Db2
元技術理事に伺う Db2の軌跡と舞台裏
2023年08月31日
カテゴリー Db2 | IBM Data and AI | アナリティクス | オートメーション
記事をシェアする:
今年、IBM MQとDb2は30周年。WAS(WebSphere Application Server)は25周年を迎えます。アニバーサリー・イヤーとして3製品に関わりのある方々へのインタビューを1年を通じて定期的に行っています。今回は、IBM技術理事(DE:Distinguished Engineer)のご経歴がある大沼啓希氏にインタビューを行いました。Db2の思い出や今後の期待などを伺いました。

大沼啓希(写真右)
日本アイ・ビー・エムに入社後、メインフレームのOSであるMVSのエンジニアとしてお客様の技術支援を担当。1983年、MVS用リレーショナルデータベース「DB2」の発表以来、データベースを中心とする技術支援やシステム構築支援を担当。著書は「DB2入門」等。2000年にDEになり、ソフトウェア事業部に移籍し、DB2 UDBの販促、技術支援を担当。
岡口純子(写真左)
日本アイ・ビー・エムに入社後、流通・サービス業界のお客様担当SE。
インフラチーム、アーキテクトとしてSIプロジェクトにてデリバリー実施。2000年からDBのテクニカルセールスとして様々な業種のお客様に対して数々の提案、ベンチマークを実施。ボランティアのDB勉強会ClubDb2を初期メンバーとして立上げ、主催。現在はData and AI領域でのテクニカルセールス、アーキテクトとして提案活動、販促、技術支援を担当。
1.IBMでのご経歴について改めて教えていただけますでしょうか?
大沼氏)
IBMに1973年に入って最初の10年くらいはずっとメインフレームのOSを担当して、当時はSystem/370-158と-168(メインフレームの機種名)が発表出荷された時でした。更にVirtual Storageが使えるようになった時でした。お客様からジョブを貸していただいて、それでベンチマークの仕事をしていました。当時のOSはMVS(Multiple Virtual Storage)であり、Virtual Storageをたくさん使って入出力に大量のI/Oバッファを使う事が出来ました。バッファを大きく取れることはDB2も一緒ですけれども、先読みによって処理がすごく速くなります。大量にデータを先読みしてVirtual Storageにデータを入れることによって、普通ディスクI/Oで待ちが発生し、遅くなるところを全部メモリーで処理することが出来ます。だから1983年にDB2が出てきた時に、これはすごいと思いました。MVSのDB2はメモリーを沢山使って先読みがすごく速かったですね。
とはいえ、素人が書いたSQLというのはインデックスを使わないことが多くて処理は遅かったですね。もっと悪いことにインデックスを使わないアクセスをするとCPUを大量に消費してしまう。当時は1SQLのパスレングスが 100万インストラクション以上とか言われていて、更にDynamic SQLにするともっと上積みされる。そしてアクセスパスが状況によって変化するので、これをチューニングするのが大変でしたね。
DB2のお客様支援としてESP(Early Support Program:早期サポート・プログラム)を含め5~6年担当しました。このまま続けても、なかなか現場の実際のお客様の環境を経験するのが難しいかなと思い、1987~1992年迄大阪の松下グループ担当営業部に転勤してここでCICS―DB2システム(CICSはトランザクションシステム)の構築を支援しました。
その後東京に戻ってきて、主にDB2アプリケーション構築支援で、メインは某保険会社様のCICS-DB2 V4による大規模共用DBシステム開発などを担当しました。

