SPSS Modeler ヒモトク
Modelerデータ加工Tips#21-併買パターン上位5種類の組み合わせを抽出する
2021年10月28日
カテゴリー Data Science and AI | SPSS Modeler ヒモトク | アナリティクス | データサイエンス
記事をシェアする:
皆さま、こんにちは。アクセンチュアの赤石です。アクセンチュアには2021年3月に入社したばかりで、現在はビジネス コンサルティング本部AIグループという組織でAI系人材育成を主な仕事として活動しています。
アクセンチュアは、世界200拠点以上に62万人を超える専門家を有し、経営戦略立案、テクノロジー活用、オペレーション支援、また近年ではエクスペリエンス領域での設計から実施まで、一気通貫に幅広く手掛ける総合コンサルティング会社です。アクセンチュアでは「Digital is Everywhere(デジタルはもはや当たり前)」という考えのもと、こうした様々なサービスの根幹にデジタルの力を据えており、中でも近年AIを活用して、より高度で効率的なサービスを実現することに尽力しています。実際にはJAL様のAI POWERED コンシェルジュ事例や、オーシャン・ネットワーク・エクスプレス様のコンテナ在庫管理最適化など日本国内でも数多くのAI・データサイエンス事例を実現しています。
私はアクセンチュア入社前は、IBMに在職していたのですが、直近の5年位はワトソン事業部やData&AI事業部で、Watson APIやWatson Studioというクラウド上のAI開発環境の技術営業をしていました。仕事の一環で、社会人向け大学院である、金沢工業大学虎ノ門大学院で、Pythonを使ったAI開発の授業の講師も担当しました。その時の経験を生かしてAI関係の書籍を共著を含めて5冊執筆しています。中でも日経BPから出版した3冊( 「ディープラーニングの数学」「Pythonで儲かるAIをつくる」「PyTorch &深層学習プログラミング」)は、幸いにして大変好評をいただいていて、いずれの書籍もAmazonジャンル別で1位になったことがあります。
なぜ、こんな自慢話を始めたかというと、半分は単に自分の本の宣伝をしたいからですが、残りの半分はちゃんとした理由があります。これからご紹介する記事の内容と密接な関係があるのです。
Watson事業部がData&AI事業部の一部になり、SPSS技術営業のメンバーと合流した時が私とSPSSとの関係の始まりです。その後、同じ部になった旧SPSS技術営業メンバーと会話する中で、どうもSPSSの使い手であるメンバーと、私のようなPython使いでは、SPSSの個々の機能の見え方・捉え方が違うのではないかと思い始めたのです。それが何かを端的に申し上げると、私のようなPython使いの目でみると「このSPSSの機能、凄い!」と思えるものが、「普通にできますよね」という感じで、スルーされてしまうのです(苦笑)。どうも当人たちはその機能の凄さを理解できていないようなのです。
私がこの記事を書いた一番の目的は、この「Python使いから見たSPSSの凄さをSPSS使いの人たちに理解してもらいたい」ということになります。当記事を読んで、私のこの「思い」の一端でもご理解いただけると大変ありがたいです。
前置きが長くなってしまい、申し訳ありません。それではいよいよ本題に入ります。今回は PythonとSPSS実装を比較するため、最初に 例題の2つのテーマを先に提示する形にします。
例題
前回の出題は次の通りでした。
例題データ
利用するデータはこちらです。
https://raw.githubusercontent.com/yoichiro0903n/blue/main/sampledatacross2.csv
(リンクを右クリックして「リンク先を保存」またはブラウザで開いてからページを保存します)
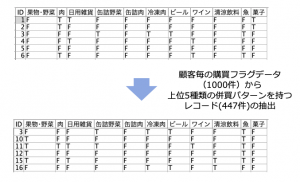
例題1:「併買パターンを集計する」
すでに顧客毎にカテゴリ購買有無を示すテーブルができている前提で、カテゴリの併買を集計してください。

