IBM Data and AI
実践!IBM Cloud Pak for Dataチュートリアル (Multicloud data integration前編)
2022年07月22日
カテゴリー DataOps | Hybrid Data Management | IBM Cloud Blog | IBM Data and AI | IBM Watson Blog
記事をシェアする:
はじめに
「IBM Cloud Pak for Dataを手軽に試してみたい」という要望にお応えして、クラウド環境で手軽にお試しいただけるチュートリアルが完成しました。チュートリアル全般については
こちらの記事 →https://www.ibm.com/blogs/solutions/jp-ja/practice-cp4d-01 でご紹介しています。
本記事では、Data fabricの4つのチュートリアルのうち、“Multicloud data integration”について、日本語で手順をご紹介します。チュートリアルのリンクはこちらです(英語)。
本チュートリアルのイメージ動画はこちらです。
(概要)https://video.ibm.com/recorded/131931996
(詳細)https://video.ibm.com/recorded/131932068
想定シナリオはData fabricの4つのチュートリアルで共通で、下記になります。
- Golden Bankは、新たに、低金利の住宅ローンの取り扱いを始めることでビジネスを拡大したいと考えています。マーケティング施策とAIを使い、銀行の顧客を拡大、また申し込み処理コストは削減したいと考えています。一方で不適格なローン申請者に融資できないという新しい規制を遵守する必要があり、その対応を実施しなければいけません。
“Multicloud data integration”では、ローン関連の複数のデータソースから必要なデータを抽出してCSVファイルに統合し、分析ユーザーに公開するところまでを実施します。
このチュートリアルはIBM Cloud上のIBM Cloud Pak for Data as a Serviceのライトプランでお試しいただくことができます。ライトプランは、使用時間(CUH)の制限や、作成、登録できるアセットの数や機能に制限があるのでご注意ください。もし既に、ライトプランで別のサービスを試されている場合は、上位プランへの変更や、新規アカウントの新しい環境でお試しいただくこともご検討ください。
IBM Cloud Pak for Data as a Serviceの登録手順については、下記の記事をご参照ください。https://qiita.com/Asuka_Saito/items/df3467dc4c9919772c63
1.Multicloud data integrationチュートリアル概要
Multicloud data integration のチュートリアルでは、Golden Bankのデータエンジニアとして、住宅ローン申請の判断のために、下記の異なるデータソース上の4つのデータを統合し、統合したデータを公開する一連の流れを体験できます。
- ローン申請データ
- 申請者データ
- 申請者のクレジットスコア
- クレジットスコア別の適用金利
チュートリアルで行う操作は事前準備+10ステップで、Step1-8はデータの加工/統合のためのETLフローの編集、Step9-10はデータカタログへのデータ公開で構成されています。
- Step1-8:チュートリアルの実行環境を導入すると、元となる修正前のETLフローが保存されているので、修正前フローを編集して、必要なデータ加工処理などを追加し、新たなETLフローを開発します。
- Step9-10:ETLフローで出力されたデータをデータカタログに登録します。
以降で、事前準備からStep10までをご紹介します。
2.事前準備:プロジェクトのインポート
チュートリアルの実行領域となるプロジェクトをご自身のCloud Pak for Data as a Serviceの環境にインポートします。
- IBMIDを使用して、次の URL から、Cloud Pak for Data as a Service にログインします。
