Hybrid Data Management
Netezza on Cloud Pak for Data System 統合データプラットフォームとしての新たな価値
2020年07月12日
カテゴリー Hybrid Data Management
記事をシェアする:
本記事は Brad Miller Practice Director, Information & Analytics Mainline 投稿のIBM Solution Blog翻訳記事となります。
本を手に取ると物語の結末が気になる人がいます。私もその中の一人です。場合によっては、最後の章を読んでから、最初に戻って本の残りを読むこともあります。では、もったいぶらずに本題に戻って、Netezza に何が起きたのかについてお答えしましょう。Netezza は今も多くの企業で活用され、進化を遂げています。そして、IBM は、次世代の Netezza 製品を IBM Cloud Pak for Data System に統合してリリースしました。
2 年程前にいくつかの決定が発表され、Netezza は IBM で消滅の一途を辿るのだと悲観していました。特に、ソリューションの熱狂的なユーザーがいる Netezza コミュニティーには衝撃が走りました。落胆していた Netezza ファンを一転して喜ばせたのは、IBM による Red Hat の買収後に発表された Netezza の次世代製品のニュースでした。
Netezza のさらなる進化
IBM Cloud Pak for Data を基盤とした Netezza Performance Server のプラットフォームは、柔軟性と堅牢性を大幅に改良しながら、これまでの Netezza の特長をそのまま継承しています。今回のリリースは、Netezza コア・ソフトウェアと IBM Cloud Pak for Data System に備えられた広範な分析とデータ処理の新機能が含められた、バンドル化されたソフトウェア・アーキテクチャーです。このソリューションには、Netezza 処理ノードを Cloud Pak for Data System ベースに追加するインフラストラクチャーも含まれています。Cloud Pak for Data System には、データの収集、仮想化、洗練化、ガバナンス、データウェアハウジング、および高度な分析プラットフォームが含まれています。Cloud Pak for Data は、Netezza の処理やパフォーマンスに影響しないように、またその逆に、Netezza が Cloud Pak for Data の処理やパフォーマンスに影響しないように設計されています。Cloud Pak for Data System は、コンテナ化されたハイブリッドクラウド・アーキテクチャーを使用するため、処理ニーズが拡大しても、別のオンプレミス・インフラストラクチャーまたはクラウドにある、ハイパーコンバージド・システムで対応できます。
