IBM Data and AI
実践!IBM Cloud Pak for Dataチュートリアル (MLOps and trustworthy AI前編)
2022年07月22日
カテゴリー Data Science and AI | DataOps | IBM Cloud Blog | IBM Data and AI | IBM Watson Blog
記事をシェアする:
はじめに
「IBM Cloud Pak for Dataを手軽に試してみたい」という要望にお応えして、クラウド環境で手軽にお試しいただけるチュートリアルが完成しました。チュートリアル全般については
こちらの記事 →https://www.ibm.com/blogs/solutions/jp-ja/practice-cp4d-01 でご紹介しています。
本記事では、Data fabricのチュートリアルの中の「MLOps and trustworthy AI」をご紹介します。チュートリアルのリンクはこちらです(英語)。
- Build and deploy a model:https://dataplatform.cloud.ibm.com/docs/content/wsj/getting-started/df_AI_create_model.html?adoper=178484_1_PB1
- Test and validate the model: https://dataplatform.cloud.ibm.com/docs/content/wsj/getting-started/df_AI_monitor_model.html?adoper=178484_1_PB1
本記事では、日本語でStep by Stepで手順を紹介します。
チュートリアルでは、主に細かな設定作業が中心であるため、初めに、MLOps and trustworthy AIについて想定シナリオ及びおおまかな流れについてご説明いたします。本記事では、以下の流れでご説明いたします。
- MLOps and trustworthy AI チュートリアル概要(前編)
- チュートリアル1:モデルのビルドとデプロイ(前編)
- チュートリアル2:モデルのテストと検証(後編)
- 終わりに(後編)
このチュートリアルはIBM Cloud上のIBM Cloud Pak for Data as a Serviceのライトプランでお試しいただくことができます。ライトプランは、使用時間(CUH)の制限や、作成、登録できるアセットの数や機能に制限があるのでご注意ください。もし既に、ライトプランで別のサービスを試されている場合は、上位プランへの変更等もご検討ください。
チュートリアルを始めるにあたり、アカウントの登録等でご説明が必要な場合は、以下をご参考ください。
IBM Cloud Pak for Data as a Serviceを始めてみる(1.プロビジョニング編): https://qiita.com/Asuka_Saito/items/df3467dc4c9919772c63
また「新規アカウント登録時にクレジット・カード情報の入力が必須になりました」もご参照ください。https://www.ibm.com/blogs/solutions/jp-ja/account-update/
1.MLOps and trustworthy AI チュートリアル概要
MLOps and Trustworthy AIのチュートリアルは2部で構成されています。「Build and deploy a model」と「Test and validate the model」です。
これらのチュートリアルを始める前に、想定シナリオとおおまかな流れをご説明いたします。
想定シナリオ:
Golden Bankは、新たに、低金利の住宅ローンの取り扱いを始めることでビジネスを拡大したいと考えています。マーケティング施策とAIを使い、銀行の顧客を拡大し、一方で申し込み処理のコストは削減したいと考えています。また不適格なローン申請者に融資できないという新しい規制を遵守する必要があり、その対応を実施しなければいけません。
このチュートリアルは、AIのアプリケーションの裏側にある、AIのモデル作成や運用、監視を体感できるものとなっています。
チュートリアルのおおまかな流れ:
「Build and deploy a model」では、Cloud Pak for Data as a Serviceでどのようにモデルを
開発して登録、運用していくのか、一連の流れを体験できます。
①モデルの作成
②モデルのトラッキングの設定
③モデルのデプロイ
特に、②のモデルのトラッキングの設定では、Cloud Pak for Data as a Serviceのカタログを拡張した機能でMLOpsを体験いただくことができます。MLOpsとは、機械学習やAIアプリケーション構築と品質向上に有効なアプローチで、これによりAIモデルの適切な監視、検証、運用を備えた継続的なモデルの更新のリリースが可能となります。モデルは作ってリリースしてしまえばそれで終わりというわけではなく、継続的に、モデルの判定結果と世の中の動向(データ)にずれが生じていないか、品質は保たれているか監視して、品質が下がれば、最新のデータで学習し直すなど、常に監視と運用が必要となるものです。
「Test and validate the model」では、Cloud Pak for Data as a ServiceのWatson Open Scale というサービスを使用して住宅ローンの申請者全てを公平に扱っているか監視し、AIの判定結果を申請者に説明できる仕組みがあることを確認します。AIの品質、公平性、説明性を確認する以下の一連の流れを体験できます。
- Notebook実行によるOpenScaleのセットアップ
- モデルの品質、公平性、説明性の確認
- モデルの承認(MLOpsライフサイクルの確認)
では、早速チュートリアルを始めてみましょう。
2.チュートリアル1:モデルのビルドとデプロイ
概要:
このチュートリアルでは、Data fabric trial のMLOpsとTrustworthy AIのユースケースを使用してモデルを構築、デプロイ、トラッキングします。目標は、どの申請者が住宅ローンの資格があるかを予測するためのモデルをトレーニングし、評価のためにモデルをデプロイすることです。 また、モデルの判定結果の履歴を文書化し、説明を生成するために、モデルのトラッキングを設定する必要があります。チュートリアルのストーリーは、Golden Bankが、オンラインアプリケーションに低金利の住宅ローンの新しいサービスを提供することでビジネスを拡大したいと考えていることです。オンラインアプリケーションは、銀行の顧客範囲を拡大し、銀行の申し込み処理コストを削減します。Golden Bankのデータサイエンティストとして、予期しないリスクを回避し、すべての申請者を公平に扱う住宅ローン承認モデルを作成する必要があります。Jupyter Notebookを実行してモデルを構築し、AIファクトシートにモデルをトラッキングするメタデータを自動的に取り込みます。
このチュートリアルでは、これらのタスクを実施します。
2-1. はじめに:サンプルプロジェクトのインポート
2-2. モデルのトラッキングを設定
2-3. APIキーを生成
2-4. モデルインベントリにモデルエントリを作成
2-5. Notebookを実行し、モデルを作成
2-6. モデルのファクトシートを表示し、モデルエントリに関連付け
2-7. モデルをデプロイ
2-1. はじめに:サンプルプロジェクトのインポート
サンプルプロジェクトをCloud Pak for Data as a Serviceの環境にインポートします。
1.IBMIDを使用して、IBM Cloud Pak for Data as a Serviceにログインします。まだ、環境をプロビジョニングしていない場合は、こちらを参照して、IBM Cloud Pak for Data as a Serviceのプロビジョニングを実施します。(注意:OpenScaleは2022年6月現在、ダラスとフランクフルトのデータセンターでのみ提供しています。データセンターをまたがった利用も可能ですが、メニューの表示が一部制限されるなどがありますので、OpenScaleと同じデータセンターでWatson Studio、Watson Machine Learning、Watson Knowledge Catalogもプロビジョニングすることをお勧めします。)