- IBM Cloud Pak as a Serviceの環境をプロビジョニングしていない場合は、こちらを参照して、IBM Cloud Pak for Data as a Serviceをプロビジョニングし、サービスカタログからDataStageを選択し、DataStageを追加サービスとしてプロビジョニングします。
- ログインできたら、左上の「例で学習」の下部分の「ガイド付きチュートリアルの実行」をクリックします。
- Gallery の画面が表示されます。検索ウィンドウに「Multicloud」を入力して検索します。結果として表示される「Multicloud Data Integration」をクリックします。
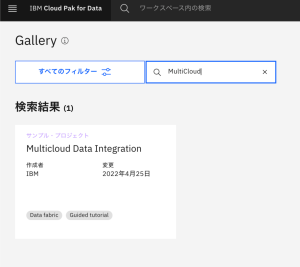
- 「プロジェクトの作成」をクリックします。インポート作業が始まります。
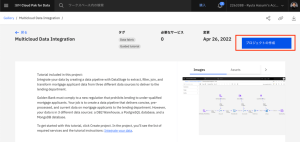
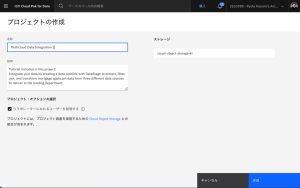
- プロジェクトの作成画面が表示されます。名前に適切なプロジェクト名を入力します。(既に同じCloud Pak for Data環境上に存在するプロジェクト名を入力するとエラーとなるので、その場合は異なるプロジェクト名を入力してください。)「作成」をクリックします。
- プロジェクトが作成されます。「新規プロジェクトの表示」をクリックします。作成された Multicloud Data Integration プロジェクトが表示されます。
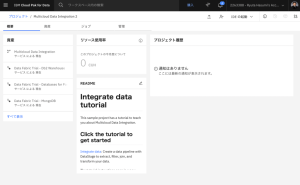
事前準備は以上です。
3-1. Step 1: Run an existing DataStage flow
DataStageフローを実行し、住宅ローン申込者と住宅ローン申請者のデータセットを結合するCSVファイルをプロジェクトに作成します。
- Multicloud Data Integration プロジェクトから、「資産」タブをクリックして、プロジェクト内のすべての資産を確認します。
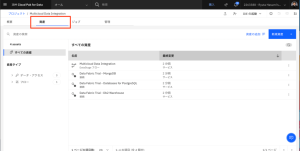
- [フロー] > [DataStage]フローをクリックします。DataStageフローが表示されない場合は、サービスインスタンスの表示に戻り、DataStageインスタンスが正常にプロビジョニングされたことを確認します。
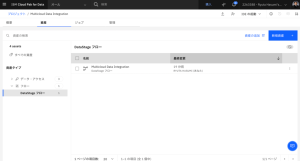
- Multicloud Data Integrationフローを開きます。このフローでは、Db2 Warehouseに格納されているMortgage ApplicantsテーブルとMortgage Applicationsテーブルを結合し、カリフォルニア州のレコードにフィルタリングし、出力としてCSV形式の逐次ファイルを作成します。
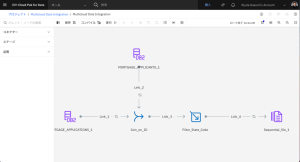
- MORTGAGE_APPLICATIONS_1ノードをダブルクリックして、設定を表示します。[プロパティ] セクションを展開します。下にスクロールし、[データのプレビュー] をクリックします。このデータセットには、住宅ローン申請に関する情報の取り込みが含まれています。[閉じる]をクリックします。
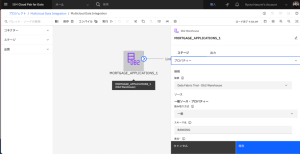
- MORTGAGE_APPLICANTS_1 ノードをダブルクリックして、設定を表示します。[プロパティ] セクションを展開します。下にスクロールし、[データのプレビュー] をクリックします。このデータセットには、ローンを申し込んだ住宅ローン申請者に関する情報が含まれています。[閉じる] をクリックします。
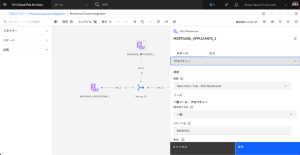
- [コンパイル]をクリックし、[実行]をクリックします。または、[実行]をクリックすると、DataStageフローがコンパイルされ、実行されます。
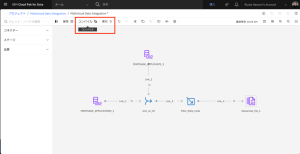