(インタビュー中の大沼氏)
岡口氏)
Sysplexの最初のシステムということですよね。今オープン系のDB2だとpureScaleのベースになったアーキテクチャがメインフレームのSysplex。その最初のお客様ですね。
大沼氏)
2000年にDEになってソフトウェア事業部に移って、DB2UDB(DB2 Universal Data Base :V5の頃の名称)の販促、技術支援を担当しましたが、これも大変でした。それまではお客様と一緒にシステム構築等をしてきましたので、お客様の環境はほぼ理解して支援してきました。ソフトウェア事業部に移ったら、急にあそこがトラブルだから入ってこいと言われるわけです。面白かったですけど、私を含めてみんな若かったですからね。細かい作業や資料作成、トラブル解決して動かすまで頑張っていました。
岡口氏)
臨機応変に対応されていたということですね。DB2のオープン系ではなくて、MVSで最初にリリースされた頃から触られていて、初めてのSysplexでの構築とかもされているということですね。2000年とかですとDB2 V7なので、私もちょうどソフトウェア事業部に来た頃で、大体それぐらいの頃から大沼さんと渋谷や五反田に行ってご一緒していましたね。
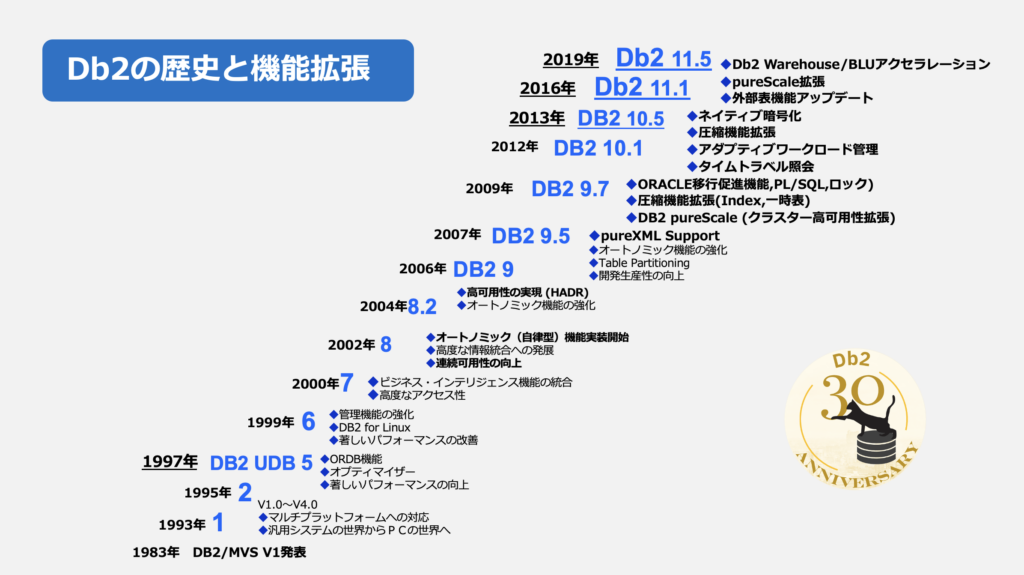
(* IBMデータマネジメント製品群はDB2からDb2にリブランディングしました。更にレイクハウスソリューションとの統合など進めてきました。)
2.DB2にいつ頃から関わりを持たれましたか?当時のロールや製品との関わり、その時の印象などをお聞かせください。
大沼氏)
1983年にDB2 V1が発表されましたが、それまでのRelational DBの製品であるSQL/DSとは大きく異なっていました。ディスクへのアクセスにはアクセスメソッドというのを使います。そのアクセスメソッドという汎用のプログラムを使ってユーザーアプリケーションがレコードのやりとりをしますけども、そのアクセスメソッド(VSAM)のパスレングスが長すぎるので、それを短くするファストパスがインプリされました。本当にディスクI/Oの根本部分だけをやるようになりました。それと全く同じ考え方をDB2に持ってきて、VSAMの定義部分だけ使って中身は全部アプリでアクセスとするという方法をDB2が採用しました。これが画期的でI/Oアクセス部分がものすごく速くなりました。
この様な画期的な仕組みを備えたDB2ですが、1980年当時「MVS版のリレーショナルデータベースが開発され、そのコードネームがイーグル」というのが知られてしまい、それがなかなか発表されないので、当時は「イーグルは飛ばない」と新聞に書かれてしまいました。
岡口氏)
新聞に書かれちゃう時代なんですね。