例題2:「併買パターン上位5つのどれかに該当したレコードを抽出する」
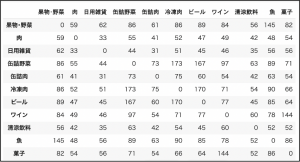
例題1の結果、冷凍肉と缶詰野菜を併買するパターンが最多で、173件でした(例題1の表を参照)。同じように同時に購入されるパターン上位5位を見つけ、そのどれかに該当するレコードを抽出しなさい。
Python実装
それでは、早速上の2つのテーマをPython で実装してみます。なお、以下に示すコードはGitHub 、解説はQiita記事にアップしてありますので、あわせてそちらもご参照下さい。
データ読み込みと前処理
まずは、変数df に分析対象のCSVファイルを読み込みます。Python的には’T’, ‘F’のラベル値はブーリアン値 True / Falseの方がその後の処理がしやすいので、その置換をかけた結果をdf2という別変数に保存します。
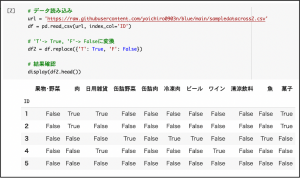
今回のCSVデータでは、ID列がキー項目の意味を持ち、この項目だけ他の項目と性質が異なります。こういう場合、 CSV ファイルを読み込む段階で index_col パラメータでID列をインデックス指定すると後の処理が楽になる点が、Python的にはちょっとした小技になります。
これでデータの準備は整ったので、2つの例題について考えていきましょう。
例題1
Python使いにとっていきなり難しいテーマです。Python でデータ処理をする場合はPandas を使います。 Pandasの関数で、この類の集計をするものとしては、crosstab関数とpivot関数があります。両者の最新の APIリファレンスをざっと見たところ、今回の要件を満たす機能はなさそうでした。(いや、そんなことはないという方がいらっしゃったら、是非やりかたを教えていただきたいです。)もし、この判断が正しいなら、ベタにループを回して、該当ペアの要素をひたすらカウントアップするしかないです。以下で示すのはその方針に基づいた実装となります。
まず、処理で必要な変数I(項目リスト)、N(項目数)、S(結果表)の初期設定をします。実装コードは以下のとおりです。

次のコードが実際の集計処理です。

Pythonならではの特徴を活用して極力シンプルなコードにしたのですが、数え上げのために3重ループが必要な点は本質的にどうしようもなく、その結果、こんなおおげさになってしまいました。このPythonの現実から出発すると、後ほど見るSPSSのシンプルな実装に驚くことになります。
最後のdisplay関数の出力結果が下の図になります。テーマに含まれている結果と同じ数値なので正しい解答になっていることがわかります。
例題2
この例題は2段階の処理が必要です。第1ステップは、例題1の結果を元に、トップ5の項目ペアを抽出すること、第2ステップは抽出した項目ペアのリストを元に、分析元データのレコードを絞り込むことです。後ほど示す SPSSの実装でもこの大きな流れに違いはありません。問題は、それぞれのステップをいかに簡単に実装できるかという点になります。このことを頭においた上で、以下の Python実装を見ていきましょう。
第1ステップをPython で実装する上で中心的なアイデアは、2次元の集計表をいったん1次元にするというものです。1次元の数値リストであれば、NumPyのargsort 関数を使って、ソート後のindexを得ることができます。あとは、ここで得られた1次元化されたインデックスを2次元に戻し、最後に対応する項目名と紐付ければいいことになります。次の関数は、今説明した最後の処理を定型化したものです。

この関数を準備しておけば、上で説明した第1ステップの結果は、以下のコードで取得可能です。

このコードのポイントは「w2 = np.argsort(-w1)[:10:2]」という行で、この実装により、上位5個の1次元化されたindex が取得できます。 print関数の結果は以下のとおりで、正しく上位5個の項目名ペアが得られています。

次は第2ステップの実装です。いろいろ考えてはみましたが、今回もPythonや Pandasの機能を使って画期的に簡単に実装できる方法はなく、ベタに元データに対して1行ずつループをまわし、上で抽出した項目ペアのどれかを含むかチェックをかけるしかないという結論になりました。そのための実装が下記になります。
この実装では集合演算の利用など一部高度なテクニックも使っていますが、この記事はPython講座ではないので詳細説明は省略します。実装方法が気になる方は、冒頭でも紹介したQiita記事を参照するようにして下さい。