- ツールバーの[ログ]をクリックすると、フローの進行状況を見ることができます。実行には1分程度かかる場合があります。
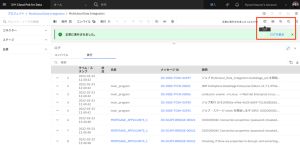
- 実行が正常に完了したら、トップメニューの階層からMulticloud Data Integrationをクリックしてプロジェクトに戻ります。[資産]タブで、[データ] > [データ資産]をクリックします。
- CSV ファイルを開きます。このファイルには、結合キーにIDを使用したmortgage applicantsとmortgage applicationsの両方のデータセットからのカラムが含まれていることがわかります。
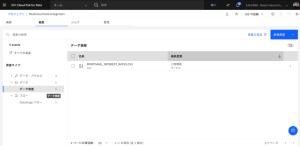
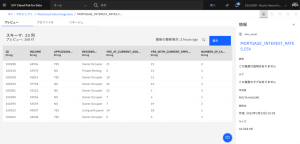
Step1は以上です。修正前のETLフローの確認ができました。
3-2. Step 2: Edit the DataStage flow
DataStageフローを編集し、Joinノードの設定を変更します。
- [フロー] > [DataStageフロー]をクリックします。
- [Multicloud Data Integration]フローを開きます。
- [ Join_on_ID] ノードをダブルクリックし、設定を編集します。
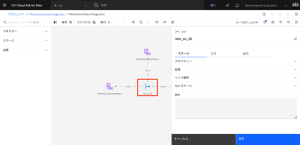
- [出力]タブをクリックし、[列]セクションを展開して、結合されたデータセットの列のリストを表示します。[編集]をクリックします。
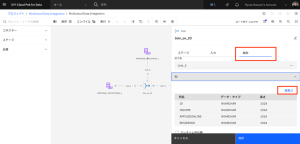
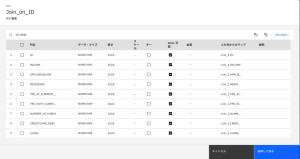
- EMAIL_ADDRESS 列名で、[キー]を選択します。
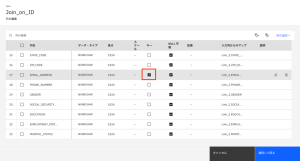
- [適用して戻る] をクリックして、Join_on_ID ノードの設定に戻ります。
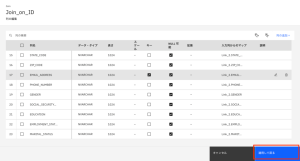
- [保存] をクリックして、Join_on_ID ノードの設定を保存します。
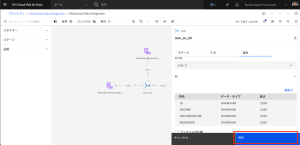
Step2は以上です。ETLフローのデータ統合の設定変更ができました。
3-3. Step 3: Add PostgreSQL data
PostgreSQLデータベースに保存されているクレジットスコアデータをDataStageのフローに追加します。
- ノードパレットで、「コネクター」セクションを展開します。
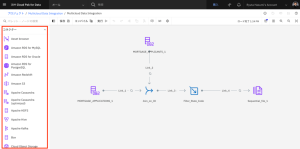
- MORTGAGE_APPLICANTS_1 ノードの横のキャンバスに Asset ブラウザ コネクタをドラッグします。
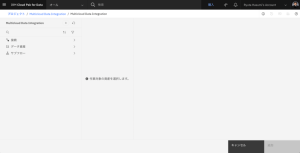
- アセットを見つけるには、[接続]>[Data Fabric Trial] – [Databases for PostgreSQL]>[BANKING]>[CREDIT_SCORE] を選択します。
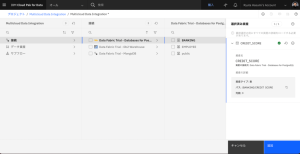
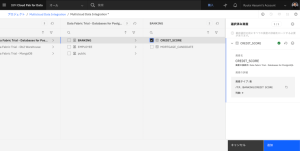
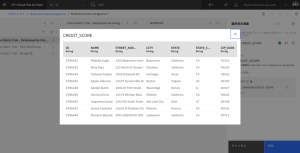
- 各申請者のクレジットスコアデータをプレビューするには、目のマークのアイコンをクリックします。
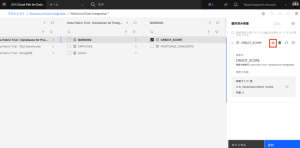
- [追加]をクリックします。
Step3は以上です。データソース(PostgreSQL)との接続を追加できました。
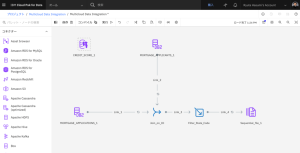
3-4. Step 4: Add another Join stage
別のJoinステージを追加して、フィルタリングされた住宅ローン申請/住宅ローン申請者のJoinデータとDataStageフロー内のクレジットスコアデータを結合します。