すべての Cloud Pak for Data System のコンポーネントおよび Netezza のホストはコンテナ化され、Red Hat LINUX (RHEL) と OpenShift 上で稼働します。OpenShift は共通のオーケストレーション層を提供し、IBM はそれを基盤とすることで、管理、セキュリティー、およびロギングなどの共通機能を、より統一して構築できます。Netezza Performance Server は、旧世代の Netezza ソリューション (TwinFin、Striper、Mako など) の強みをすべて継承しながら、アプライアンスを購入しなければ拡張できないという最大の弱点をはじめとする、多くの弱みを解消しました。Cloud Pak for Data System ソフトウェアと Netezza Performance Server をバンドルすることで、旧世代の Netezza では実現できなかった多くのメリットを提供できるようになります。エンドツーエンドのデータ処理と AI (人工知能) の処理機能を、1 つのプラットフォームで使用できます。これだけ広範な機能を 1 つのソリューションにまとめることができる企業やプラットフォームは他にありません。
Netezza on Cloud Pak for Data System ハイパー・コンバージド・データシステム
IBM Cloud Pak for Data System と Netezza Performance Server は、どちらもモジュール式のソリューションです (IBM ではこれをハイパーコンバージドと呼びます)。つまり、同一のアーキテクチャー内 (多くの場合 同一のラック内) に、処理ノードを追加できるようになります。モジュール式のアーキテクチャーにより、組織のニーズに合わせてきめ細かにチューニングされたソリューションが構築できます。現時点 (2020 年 4 月) では、Netezza は、x86 ハードウェアで稼働するオンプレミス・アーキテクチャーで、Netezza の中心的な技術として、Field Programmable Gate Array (FPGA) コアが使用されていることに変わりありません。しかし、2020 年後半に、Netezza のクラウド対応版が発表されることへの期待は高まっています。
Netezza 100%互換、改良されたNetezza ハードウェア & ソフトウェア
Netezza Performance Server は、これまでの使い慣れた主な機能をすべて継承しています。例えば、NZ 関数、INZA 関数、地理空間データの処理、およびコアの Netezza Platform Software (NPS) を引き継いでいるため、非常に簡単に移行できます。Mainline のお客様の中には、nz_migrate などの共通ツールを使用して、2 時間足らずで新しい NPS システムに移行できた企業もあります。ユーザー定義関数 (UDF) を使用されているお客様であれば、再コンパイルの作業のみで、従来の 32 ビットの Netezza から 新しい 64 ビットの NPS に対応できるようになります。
Netezza ホストも進化し、コンテナ化されました。これにより、Netezza のコア機能とオンプレミスで実行されるコンポーネントとの、ハイブリッド構成を推進します。その他のワークロードはクラウドへシフトされるか、他のインフラストラクチャーにオフロードされます。回転式ディスクが SSD ドライブに置き換えられたことで、パフォーマンスも大幅に向上しています。TwinFin モデルでディスク障害を頻繁に経験されているお客様にとって、処理速度の向上はもちろんのこと、安定性の向上も喜ばしい進展です。