この処理の結果得られたtarget_dfの中身の一部と件数を確認してみましょう。コードと結果は以下になります。

例題2のテーマ説明のところに記載されている結果と比較して、先頭6行のID の値と、結果件数が一致しているので、正しい計算ができていることがわかります。しかし、相当複雑な実装コードになってしまったこともご理解いただけたと思います。
SPSS実装
かなり長い解説になってしまいましたが、今回の2つの例題をPython で解くことがいかに大変なのか、雰囲気はわかっていただけたと思います。では、いよいよ本題の、同じ例題に対する SPSS実装を見ていくことにしましょう。すると、今まで当たり前に使っていたSPSSのノード達がいかに凄いものであるか、わかってくるのではないかと思います。
例題1
IBMのSPSS技術メンバー曰く、 SPSS的にはこの例題は「サービス問題」なのだそうです。解答ストリームは次の通りです。
データを読み込む際に注意が必要です。可変長ファイルノードでデータの入力パスを指定した後、データ型タブで「値の読み込み」ボタンを押して下さい。すると尺度と値が以下のように設定されます。この操作をしないと次のクロス集計でエラーになり慌てることになります。
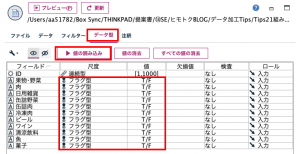
続いてクロス集計ノードの設定です。クロス集計は行(表側)と列(表頭)を指定して集計するのが一般的ですが、複数のフラグ変数を持つデータを一度に集計できるようになっています。フィールドを「すべてのフラグ(真の値)」を選択して実行すると、真=Tだけを対象にしてフラグ変数間の組み合わせ該当数を求めます。
出題と同じクロス集計表になりましたでしょうか?
SPSS使いには当たり前のことなのかもしれませんが、面倒なPython実装を自分で経験した人間にとっては、びっくりするほど簡単な手順でした。
例題2
Python実装のところでご説明したとおり、この例題は「Top5の抽出」・「抽出結果に基づく元データの絞り込み」の2段階の処理が必要です。この点はSPSS であっても違いはありません。違いは、その実装手順の簡単さです。その点をこれから具体的に見ていきましょう。
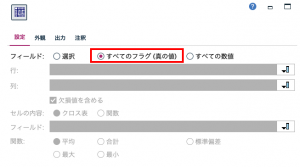
「Top5の抽出」の結果は、例題1で用いた同じクロス集計ノードに対して「外観タブ」を設定するだけで得られます。カテゴリの上位5つの併買パターンを知るには以下のように外観タブで「上位を強調表示」にチェックを入れて、「10」とセットして実行してみてください。

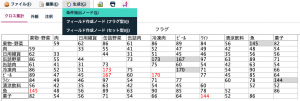
下記の図のように10個のセルが赤文字になりました(そのうちの半分は青枠で囲んだセル)。これが、第1ステップである「Top5の抽出」の結果になります。
この表は赤い線の対角に同じ組み合わせがペアで表示(例えば「ビール」と「ワイン」、「ワイン」と「ビール」など)されますので、強調表示の数を5ではなく倍の10としました。解釈するときは線の上下どちらかだけに着目すればOKです。