(インタビュー中の岡口氏と大沼氏)
大沼氏)
当時ESPのお客様の導入支援をする為に、私はサンタテレサに行ってテストをしていたことがあります。障害が発生してPTF(Program Temporary Fix:ソフトウェアの不具合を修正するプログラム)を適用したのにしばらくすると同じトラブルを見つけてしまいました。トラブルを発見する度にメモリーダンプを全部紙にプリントしてました。するとすごい量になって、そのダンプした紙をカートで開発チームに持って行ってました。ラボのテスト担当者にトラブルのシステムのメモリーダンプを渡した時に、何故同じトラブルを何度も起こすのかと質問したら、バグとダンプの紙はリサイクルするんだよと言われたことをよく覚えています。
岡口氏)
ちょっとバグはリサイクルして欲しくないですね(笑)
大沼氏)
イーグルは飛ばないとか、言われている時がとても苦しい時期で、開発部門がそのDB2を作る時にトラブルを事前に予測して、こういうトラブルがこういうところで起こったらこうするんだっていうPDPSI(Problem Determination Problem Source Identification)を全部作って全てコンポーネント化していました。コンポーネントやモジュールがエラーを出すと、頭2桁アルファベット、その後ろに4桁の数字のCQ0101とかのコードが割り振られて、それを見るとピンポイントにどこの部署が開発したかが分かるようになっていました。サンタテレサはサンフランシスコからフリーウェイの101を使って行きます。偶然かどうか分かりませんが、中々治らないトラブルのエラーコードが”C9-0101“だったのが印象的だったのを覚えています。
岡口氏)
想定外のエラーなんですかね。でも、エラーメッセージだけでどのモジュールが出しているエラーかが分かるというのは問題判別上、すごく便利ですよね。
3.これまで様々なご経験をされている中で、DB2関連のプロジェクトで特に印象に残っているエピソードがあればお聞かせください。
大沼氏)
DBの用語で”ロック”というものがありますが、一般的に”ロック”すると言ったら金庫のロック、部屋のロックですよね。鍵をかけて中に人を入れない、あるいは自分が入っていて、外から人を入れないためですよね。そうではないロックって考えられますか?
自分が攻撃されない、あるいは誰かに取られてはいけないからそのために自分でがっちり保護する、これが一般的に考えるロックで、これを悲観的ロック(pessimistic lock)と呼びます。一方で、楽観的ロック(optimistic lock)というのは、もしそこに物があったとして、これが取られたり、あるいは変更されたりするのは全然問題なくて変更されたこと、取られたことが分かればいい、後は自分で何とかするという考えです。
ロックの処理が多いとそのパスレングスが多いだけでなく待ち時間も多くなります。(つまり、CPUと応答時間が多くなります) だからDB2 UDBもそうですけど、レコードロックは実装されていますがあまり使われません。レコードロックをするとレコードの数だけロックを取らないといけないから、ロックの量が膨大になってしまうわけです。
悲観的ロックではロックが解除されるまで待たされますが、楽観的ロックでは基本的にコミット時にまとめて行われる更新処理迄ロックは取らないので、ロック待ちは最小限に抑えられます。これによって平行トランザクション処理のスループットが大幅に向上して、ロングトランザクションの設計が楽になります。更に、工夫すればオンラインとバッチを並行処理する事も出来るようになります。
岡口氏)
ロック待ちしなくなるとパフォーマンスと同時並行性が上がるんですよね。