これまで、情報エコシステムにおける Netezza プラットフォームの役割は、専門的で活躍する場面が限られていたと言ってもよいでしょう。分析ワークロードのための高パフォーマンスなデータ・リポジトリー (または、データウェアハウス) として以外に使用されることはありませんでした。Cloud Pak for Data System に統合された Netezza は、使用できるフィーチャーを拡張できるため、組織にエンドツーエンドの情報と AI の価値をもたらすために必要な多くの機能に対応できます。また、ソリューションの洗練された設計により、組織はバリュー・プロポジションやイニシアチブに対応するために必要なソリューション・コンポーネントだけを使用することができます。組織のニーズの変化や対象顧客の拡大に伴うソリューションの拡張に応じて、後からでも追加機能をシームレスに開始することができます。
以下 2 つの図は、旧世代の Netezza の機能と比較して、Cloud Pak for Data System と統合したNetezza Performance Server の機能面での方向転換と追加ケイパビリティーを示しています。このような情報エコシステムの概念図は特に目新しくありません。左側のさまざまなデータ・ソースからデータ・フローが開始され、データ処理、リポジトリー (または仮想化)、そして最後にデータを使用するユーザーへ流れていきます。
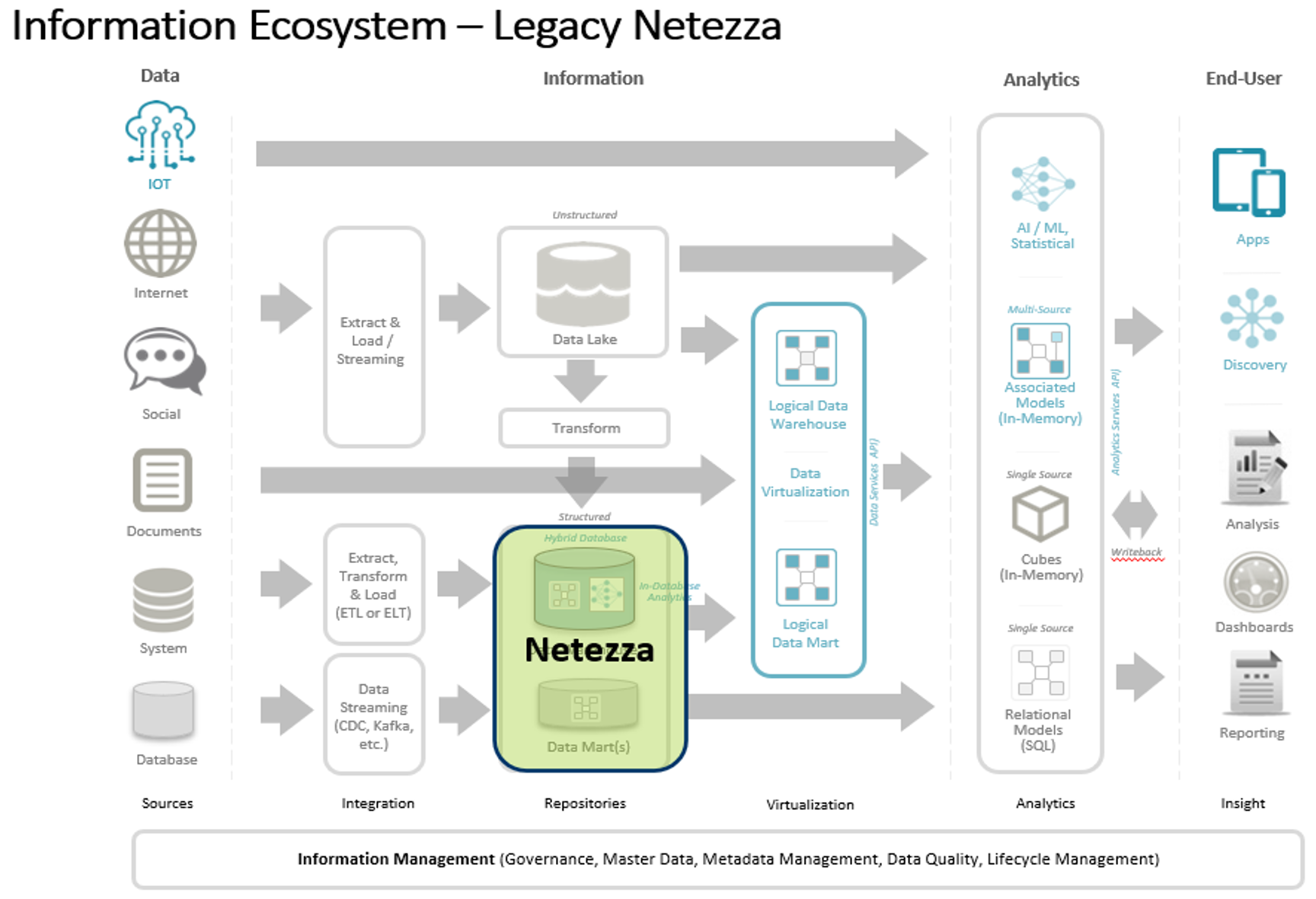
旧世代の Netezza は、構造化データに適した分析データベースでした。Netezza は、INZA エンジンを使用して、初期から AI 処理の一部をビジネス・ソリューションに適用していました。また、ESRI エンジンを使用して、初期から地理空間データの分析も行ったソリューションでもあります。Netezza を買収した IBM は、Fluid Query を使用したスクリプト・ベースの仮想化機能の追加、広範囲なデータ処理が可能な Hadoop の追加、非構造化データ処理の IBM Db2 Big SQL の追加など、さまざまな Netezza ソリューションの拡張を行ってきました。これら Netezza の主要機能だけとっても、従来型のデータウェアハウスやデータマートの構築、さらにはビッグデータのユースケースに適用を拡大する場合に、数多くの組織で大いにその価値を発揮しました。最終的に、Netezza ソリューションは、組織の情報エコシステムのデータ・リポジトリー層に密に結び付けられるようになりました。
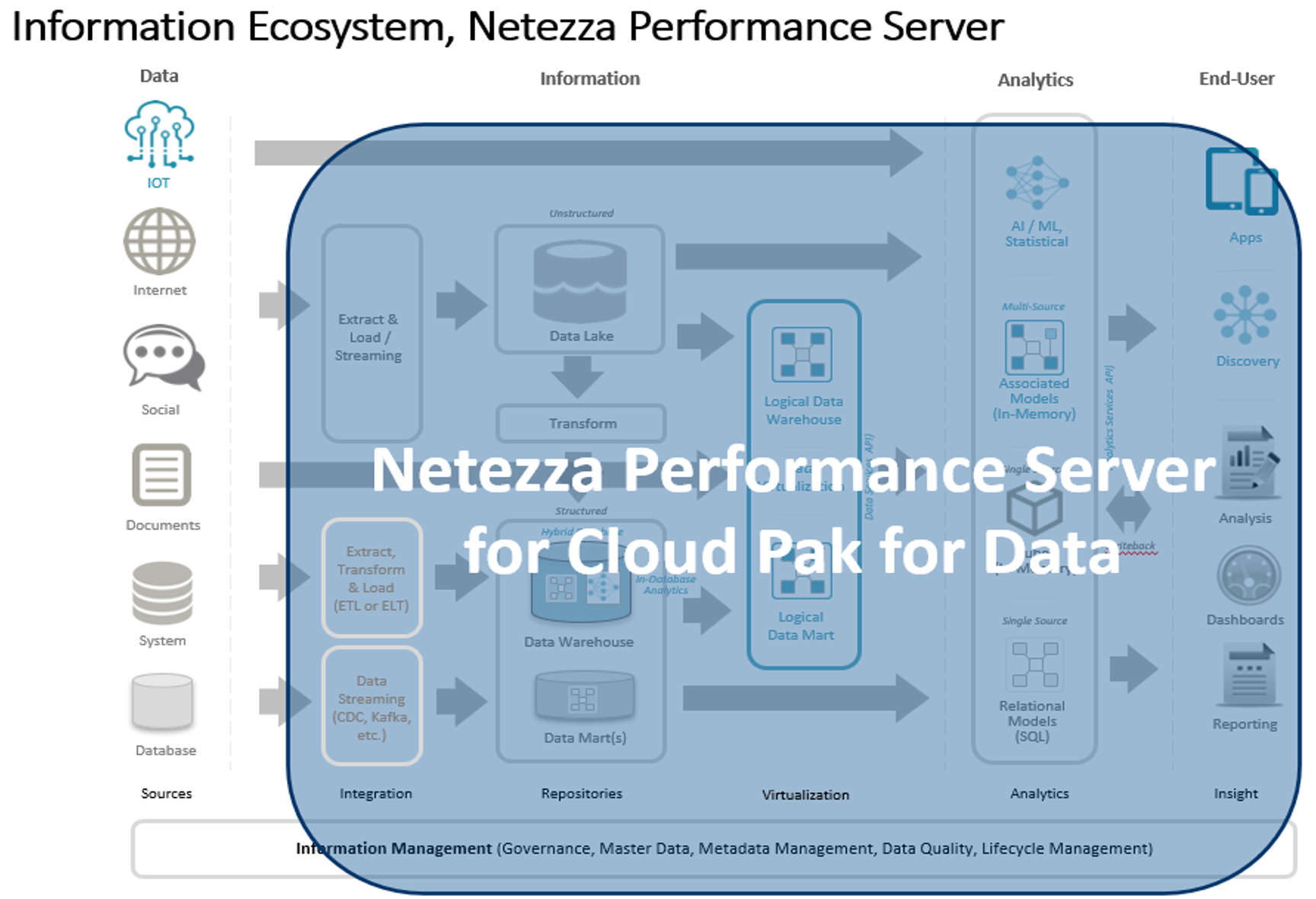
Cloud Pak for Data System に統合された Netezza Performance Server は、旧世代 Netezza の機能を継承しながら、Cloud Pak for Data の広範な機能を含めて拡張したため、組織はほとんどの情報と分析のユースケースに対応できるようになります。このことから、広範囲に及ぶさまざまなソースに存在する構造化データや非構造化データを仮想化するために、ユーザーは複雑なスクリプティングやサード・パーティーのツールに頼る必要がなくなりました。その結果、ビジネスに近い場所でデータを仮想化できるようになり、ソリューションのデプロイを迅速化し、変更に対応する IT 部門内での管理作業も削減しています。組織の多くは、ソリューションに組み込まれた AI 機能、Watson を活用して、AI のはしご (AI Ladder) の次のステップに進むのと同時に、データ・ガバナンスや規制準拠など、組織が直面する困難な課題やデータ管理の課題に対応できるようになります。AI は、Cloud Pak for Data System のコア・コンポーネントに組み込まれているため、ユーザーは、迅速にプロファイリング、分析、モデリング、新規ソースの取り込みを行い、これらを組織の既存の成果物に合わせて調整できます
