

























当サイトのクッキーについて IBM のWeb サイトは正常に機能するためにいくつかの Cookie を必要とします(必須)。 このほか、サイト使用状況の分析、ユーザー・エクスペリエンスの向上、広告宣伝のために、お客様の同意を得て、その他の Cookie を使用することがあります。 詳細については、オプションをご確認ください。 IBMのWebサイトにアクセスすることにより、IBMのプライバシー・ステートメントに記載されているように情報を処理することに同意するものとします。 円滑なナビゲーションのため、お客様の Cookie 設定は、 ここに記載されている IBM Web ドメイン間で共有されます。
IBM Watson Blog
NLP・NLU・NLG: 自然言語処理における 3 つの 概念の違い
2020年12月07日
カテゴリー IBM Cloud アップデート情報 | IBM Data and AI | IBM Watson Blog
記事をシェアする:
自然言語処理 (NLP)、自然言語理解 (NLU)、および自然言語生成 (NLG) は、すべて相互に関連するものの、別々の概念です。大まかに言えば、NLU と NLG は NLP の構成要素に過ぎません。しかし、これらの概念は相互に交差することからも、会話の中で混同されることがよくあります。この投稿では、それぞれの用語を個別に定義し、違いをまとめることによって、あいまいな部分を明確にしていきます。
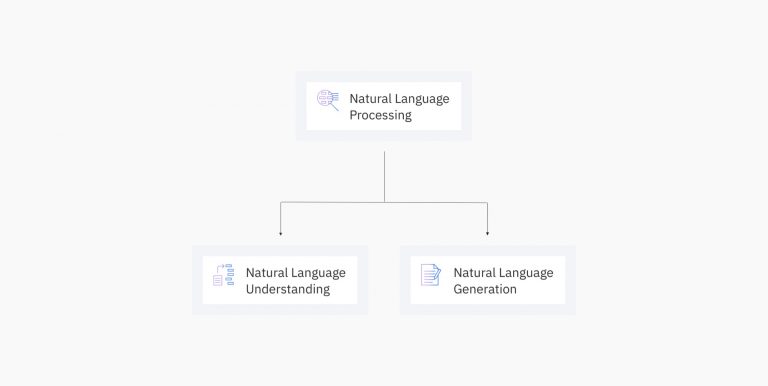
自然言語処理(NLP)とは
自然言語処理(NLP)(英語)は、計算言語学から進化したもので、コンピューター・サイエンス、人工知能 (AI)、言語学、およびデータ・サイエンスなど、さまざまな分野の方法論を駆使して、コンピューターが人間の話し言葉と書き言葉の両方を理解できるようにします。計算言語学は言語的な側面をより重視するのに対し、自然言語処理は、言語翻訳や質問への回答などといったタスクを完了するための機械学習とディープラーニングの手法の使用に重きを置きます。自然言語処理は、非構造化データを構造化データの形式に変換します。そのために、トークン化、ステミング、およびレンマタイゼーションなどの、語根形式を調べる手法を活用して、固有表現の識別 (「固有表現抽出」と呼ばれるプロセス) とワード・パターンの識別を行います。例えば、「called」という単語は接尾辞「-ed」が付いているため過去時制を表しますが、現在時制の動詞「calling」と同じ原形不定詞 (「call」) を持ちます。
NLP アルゴリズムは複数存在しますが、言語タスクの種類によって異なるアプローチが使用される傾向があります。例えば、隠れマルコフ連鎖は品詞のタグ付けに使用されることが多く、再帰型ニューラル・ネットワークは適切な文字シーケンスを生成するのに役立ちます。単純な言語モデル (LM) である N-gram は、文または句に確率を割り当てて、応答の正確性を予測します。これらの手法が連携して機能することで、チャットボットや Amazon の Alexa または Apple の Siri のような音声認識製品など、私たちの生活に広く浸透しているテクノロジーを支えています。しかし、NLP の応用範囲はこれらにとどまらず、教育や医療といった業界にもその影響を与えています。
自然言語理解(NLU)とは
自然言語理解(NLU)とは、自然言語処理の一分野であり、テキストや音声の構文・意味解析を使用して文の意味を判別します。構文とは、文の文法的構造を、意味とは、文が意図する意味を指します。NLU は、関連するオントロジーも構築します。オントロジーとは、語と句の間の関係を指定するデータ構造です。人間は会話の中で自然にこれを行いますが、機械がさまざまなテキストの意図する意味を理解するには、これらの分析を組み合わせて使用する必要があります。
また、人間は同音異義語や同音異綴語を区別することができますが、これは言語のニュアンスを理解する能力の表れです。例えば、以下の 2 つの例をみてみましょう。
IBM Watson Natural Language Understanding についての詳細
- Alice is swimming against the current. (アリスは流れに逆らって泳いでいます。)
- The current version of the report is in the folder. (レポートの最新版はフォルダーに入っています。)
1 つ目の文の「current」という単語は名詞です。その前にある動詞「swimming」が読者に追加のコンテキストを提供しているため、海の水の流れを指していると結論付けることができます。2 つ目の文でも「current」という単語を使用していますが、ここでは形容詞です。「current」が説明している名詞「version」が、レポートが複数回反復されていることを示しているため、ファイルの最新の状態を指していると判断できます。