2.IBM Cloud Pak for Data as a Serviceのプロビジョニングが正常に終了すると、Watson Studio、Watson Machine Learning、Watson Knowledge Catalogの3サービスが追加されます。トップページには、各種サービスや機能の新着情報がタイル型に並べられています。その中にGalleryというサンプル集のページへの入り口があるので、Galleryの「探索」をクリックし、「MLOps and Trustworthy AI」のサンプルプロジェクトを検索します。
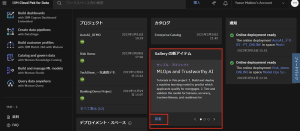
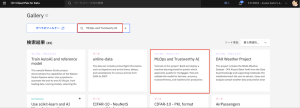
3.「MLOps and Trustworthy AI」が見つかったらクリックします。サンプル・プロジェクトの説明画面に切り替わりますので、「プロジェクトの作成」をクリックします。
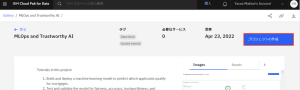
4.「プロジェクトの作成」の画面に切り替わりますので、プロジェクトの名前やストレージの設定などを確認後、「作成」をクリックします。
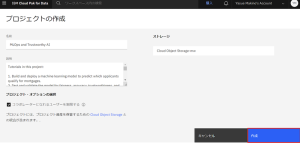
5.このチュートリアルでは、手軽に、MLOps and Trustworthy AIを体験いただけるように、事前にモデル作成のためのNotebookやトレーニングデータがサンプルとして利用できるようになっています。「作成」をクリックするとそれらのコンテンツを取り込み始めます。
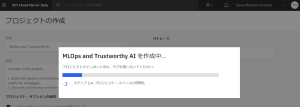
6.正常に取り込みされると、以下の画面が表示されます。「新規プロジェクトの表示」をクリックして中身を見てみましょう。
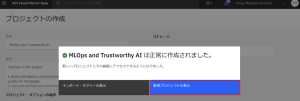
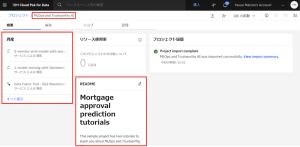
7.「MLOps and Trustworthy AI」プロジェクトに移動すると「資産」や「README」が追加されていることが確認できます。
2-2. モデルのトラッキングを設定
モデルをトラッキングするには、エントリモデルをカタログに追加します。Watson Knowledge Catalog のライトプランでは、カタログは 1つだけ作成できます。ここでは、エントリモデルを格納するためのカタログを作成します。
1.IBM Cloud Pak for Dataのナビゲーションメニューから、[カタログ] > [すべてのカタログを表示]を選択します。
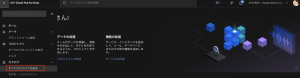
2.以下のページが表示されますので、[カタログの作成] をクリックします。
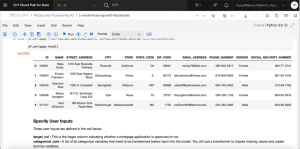
3.名前に「Mortgage Approval Catalog」と入力します(名前の先頭や末尾にスペースを入れないようご注意ください)。カタログをクラウドのオブジェクト・ストレージ ・インスタンスに関連付けるよう指示されたら、オブジェクト・ストレージ・インスタンスから「Cloud Object Storage」を選択します。他はすべてデフォルトにし、「作成」をクリックします。
4.カタログが作成されてもまだ資産がありませんので、以下のような表示になっていればOKです。
2-3. APIキーを生成
このチュートリアルで使用するNotebookには、Watson Machine Learning APIにアクセスするためのコードが含まれています。API キーを使用して、API に認証情報を渡す必要があります。まだAPI キーを作成していない場合は、以下の手順に従って API キーを作成してください。
1.IBM Cloud Pak for Dataのナビゲーションメニューから、[管理] > [アクセス(IAM)] を選択します。
2.[API キー] ページをクリックします。
3.[IBM Cloud API キーの作成] をクリックします。
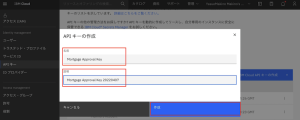
4.名前と説明を入力し「作成」をクリックします。(このチュートリアルの後半「Test and validate the model」でも使用するので、API キーをダウンロードしておきます。)