(インタビュー中の大沼氏)
大沼氏)
一番問題なのはバッチとオンラインです。バッチを夜に回して、バッチが終わらないとオンラインを始めない理由は簡単なことでロック競合を起こすからです。バッチが動いている間オンラインは止まってしまうから、仕方なくオンラインを止めてからバッチを動かして、バッチが終わってからオンラインを始める必要があります。
当時、某保険会社様ではまだマシンが速くない時にマシンを沢山並べて、トランザクションデータを一斉に更新しようとしていたので、ロック競合を抑制する必要がありました。
オンライン処理には営業スタッフが顧客の契約情報などを参照する他に、新契約のシミュレーション処理がありました。今の契約を置き換えるにはどうしたらいいか、全く別の契約にしたらどうなるか、オプションを付けたらどうなるのか、などのシミュレーションを普通のオンラインのプログラムでやってしまうとレコードを更新してしまいます。実際にどうしていたかというと途中まで処理した後、全部ロールバックする処理をしていました。実際の契約よりもシミュレーション処理の方が多いので、これは楽観的ロックにすごく合います。更新されてもロールバックされれば元に戻るからです。ロックを取る必要もなくなります。
岡口氏)
なるほど、日中のオンライン処理の殆どが更新されないという前提なんですね。実際の契約処理よりシミュレーションの回数の方が圧倒的に多そうですからね。
大沼氏)
夜間バッチは処理レコード数が膨大です。夜間バッチは締切になって振り込みがあるとその振り込み処理と消し込み処理を金融機関ごとにやりますから、膨大な件数のレコードを処理するのですが、オンライン・バッチ共用の処理ウィンドウを作れば、その間、並行して運用出来ます。
岡口氏)
今でこそNoSQLとか、楽観的ロックが標準的になっていますし、DB2は昔から悲観的ロックだったと思いますけど、もしかして大沼さんが辞められる頃くらいでしょうか。DB2のロックが遂に変わりましたよね。必ずロック待ちしていたのがコミット済みの直前のデータを返すに変わりましたよね。直前のデータだから誰かが更新しているかもしれないけど、それはまだコミットしてない更新が終わっていないから、もしかしたら元に戻るかもしれない。もうその人の処理は勝手に処理させておいて、今コミット済みのデータを返す。それによって同時並行性を高めるように10数年前に変わって、あの時は結構衝撃的でした。頑なにロックを取っていたDB2がロック待ちさせずに返すように変更するなんて、やっぱり時代の流れで変わったのかなって思いました。
大沼氏)
楽観的ロックの処理をアプリで実装することは大変なことで、この保険会社様のシステムの殆どのDB2のSQL部分を自分のサブルーチンの中でやっています。データを読み込んだら、自分のバッファに全部溜め込んで、自分の中からSQLが出たら、そのSQLと結果の比較をバッファの中でやります。更新があると、そのバッファの中を更新して、それ毎にコピーを作ります。疑似的なロールバックの処理の為にコピーを作るのです。
岡口氏)
ロジックをプログラムでやっていたから、システム側がやってくれたらすごく楽だったということですよね。今の時代は製品側が用意してくれるけど、当時お客様のプログラムはそれをやるために大変なプログラムを用意する必要があったということですね。
大沼氏)
それがあったら万々歳で、このようなことやる必要はありませんでした。このシステムが十年以上先行していたわけですよね。でも、アプリで作ると問題もあって、メンテナンスが難しくなります。当時そういう製品化のための色々なリクエストを我々からもしていました。米国のブランドマネージャーにリクエストを持っていった時に、日本の中の状況だけしか知らないとどうしても説得できませんでした。結果的に自分達でやってしまう。これからはこの部分を期待としてもっと今の皆さん方がやらないといけないと思いますね。
岡口氏)
今も頑張って製品の改善要望は色々とリクエストしていますが、今は投票システムがあって、それぞれの改善要望に対して社内外の人達が投票できるようになっていて、開発側がその数を見てくれて、投票が多いとそれだけのニーズがあるんだなっていうことで優先順位が上がるような仕組みも最近使われています。
大沼氏)
それはいいね。私らの時は次のリリースのFunction Specを読んだ時、暫くするとなくなってしまうこともありましたからね。
岡口氏)
その優先順位決めているのもお客様ニーズなので一度通っても安心していられないんですよね。その改善リストに出た後も、ちゃんと日本のお客様もその機能が欲しいっていうのを伝え続けていく必要がありますね。
4.これからもDb2やIBM製品がお客様に選ばれ続けるために必要なこと、IBMへの期待をお聞かせください。
大沼氏)
やはりユーザーニーズにどれくらい寄り添っていけるかがキーになると思います。
製品ありきで機能がたくさんあるから、そのための技術支援をやるだけでは厳しいと思います。私はXMLDBが出た時にこれはすごいと思って、非構造化データをやるにはXMLが一番だろうと思って勉強して本まで出したけど中々広がりませんでした。
岡口氏)
結局、XMLが難しくて、その後JSONの方に開発者が流れていきましたからね。
大沼氏)
その間をつなぐ何かが必要だと思います。ChatGPTの例もあるけども、簡単なインターフェースみたいな起爆剤があるだけで、大きな違いができると思います。
Db2は、XMLDBもそうだけど、機能としてほとんど網羅している素晴らしいソフトウェアだと私は思っています。
専門家がいなくてもなんとかシステム構築ができるイメージだったと思っていましたが、段々高可用性やXMLDB等の難しいDB構築には、技術支援が必須だと思います。この部分をパートナーを含めた技術支援でIBMが広範囲に請け負っていくことができたらもっともっと面白いDb2の使い方をアピールできるのではと思っています。
岡口氏)
そうですね、やっぱりそこはパートナー様とか、DBは何を選ぶかはSIer様が決めたりもしますし、特にDBはお客様から見ると、完全にバックエンドで見えない製品なので、アプリの中にどんどん組み込まれていく分には、どんどん使っていただきたいと思うので、それもパートナー様ですよね。パートナー様との協業はこれからも一層力を入れていく必要がありますね。
本日は本当に長いお時間いただきありがとうございました。

(記念写真:左より 岡口氏、大沼氏)
インタビュー・執筆:アニバーサリー広報チーム(Data, AI and Automation 事業部)
撮影:鈴木智也(Data, AI and Automation 事業部)

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む

敷居もコストも低い! ふくろう販売管理システムがBIダッシュボード機能搭載
IBM Data and AI, IBM Partner Ecosystem
目次 販売管理システムを知名度で選んではいないか? 電子取引データの保存完全義務化の本当の意味 ふくろう販売管理システムは「JIIMA認証」取得済み AIによる売上予測機能にも選択肢を 「眠っているデータの活用」が企業の ...続きを読む

テクノロジーが向かう先とは〜中長期テクノロジー・ロードマップ
IBM Cloud Blog, IBM Data and AI
IBM テクノロジー・ビジョン・ロードマップ – IBM テクノロジー・アトラスを戦略的・技術的な予測にご活用いただけます – IBM テクノロジー・アトラスとは? IBM テクノロジー・アトラス ...続きを読む