ここから先が第2ステップである「抽出結果に基づく元データの絞り込み」の実装手順です。上で得られた赤文字セルのうち、青枠のものをすべて選択して、メニューから条件抽出ノードを自動生成します。
この操作で「条件抽出ノード」が作られます。この「条件抽出ノード」こそが SPSSで条件抽出をやりやすくしている肝のノードなのです。Pythonの場合は、集計計算をすると集計結果の値のみがわかって、途中の計算過程は一切残りません。これに対して、SPSS では計算過程はノードにより表現されています。この性質を利用することで、「この結果を得るためには、元のデータに対してどういう計算・絞り込み条件を使えばいいか」を自動的に集約したノードが、「条件抽出ノード」の意味するところだったのです。SPSSではこの機能を活用することで、簡単な操作で複雑な条件抽出が可能になります。手前味噌な発想で恐縮ですが、計算結果だけでなく計算の過程を内部的に保持してそれを別の目的に活用している点が、私の最新著作である「PyTorch &深層学習プログラミング」で説明しているPyTorchの特徴的な機能「Define by Run」に似たところがあるなと思いました。
本題に戻りましょう。条件抽出ノードさえ作ってしまえば、後の手順は簡単です。元データのノードと条件抽出ノードを接続し、更に出力確認用のテーブルノードをつなぎます。テーブルノードを実行することで、下図のように例題2の解答が得られました。
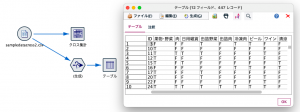
Python版では、元データから条件を満たすコードを絞り込む実装が相当ややこしかった(結構頭を使いました)のですが、SPSS では同じ絞り込み条件を作る処理が、マウスをポチポチクリックするだけでできてしまったことになります。改めて「SPSS恐るべし」というのがPython使いの率直な感想でした。
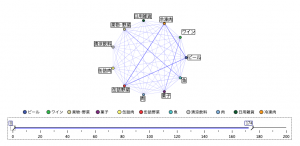
例題2にはまったく別の解もあります。生成ノードをWebグラフから作る方法です。

Webグラフの表示設定は下図の赤枠で囲んだアイコンをクリックし、すべての項目を選択して下さい。また、画面下部の「真のフラグだけを表示」のチェックボックスにチェックをつけて実行します。
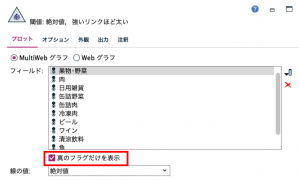
すると、蜘蛛の巣に見えることでその名がついた関係図Webグラフが表示されます。
次に左のスライダを100あたりにあげていただくと、少ない組み合わせが非表示になり、上位5つの組み合わせが表示されます。表示メニューからインタラクティブグラフにチェックを入れると赤丸の「魔法の杖」ボタンが表示されますので、それをオン。図のようにグラフをフリーハンドで囲うと、組み合わせのラインが赤く反転されます。
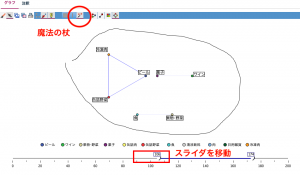
その状態で生成メニューから「条件抽出ノード(OR)」を選択します。
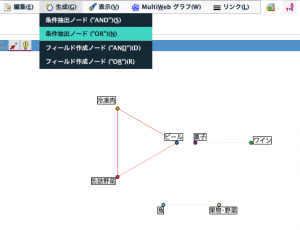
先のクロス集計同様、Webグラフからも自動で条件抽出ノードが生成されますので元データから接続、更にテーブルノードにつないで実行すれば完了です。ここから先のやり方はまったく同じなので詳細手順は省略します。
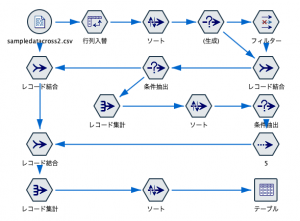
今回はModelerの表やグラフの便利な機能を使って抽出しましたが、それに頼らず地道にノードを繋ぐ方法ももちろんあります。ただし、結構なノード数になってしまうはずですので紹介した方法がいかにラクかお分かりいただけると思います。
以下のようにノードを繋げて抽出する方法もQiita記事でご紹介しておきますので参考にしてください。
新しいデータに当てはめて自動化する場合には、マウスでグラフや表からアクションできないので、こういった方法が採用されるはずです。
まとめ
同じ例題のPython vs. SPSSの実装比較、いかがだったでしょうか?Python実装と比較することで、いかにSPSSがスグレモノであるかその一端をご理解いただけたかと思います。
そもそも、なんでこんな違いがあるのか、考察を加えてみます。今回の例題は、「例題1」「例題2前半(トップ5の抽出)」「例題2後半(該当元レコード抽出)」の3つの要素に分解できます。
このうち、「例題1」「例題2前半」に関しては、こういう機能がツールにあるかどうかという問題です。現時点でSPSSにはその機能があり、 Python/Pandas にはその機能がないという点が、手順の複雑さの違いに現れたということになります。
SPSS はクレメンタインの時から合算すると20年以上の歴史を持つ分析ツールです。想像ですが、SPSS ではユーザーから今回のような分析をしたいという要望が数多くあり、それに応じて実装されたのではないでしょうか?それに比べてPython/Pandas は歴史が浅いため、このような機能の差につながったのではないかと考えられます。
「例題2後半」に関しては、より本質的な問題があります。SPSS版の解で示した機能は可視化された分析結果が操作の起点です。なので、そもそもPython/Pandasのようなコマンドベースのツールでは実装は不可能で、同等機能を作りたい場合分析ツールの枠組みそのものから見直す必要があります。
一方でこの例題のように、「分析結果からその元データを抽出し元データを確認することでより深掘りした分析を加える」アプローチは、データ分析の世界でとても重要です。筆者は、IBM時代Watson Explorerというテキスト分析ツールを扱ったことがあり、他社のテキスト分析ツールを比較した際の、Watson Explorerの最大の特徴がこの点にあったので、この機能の重要性をよく理解しているつもりです。こうした、「元データに遡った深掘り分析が簡単な操作で行える」点が、実はSPSSの最大の特徴なのかもしれないと、今回の記事執筆を通じて感じた次第です。
Modeler詰将棋!次回のTipsから出題
次の2つの例題にチャレンジしてみてください。Modeler TipsのIBM運営者によれば賞品は一切ないものの、正解すると名誉と自信がもれなくついてくるそうです。
例題1:「定義に従って休眠者にフラグを立てる」
取引データの日付の最大値を現在と仮定し、顧客リスト90日以上購買がなかった休眠者フラグを立ててください。出力フィールドは顧客ID休眠フラグの2フィールドのみで、入力と出力の間には3ノードのみの3手詰めです。ヒントは、その3手に直接含まれない重要な捨て駒が活躍します。