2-4. モデルインベントリにモデルエントリを作成
このようなプロジェクトでは、プロジェクト開始時にモデルエントリーを作成するのがベストです。モデルエントリーは、ビジネス上の問題を解決するために使用できる複数の機械学習モデルを参照することができます。そして、データエンジニアとモデル評価者は、モデルエントリーにモデルを追加し、モデルのライフサイクルの進捗をトラッキングすることができます。
1.モデルエントリーを作成します。ナビゲーションメニューから、[カタログ]> [モデル・インベントリー] を選択します。

2.モデルインベントリーに初めてアクセスする場合、モデルガバナンスを設定するかどうかを確認するガイドツアーが表示されます。[後でやる]をクリックします。
3.[新規モデル・エントリー]をクリックします。
4.モデル・エントリー名 に、「Mortgage Approval Model Entry」と入力します。モデル・エントリ名には、先頭または末尾にスペースを入れずに、表示されているとおりの名前を入力します。説明には、「このモデル・エントリーは、Golden Bankの住宅ローン承認ユースケース用です。」と入力し、保存します。(*複数のカタログがある場合、「カタログ」フィールドが表示されます。「Mortgage Approval Catalog」または別の既存のカタログを選択します。)
5.先ほど作成したモデルインベントリーが保存され、以下の画面が表示されます。
2-5.Notebookを実行し、モデルを作成
サンプルプロジェクトに含まれるNotebookを実行します。このチュートリアルは、モデルの作成方法を体験するものではなく、モデルの管理運用、公平性、説明性などを確認するのが目的のため、インポートしたNotebookを実行すると、自動的にモデルが作成されるようになっています。
1.IBM Cloud Pak for Dataのナビゲーションメニューから、[プロジェクト] > [すべてのプロジェクトの表示]を選択します。
2.[MLOps and Trustworthy AI]プロジェクトを開きます。
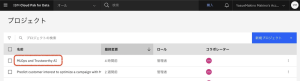
3.[資産]タブで、[ソース・コード] > [Notebook]をクリックします。[1-model-training-with-factsheets] Notebookをクリックして開きます。このNotebookでは、Mortgage Approval Prediction Model をトレーニングし、WML を使用してモデルをデプロイします。
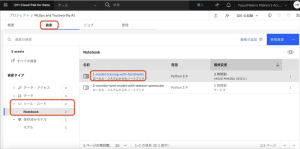
4.Notebookが読み取り専用モードになっているので、鉛筆アイコンをクリックしてNotebookを編集モードにします。※タイトルの前にあるセルは削除します。
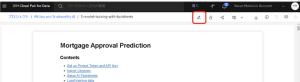
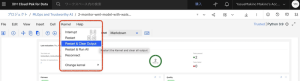
5.Notebookの上部にある指示に従って、プロジェクト・トークンをインポートします。[その他]メニューから、[プロジェクト・トークンの挿入]を選択します。
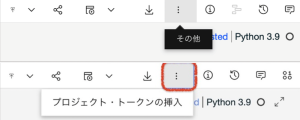
これにより、プロジェクト・トークンを含む新しいセルがNotebookの最上部に挿入されます。
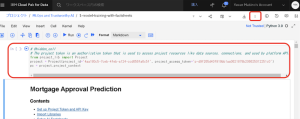
6.[Provide your IBM Cloud API key] セクションで、ibmcloud_api_key フィールドに API キーを貼り付けます。(ダウンロードしたファイルからコピー&ペースト)
7.Notebook内のすべてのセルを実行するには、[Cell] > [Run All] をクリックします。また、各セルとその出力を調べたい場合は、Notebookをセルごとに実行することもできます。(Notebookが完成するまでには、1〜3分かかります。アスタリスク「In [*]」が「In [1]」のように数字に変わることで、セルごとの進行状況を確認できます。)