これらのアプローチは、消費者態度を理解するために、データ・マイニングでも頻繁に利用されます。特に、評判分析を使用することで、企業は顧客のフィードバックをより密にモニターして、ソーシャル・メディア上の肯定的・否定的なコメントをクラスター化し、ネット・プロモーター・スコアを追跡できます。否定的な評価のコメントを調べることにより、企業は、自社の製品やサービスの中で、潜在的な問題がある部分を特定して対処することができます。
自然言語生成(NLG)とは
自然言語生成(NLG)もまた、自然言語処理(NLP)の一分野です。自然言語理解(NLU)はコンピューターの読解力に焦点を置く一方で、自然言語生成(NLG)はコンピューターが文章を生成できるようにします。NLG は、何らかのデータ入力に基づいて、人間の言語によるテキスト応答を生成するプロセスです。生成されたテキストは、音声合成サービスを通して音声の形式に変換することも可能です。
NLG には、入力された文書から、情報の整合性を保ちながら要約を生成する、テキストの要約機能も含まれます。抽出型要約は、「That’s Debatable」で使用されたキーポイント分析 (Key Point Analysis) (英語)にも活用されている、AI の革新的技術です。
もともと、NLG システムではテンプレートを使用してテキストを生成していました。NLG システムは、何らかのデータまたはクエリーを基に、言葉遊びゲームのように空白を埋めていっていました。しかし、時を経るにつれて、NLG システムは、隠れマルコフ連鎖、再帰型ニューラル・ネットワーク、およびトランスフォーマーの適用とともに進化し、リアルタイムの、より動的なテキスト生成が可能になりました。
NLU と同様に、NLG アプリケーションでも、形態学、語彙、構文、および意味に基づく言語ルールを考慮し、応答をどのように適切に表現できるかを決定する必要があります。この課題には 3 つのステージで取り組みます。
- Text planning: このステージでは、一般的なコンテンツが形成され、論理的に順序付けされます。
- Sentence planning: このステージでは、句読点やテキストの流れが考慮されます。コンテンツを段落や文に分解し、適切な場合には代名詞や接続詞を追加します。
- Realization: このステージでは、文法的な正確さを明らかにし、句読点や接続詞に関するルールが守られていることを確認します。例えば、「run」の過去時制は「runned」ではなく「ran」です。
NLP・NLU・NLG の違いのまとめ
- 自然言語処理 (NLP) は、非構造化言語データを構造化データ形式に変換して、機械が音声とテキストを理解し、コンテキストに応じた適切な応答を生成することを目的としています。NLP のサブトピックに、自然言語理解と自然言語生成が含まれています。
- 自然言語理解 (NLU) は、文法やコンテキストを通した機械の読解力に焦点を置き、機械が文の意図する意味を判別できるようにします。
- 自然言語生成 (NLG) は、機械による、所与のデータ・セットに基づいた、テキストの生成、または英語やその他の言語のテキストの生成に焦点を置いています。
データを AI に活用
自然言語処理(NLP)とその各分野には、今日の世界において、医療診断やオンライン・カスタマー・サービスなど、非常に多くの実用的な応用方法があります。
IBM の最新の NLP に関する研究 (英語)または Watson Natural Language Understanding などの IBM の製品オファリングをチェックしてみてください。テキスト分析サービスは、お客様のテキスト・データから、カテゴリー、コンセプト、エンティティー、キーワード、関係、評価、および構造に関する洞察を提供し、お客様がユーザーのニーズに迅速かつ効率的に応答できるよう支援します。データの分析とAI の大規模な活用を実現し、お客様のビジネスを軌道に乗せるお手伝いをします。
More IBM Watson Blog stories

敷居もコストも低い! ふくろう販売管理システムがBIダッシュボード機能搭載
IBM Data and AI, IBM Partner Ecosystem
目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

テクノロジーが向かう先とは〜中長期テクノロジー・ロードマップ
IBM Cloud Blog, IBM Data and AI
IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む

データ・ロードマップ
IBM Data and AI
生成AIによるビジネス革新は、オープンなデータストア、フォーマット、エンジン、製品指向のデータファブリック、データ消費を根本的に改善するためのあらゆるレベルでのAIの導入によって促進されます。 2023 オープン・フォー ...続きを読む