例題データ
東京図書様に許可をいただき「実践IBM SPSS Modeler~顧客価値を引き上げるアナリティクス」の紹介ページにあるダウンロードサンプルデータ「sampletranDEPT2015.csv」を利用いただけます。
例題2:「顧客が休眠直前に購入した商品を特定する」
例題1と同じデータを使い、休眠者が休眠する前の最後の来店で購入した商品(PRODUCT)の上位5つをリストしてください。入力と出力の間には7つのノードを使う7手詰めです。

次回のTips#22は日立ソリューションズ東日本の及川さんが執筆されます。
休眠防止はマーケティング上、極めて重要な施策ですのでどんな内容なのか楽しみです。

赤石 雅典
アクセンチュア株式会社
ビジネス コンサルティング本部AIグループ
シニア・プリンシパル

データ分析者達の教訓 #22- 予測モデルはビジネスの文脈で語られ初めてインパクトを持つ
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの坂本です。 SPSSを含むデータサイエンス製品の技術を担当しています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、データ活用を ...続きを読む
データ分析者達の教訓 #21- 異常検知には異常を識別する「データと対象への理解」が必要
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
皆さんこんにちは。IBMの宮園です。IBM Data&AIでデータサイエンスTech Salesをしています。 このリレー連載ブログはSPSS Modelerの実際のユーザーで第一線で活躍するデータ分析者に、デー ...続きを読む

【予約開始】「SPSS秋のユーザーイベント2024」が11月27日にオンサイト開催
Data Science and AI, SPSS Modeler ヒモトク, アナリティクス...
本年6月800名を超える方々にオンライン参加いただいたSPSS春のユーザーイベントに続き、『秋のSPSSユーザーイベント』を11月27日に雅叙園東京ホテルにて現地開催する運びとなりました。 このイベントは ...続きを読む