お客様成功事例
IT 市場に新しい製品が発表されると、唱えられている価値は本当なのか、つまり、実際に機能するのか、お客様が知りたいと思われるのは当然です。Mainline は、以下のようなさまざまな業界にわたる多数のお客様をご支援しています。
- 小売業
- 銀行業
- 製造業
- 金融サービス業
- 医療
- 研究
- 高等教育
Netezza Performance Server と IBM Cloud Pak for Data System を統合することで、旧世代の Netezza よりも高度な機能を装備したソリューションを組織に提供できます。そこで、Mainline はお客様と協働し、このようなソリューションに対応する、専門性の高いユースケースと広範囲のユースケースを実装しています。
ユースケース 1: ある組織では、ステージング・エリアの大部分を NoSQL ソリューションにオフロードすることで、複雑な自然言語処理 (NLP) を前処理してから、Netezza のコア・リポジトリーに戻すことができるようになりました。
ユースケース 2: ある企業では、AI のはしごのステップに沿って取り組みを進めるために、Watson Studio のコンポーネントを活用することに注力しました。これには、製造ラインへのさらなる洞察の提供、および複数の加工処理を経てからでないとわからない無駄の軽減を図る目的もありました。
初期の取り組みの成功を受け、組織はより複雑な高いビジネス価値の分野にも乗り出しています。Netezza Performance Server と Cloud Pak for Data System がなければ、組織の既存データとシステムに対処することはできなかったでしょう。Mainline はお客様と協働して、成功を導き出し、高い費用対効果を得られるよう取り組んでいます。

「みんなみんなみんな、咲け」ローランズ代表 福寿満希さん 講演&トークセッション(前編)[PwDA+クロス11]
IBM Partner Ecosystem
日本IBMは、毎年12月初旬の障害者基本法による障害者週間に重ねて、「PwDA+ウィーク」を開催しています(「PwDA+」は「People with Diverse Abilities Plus Ally(多様な能力を持 ...続きを読む

企業の垣根を越えて:生成AI活用アイデアソンをトヨタファイナンス様とIBMが共同開催
Client Engineering
トヨタファイナンス株式会社IT本部イノベーション開発部部長の松原様の呼びかけにより4社のITベンダーが参加した生成AIアイデアソンが10月7日に開催し、成功裏に幕を閉じました。 ~トヨタファイ ...続きを読む

ServiceNow x IBM、テクノロジーの融合で地域の特色を活かしたDXを推進
IBM Consulting, デジタル変革(DX), 業務プロセスの変革...
ServiceNowと日本IBMグループでは、両社のテクノロジーを融合させ新たな価値を提供することで、日本の地域社会をより豊かにする取り組みを戦略的に進めています。 2024年12月からは「IBM地域ServiceNow ...続きを読む