8.Notebook実行中にエラーが発生した場合は、「Kernel」>「Restart & Clear Output」をクリックしてカーネルを再起動し、Notebookを再実行してください。
Training データ:80% /Testデータ:20%
手法:ランダムフォレスト
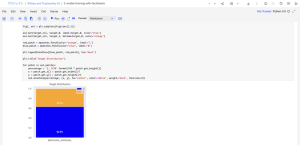
モデルの評価
ターゲットの分布
入力フィールドの相関行列

ROC曲線とAUC
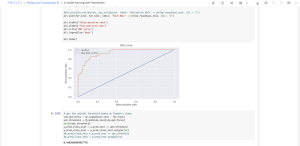
(※Youden indexとは、カットオフ値 : 最も予測能力・診断能力が低い独立変数のROC曲線、AUC = 0.500となる斜点線から最も離れたポイントをカットオフ値にする方法)
混同行列


2-6.モデルのファクトシートを表示し、モデルエントリに関連付け
Notebookのすべてのセルを実行した後、プロジェクトでモデルのファクトシートを表示し、そのモデルをモデル・インベントリーのモデル・エントリーに関連付けます。
1.[MLOps and Trustworthy AI]プロジェクトをクリックします
2.[資産]タブで[保存済みモデル] > [モデル]をクリックします。先ほど作成した[Mortgage Approval Prediction Model]をクリックして開きます。
Mortgage Approval Prediction Modelのページ
3.このページには、作成したモデルのファクトシートが表示されます。ページを下にスクロールして、Notebookの AI Factsheets python クライアントによって取得された [トレーニング・メトリック] 、および [トレーニング・タグ] の下にあるトレーニング メタデータを確認します。
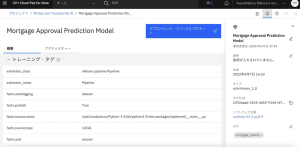
4.モデルページを上にスクロールし、[モデル・インベントリに追加]をクリックします。
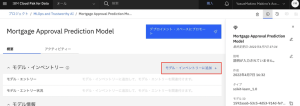
5.[既存のモデルエントリーに関連] を選択します。モデル・エントリーの一覧から、Mortgage Approval Model Entry を選択します。[追加]をクリックします。
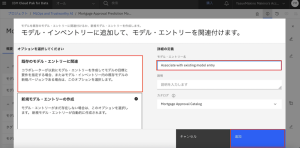
6.モデルページに戻り、[Mortgage Approval Model Entry]リンクをクリックします。
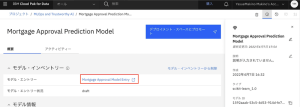
7.Mortgage Approval Model Entryページで、[資産]タブをクリックします。
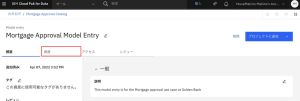
8.モデル・トラッキングの下に「AI Factsheets」がライフサイクルを通してモデルをトラッキングしていることが確認できます。このモデルは、まだデプロイされていないため、[開発]の段階です。
9.[Mortgage Approval Prediction Model]をクリックすると、AI ファクトシートが表示されます。
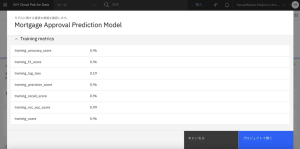
10.AI ファクトシートの確認が終わったら、一番下までスクロールし、[プロジェクトで開く]をクリックします。
11.「MLOps and Trustworthy AI」プロジェクトのページが開きます。
2-7.モデルをデプロイ
モデルを新しいデプロイメント・スペースにプロモートし、モデルをデプロイします。
1.モデル ページで、[デプロイメント・スペースにプロモート] をクリックします。
2.[ターゲット・スペース]で、[新しいデプロイメント・スペースの作成]を選択します。名前に「Golden Bank Preproduction Space」と入力します。先頭または末尾にスペースを入れないように注意します。ストレージ・ サービスの選択では、[Cloud Object Storage]が指定されます。機械学習サービスの選択ではWatson Machine Learningの機械学習サービスを選択します。(Cloud Pak for Data as a Service のプロビジョニング時に、Watson Machine Learningは自動で追加されます)。「作成」をクリックします。