- ノードパレットで、[ステージ]セクションを展開します。
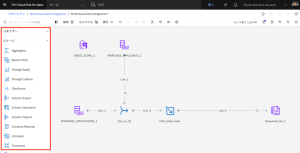
- Joinステージをキャンバスにドラッグし、Filter_State_CodeノードとSequential_file_1ノードの間のLink_4上にノードをドロップします。
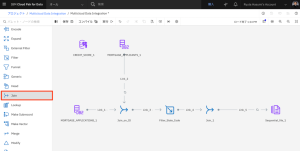
- CREDIT_SCORE_1コネクターにカーソルを合わせると、矢印が表示されます。矢印をJoinステージに接続します。
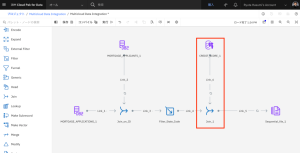
- CREDIT_SCORE_1 ノードをダブルクリックし、設定を編集します。
- [出力]タブをクリックし、[列]セクションを展開して、結合されたデータセットの列のリストを表示します。
- [編集]をクリックします。
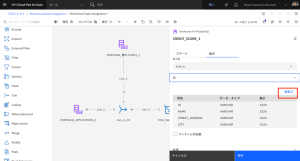
- [EMAIL_ADDRESS] と [CREDIT_SCORE] の列名で、Key を選択します。
- [適用して戻る]をクリックして、[CREDIT_SCORE_1]ノードの設定に戻ります。
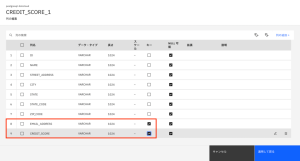
- [保存]をクリックして、[CREDIT_SCORE_1]ノードの設定を保存します。
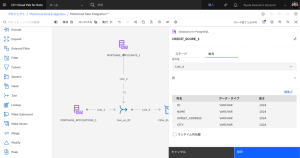
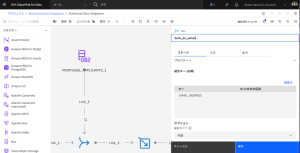
- [Join_1] ノードをダブルクリックして、設定を編集します。
- [プロパティー] セクションを展開します。
- [キーを追加] をクリックします。
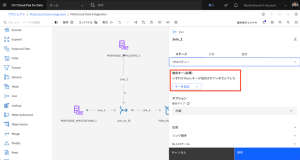
- [キーの追加] を再度クリックします。
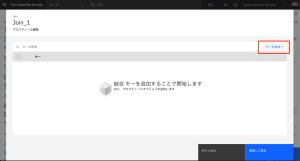
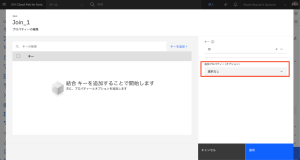
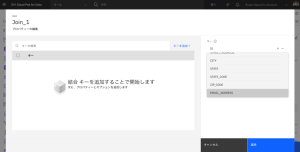
- ドロップダウン・リストから「EMAIL_ADDRESS」を選択します。
- [適用] をクリックします。
- [適用して戻る] をクリックし、 Join_1 ノードの設定に戻ります。
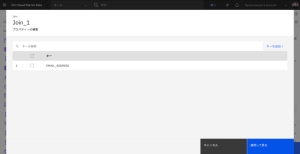
- Join_1ノード名をJoin_on_emailに変更します。
- Save をクリックして、Join_1 ノード設定を保存します。
Step4は以上です。新しいデータソースの結合処理の定義ができました。
後編に続く
後編はこちら→ https://www.ibm.com/blogs/solutions/jp-ja/practice-cp4d-05/

蓮見 竜太
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

岡崎 史博
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

セキュリティー・ロードマップ
IBM Cloud Blog
統合脅威管理、耐量子暗号化、半導体イノベーションにより、分散されているマルチクラウド環境が保護されます。 2023 安全な基盤モデルを活用した統合脅威管理により、価値の高い資産を保護 2023年には、統合された脅威管理と ...続きを読む

量子ロードマップ
IBM Cloud Blog
コンピューティングの未来はクォンタム・セントリックです。 2023 量子コンピューティングの並列化を導入 2023年は、Qiskit Runtimeに並列化を導入し、量子ワークフローの速度が向上する年になります。 お客様 ...続きを読む

ハイブリッドクラウド・ロードマップ
IBM Cloud Blog
コンポーザブルなアプリケーション、サービス、インフラストラクチャーにより、企業は複数のクラウドにまたがるダイナミックで信頼性の高い仮想コンピューティング環境の作成が可能になり、開発と運用をシンプルに行えるようになります。 ...続きを読む