できました。
3-10. Step 10: View the output and publish to a catalog
プロジェクト内の出力ファイルを表示し、カタログに公開します。
(既にカタログが作成されていて Step 9 をスキップした方は、このステップで指定するカタログには既存のカタログを指定してください。)
- Cloud Pak for Dataナビゲーションメニューから、[プロジェクト] > [すべてのプロジェクトの表示]を選択します。
- Multicloud Data Integration プロジェクトを開きます。
- [資産]タブで、[データ] > [データ資産]をクリックします。
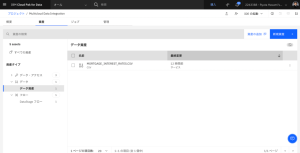
- MORTGAGE_APPLICANTS_INTEREST_RATES.CSV ファイルを開きます。
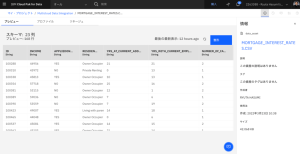
- 右側にスクロールして、各データ入力の最後に金利が表示された統合データを確認します。
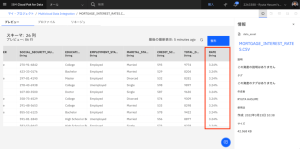
- トップメニューの[Multicloud Data Integration]をクリックし、プロジェクトに戻ります。
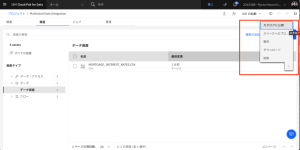
- [資産]タブで、CSVファイルの行の最後にあるオーバーフローメニューをクリックし、[カタログに公開]するを選択します。
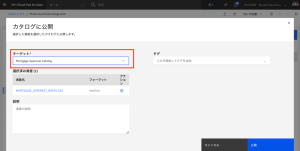
- リストから[Mortgage Approval Catalog]を選択し、[公開]をクリックします。(既に作成したカタログがあって Step 9 をスキップした方は、ここで指定するカタログには、既存のカタログを指定してください。また、以下の作業では Mortgage Approval Catalog を、そのカタログ名に置き換えて進めてください。)
- Cloud Pak for Data のナビゲーションメニューから、[カタログ] > [すべてのカタログを表示]を選択します。
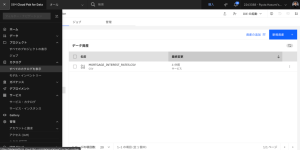
- Mortgage Approval Catalog(住宅ローン承認カタログ)を開きます。
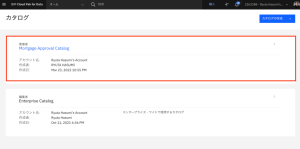
- 「Mortgage」を検索します。
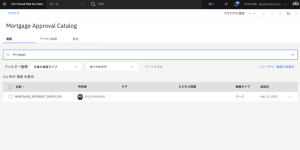
- MORTGAGE_APPLICANTS_INTEREST_RATES.CSV ファイルを開きます。
- 資産タブをクリックして、データを表示します。
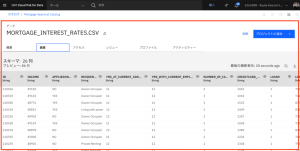
Step10は以上です。データカタログにETLフローで出力したデータを公開できました。
ここまでの操作で、加工/統合した成果物のCSVファイルを分析ユーザーも使うことができるようになりました。
おわりに
ここまでで、Multicloud data integration のチュートリアルについて、日本語で手順をご紹介しました。
Data Fabricを実現するCloud Pak for Dataのいくつかの機能のうち、「様々なデータソース上にある必要なデータを統合する」、「データ統合/加工処理をGUIで使って簡単に開発する」、「データサイエンティストが必要なデータを見つけられるようにデータカタログに公開する」という操作を体験するものでした。同様のシナリオを使用して、機械学習モデルの構築や評価などを体験するチュートリアル(MLOps and trustworthy AI編)もございます。なおチュートリアル全般についてはこちらでご紹介しています。
是非、Data Fabricの他のチュートリアルもお試しいただき、Cloud Pak for Dataでデータ活用を一気通貫で実行する流れをご体験ください!

蓮見 竜太
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

岡崎 史博
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

セキュリティー・ロードマップ
IBM Cloud Blog
統合脅威管理、耐量子暗号化、半導体イノベーションにより、分散されているマルチクラウド環境が保護されます。 2023 安全な基盤モデルを活用した統合脅威管理により、価値の高い資産を保護 2023年には、統合された脅威管理と ...続きを読む

量子ロードマップ
IBM Cloud Blog
コンピューティングの未来はクォンタム・セントリックです。 2023 量子コンピューティングの並列化を導入 2023年は、Qiskit Runtimeに並列化を導入し、量子ワークフローの速度が向上する年になります。 お客様 ...続きを読む

ハイブリッドクラウド・ロードマップ
IBM Cloud Blog
コンポーザブルなアプリケーション、サービス、インフラストラクチャーにより、企業は複数のクラウドにまたがるダイナミックで信頼性の高い仮想コンピューティング環境の作成が可能になり、開発と運用をシンプルに行えるようになります。 ...続きを読む