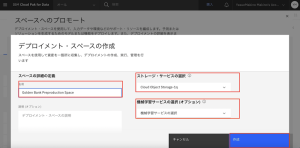
3.「スペースの準備が完了しました」と表示されますので、[閉じる]をクリックします。
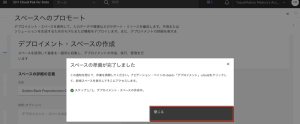
4.次に表示される画面の[ターゲット・スペース]に、[Golden Bank Preproduction Space]が選択されていることを確認します。[モデルをプロモートしてからスペース内のこの資産に移動してください。] オプションにチェックを入れます。[プロモート]をクリックします。
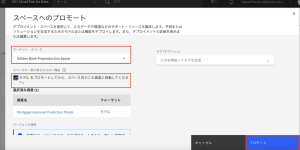
5.次に、モデルのデプロイを作成します。デプロイメントスペースのページが開いたら、[新しいデプロイメント]をクリックします。
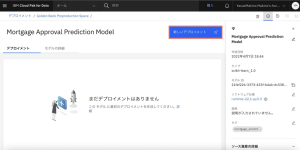
6.[デプロイメントの作成]で[オンライン]をクリックします。
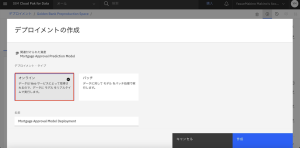
7.[名前]に「Mortgage Approval Model Deployment」と入力します。名前の先頭または末尾にスペースを入れないように注意します。[サービス名]に[デプロイ ID]の代わりとして 「mortgage_approval_service 」と入力します。この名前は、地域ごとに一意である必要があります(すでに利用されている名前は付けられないので日付や番号などで一意の名前をつけてください)。「作成」をクリックします。
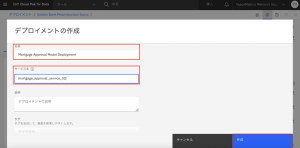
8.モデルが正常にデプロイされたら、「デプロイ済み」と表示されます。
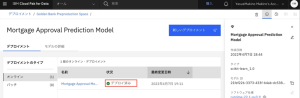
9.モデル・インベントリーのページに戻ります。[ナビゲーション・メニュー]から、[モデル・インベントリー]を選択します。
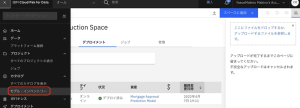
10.Mortgage Approval Model Entry の左下にある[詳細の表示] のリンクをクリックします。
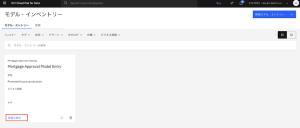
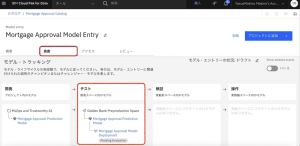
11.[資産]タブをクリックします。モデル・トラッキングの下で、モデルが現在デプロイ・ステージ(テスト)にあることが確認できます。以前は開発したのみでしたのでライフサイクルは「開発」でしたが、この度、テスト用のスペースにモデルをデプロイしてプロモートしたので、APIでの呼び出しができるようになり、ライフサイクルも「テスト」に変更されているのを確認します。
後編に続きます。
後編はこちら→ https://www.ibm.com/blogs/solutions/jp-ja/practice-cp4d-03/

牧野 泰江
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

斉藤 明日香
日本アイ・ビー・エム株式会社
テクノロジー事業本部 データ・AI・オートメーション事業部
Data & AI 第一テクニカルセールス

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

セキュリティー・ロードマップ
IBM Cloud Blog
統合脅威管理、耐量子暗号化、半導体イノベーションにより、分散されているマルチクラウド環境が保護されます。 2023 安全な基盤モデルを活用した統合脅威管理により、価値の高い資産を保護 2023年には、統合された脅威管理と ...続きを読む

量子ロードマップ
IBM Cloud Blog
コンピューティングの未来はクォンタム・セントリックです。 2023 量子コンピューティングの並列化を導入 2023年は、Qiskit Runtimeに並列化を導入し、量子ワークフローの速度が向上する年になります。 お客様 ...続きを読む